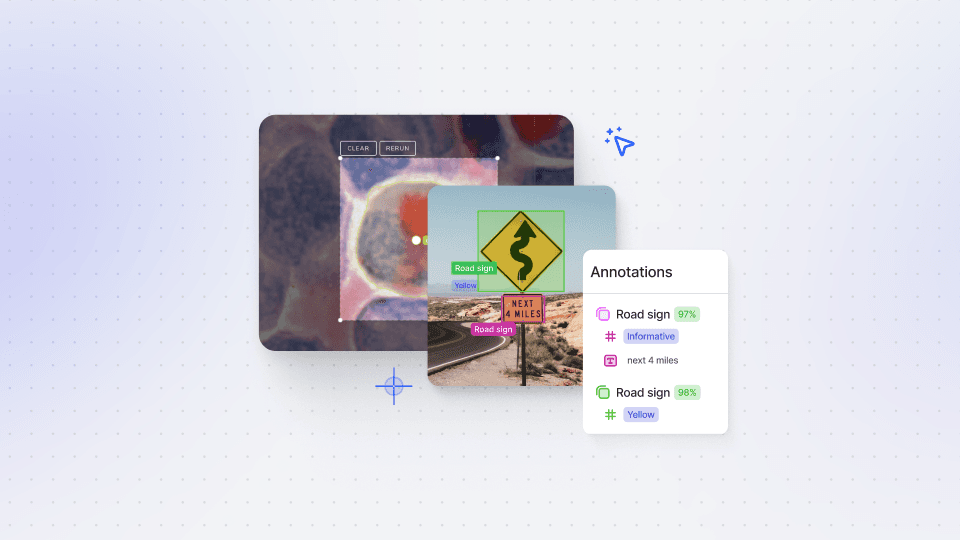
PyTorch Dataloaders

Play video
11:27
In this Darwin Advanced session, we explore how to leverage V7's Darwin Torch API to seamlessly create PyTorch DataLoaders from your V7 datasets. While V7 excels at annotation and dataset management, the SDK and API unlock additional powerful capabilities for machine learning workflows.
We begin with a practical demonstration using a "bird species dataset" which contains instance segmentation polygons across 1,909 labels and 3 classes. Using the command line interface, we show how to export and access your dataset efficiently.
The tutorial walks through the straightforward process of creating DataLoaders using the Darwin Torch API. With just a few lines of code, you'll learn how to specify your dataset ID, define dataset types, and access your data for machine learning applications. We demonstrate how to view dataset statistics and examine individual images within your dataset.
We then dive into creating data partitions - a crucial step in machine learning workflows. Using V7's command line interface, we show how to split your dataset into training (70%), validation (10%), and testing (20%) sets, with both random and stratified splitting options available. The tutorial covers how to apply transformations to your training data using the Darwin transforms API, including techniques like random horizontal flips and tensor conversions.
Finally, we put everything together in a complete PyTorch training example using a Mask R-CNN model from TorchVision. The demonstration includes setting up the model architecture, configuring optimizers, and implementing a basic training loop.
By the end of this video, you'll understand how to seamlessly integrate V7 datasets into your PyTorch workflows, combining V7's powerful dataset management capabilities with the flexibility of PyTorch for model training.