LLMs
19 min read
—
Mar 20, 2025


Guest Author
AI can automate up to 46% of tasks in document-heavy professions. Yet, many businesses fail to fully capitalize on this potential.
So, what is the main obstacle?
AI tools often lack the context needed to handle complex, organization-specific workflows and nuanced data. Language models—such as GPT—despite their sophistication, face a critical limitation: they can only work with what they've been trained on. They're like brilliant consultants who can't access your company's internal knowledge base.
Most organizations still struggle to make their AI systems truly understand their unique processes and internal documents.
This is where Retrieval-Augmented Generation (RAG) changes everything. By combining the ability to retrieve specific information with the power to generate intelligent responses, RAG enables AI to tap into your organization's unique knowledge ecosystem while maintaining the analytical capabilities of advanced language models.
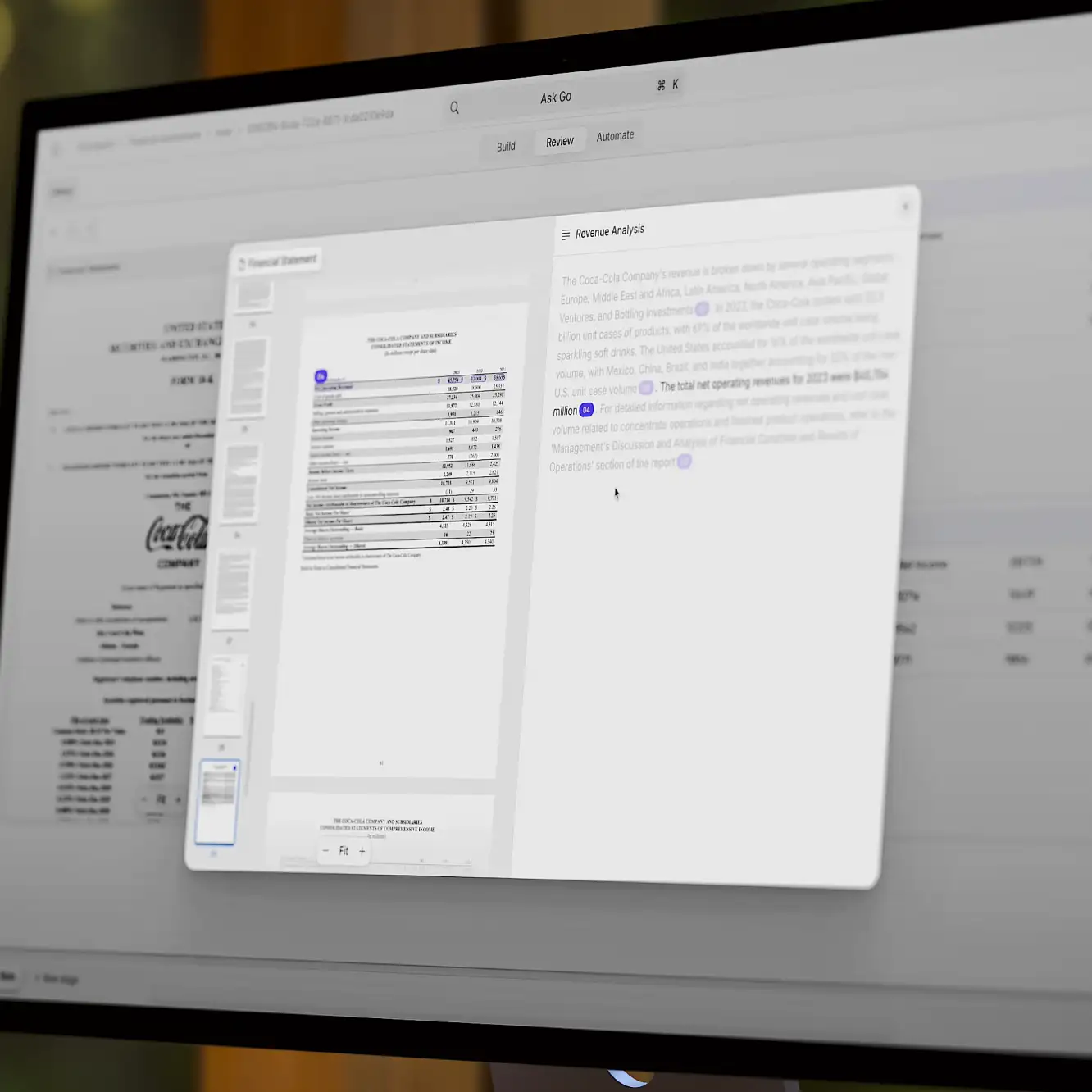
RAG offers significant advantages for business applications, particularly in document processing, data extraction, and information synthesis. By integrating RAG with existing technologies such as Optical Character Recognition (OCR) and Intelligent Document Processing (IDP), platforms like V7 Go enhance how companies manage complex document workflows. This integration improves operational efficiency while providing businesses with the capability to adapt to evolving information requirements.
As we delve deeper into the world of RAG, this blog will explore its mechanisms, key use cases, and implementation strategies. Specifically, we will look into:
What is RAG and how exactly does it work?
Key Use Cases
An implementation guide for RAG for your specific case
What is the best RAG software out there?
What is Retrieval Augmented Generation?
Let's be honest—traditional GenAI models aren't perfect. They can hallucinate, fabricate information, and sometimes confidently state things that simply aren't true. RAG takes a different approach, and while it's not a silver bullet, it addresses these limitations in several important ways.
Think of regular GenAI as a brilliant but isolated "robot" scholar, working solely from memorized knowledge. RAG, on the other hand, is like giving this scholar a vast, constantly updated library and the ability to fact-check in real-time.
This AI scholar knows a lot because it has read many books, but sometimes it needs more information to answer tricky questions. That's where Retrieval-Augmented Generation (RAG) comes in!
Here's how RAG works:
The AI's Brain: The AI already has a big brain filled with knowledge from all the books it has read. This is like a library inside its head.
Finding New Books: When the AI scholar doesn't know the answer to a question, it uses a special tool called a “retriever.” This tool helps it find new books or articles that have the information it needs.
Combining Knowledge: Once the AI finds these new books, it reads them quickly and combines what it learns with what it already knows. This way, it can give you a better answer.
Answering Questions: With all this new and old knowledge mixed together, the AI model can now answer your question much more accurately!
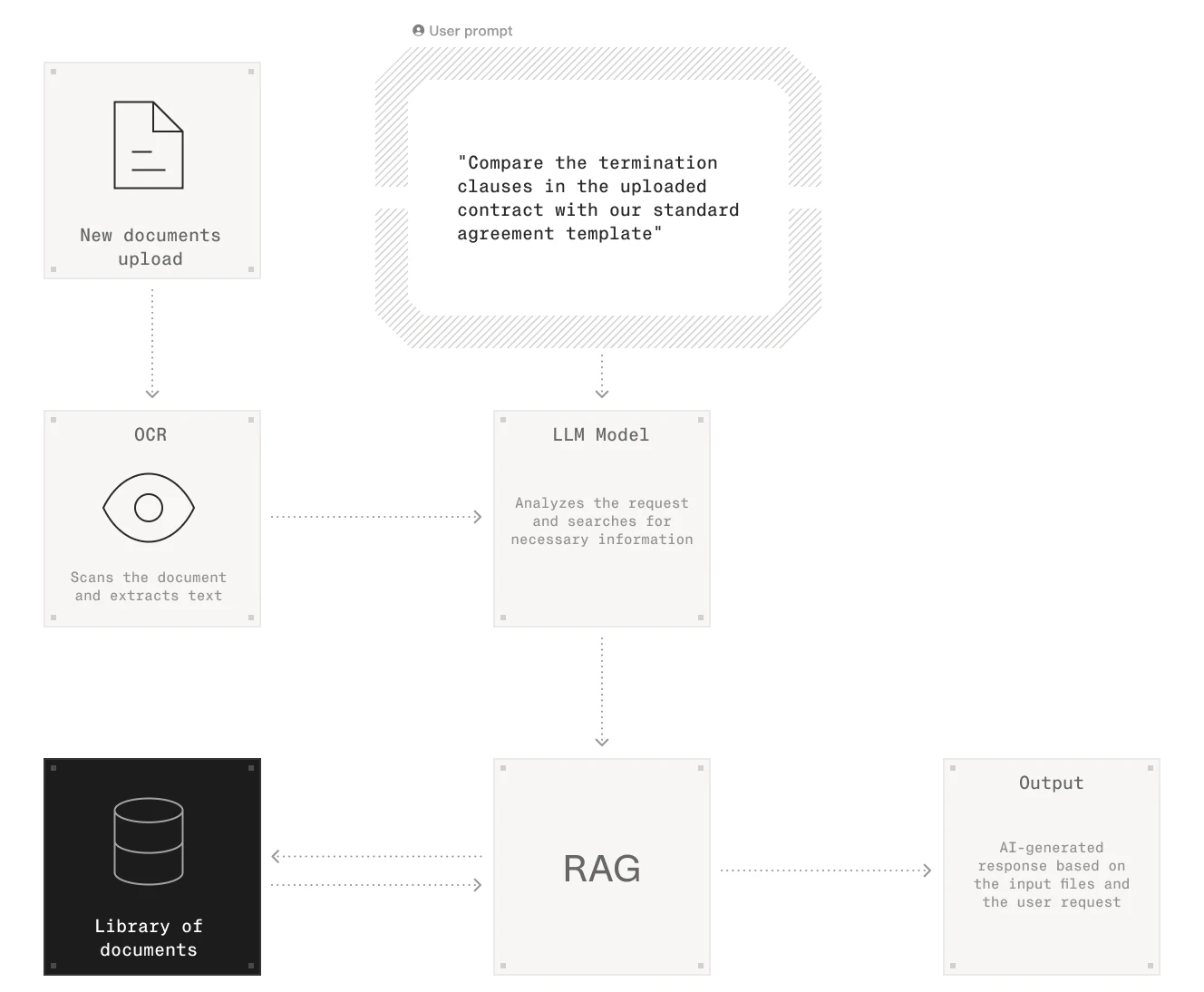
For businesses, this means they can use RAG to help their own smart AI systems do things like:
Review Contracts: Quickly find and understand important parts of legal documents.
Search Documents: Easily look through lots of files to find specific information.
Compare Documents: Check for differences between two versions of a document.
Summarize Reports: Generate high-level overview based on key information extracted.
So, RAG is like giving your robot a superpower to find and use the most up-to-date information, making it even smarter and more helpful!
Some AI systems can leverage RAG functionality, while others are limited to generating answers based solely on their existing training. Typically, RAG capabilities can be combined with other technologies such as OCR, third-party platforms, specialized software, or storage solutions. For example, AI agents—advanced AI systems—can “plan ahead” and determine which tools and data sources are most relevant for a specific user query. RAG and AI web search engines are among the most important and powerful of these tools and capabilities.
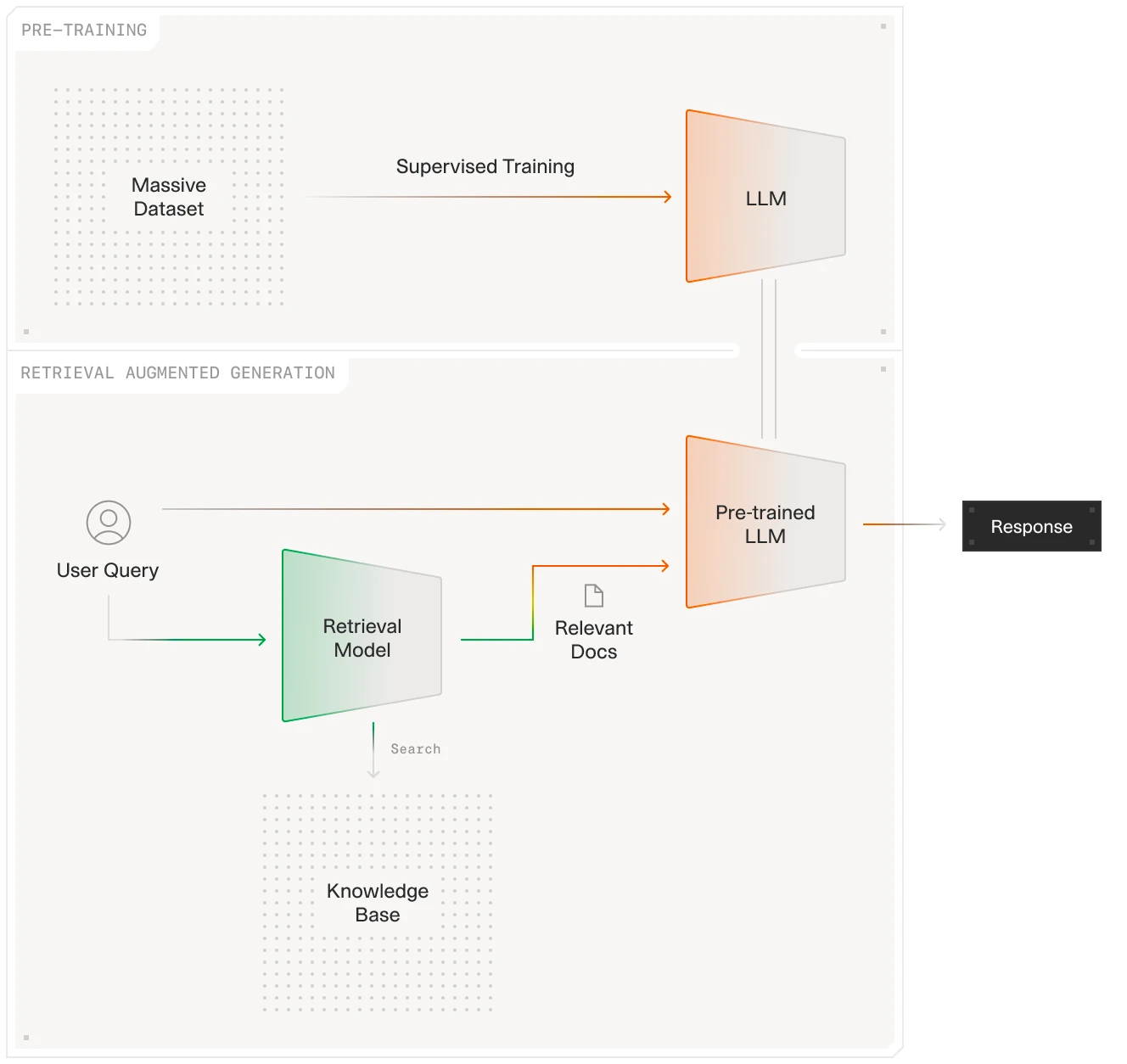
How does RAG work?
The key difference between regular LLMs and RAG lies in how RAG combines text generation with real-time information retrieval. Instead of relying solely on training data, RAG actively fetches information from trusted sources—whether that's your company's documentation, industry reports, or verified databases. This means when you ask a RAG-enabled system about your organization's latest quarterly results, it doesn't guess—it checks.
RAG, introduced by Facebook AI Research, combines the strengths of pre-trained language models with external information retrieval systems to enhance the generation of knowledge-intensive tasks. This hybrid model leverages both parametric and non-parametric memory components to improve the accuracy and relevance of AI-generated responses.
Key Components of RAG:
Query Encoding: The process begins with encoding the user's query into a numerical format using advanced language models like BERT or GPT. This transformation captures the semantic meaning of the query.
Retriever: The retrieval component, often implemented using a Dense Passage Retriever (DPR), is responsible for identifying relevant documents from an external knowledge base. This is done by encoding both the input query and potential document passages into dense vectors using a bi-encoder architecture based on BERT. The similarity between these vectors is then calculated to retrieve the top-K most relevant documents, which serve as additional context for the generation process.
Generator: The generator component, typically a sequence-to-sequence (seq2seq) model like BART, uses the retrieved documents along with the original input to generate the final output. The generator considers these documents as latent variables, which are marginalized over to produce a distribution of possible outputs.
Integration and Marginalization: RAG integrates these components into a unified framework where the retrieved documents are treated as latent variables. Two main approaches are used:
RAG-Sequence: Utilizes the same retrieved document for generating the entire sequence, marginalizing over possible document choices.
RAG-Token: Allows different documents to be used for generating each token in the sequence, providing flexibility in content selection and improving diversity in responses.
Training and Decoding:
Training: The retriever and generator are trained end-to-end without explicit supervision on which documents should be retrieved. This involves minimizing the negative marginal log-likelihood of target outputs using stochastic gradient descent.
Decoding: At inference time, RAG employs different decoding strategies for RAG-Sequence and RAG-Token models. RAG-Sequence uses beam search across all documents, while RAG-Token performs token-wise marginalization over retrieved documents.
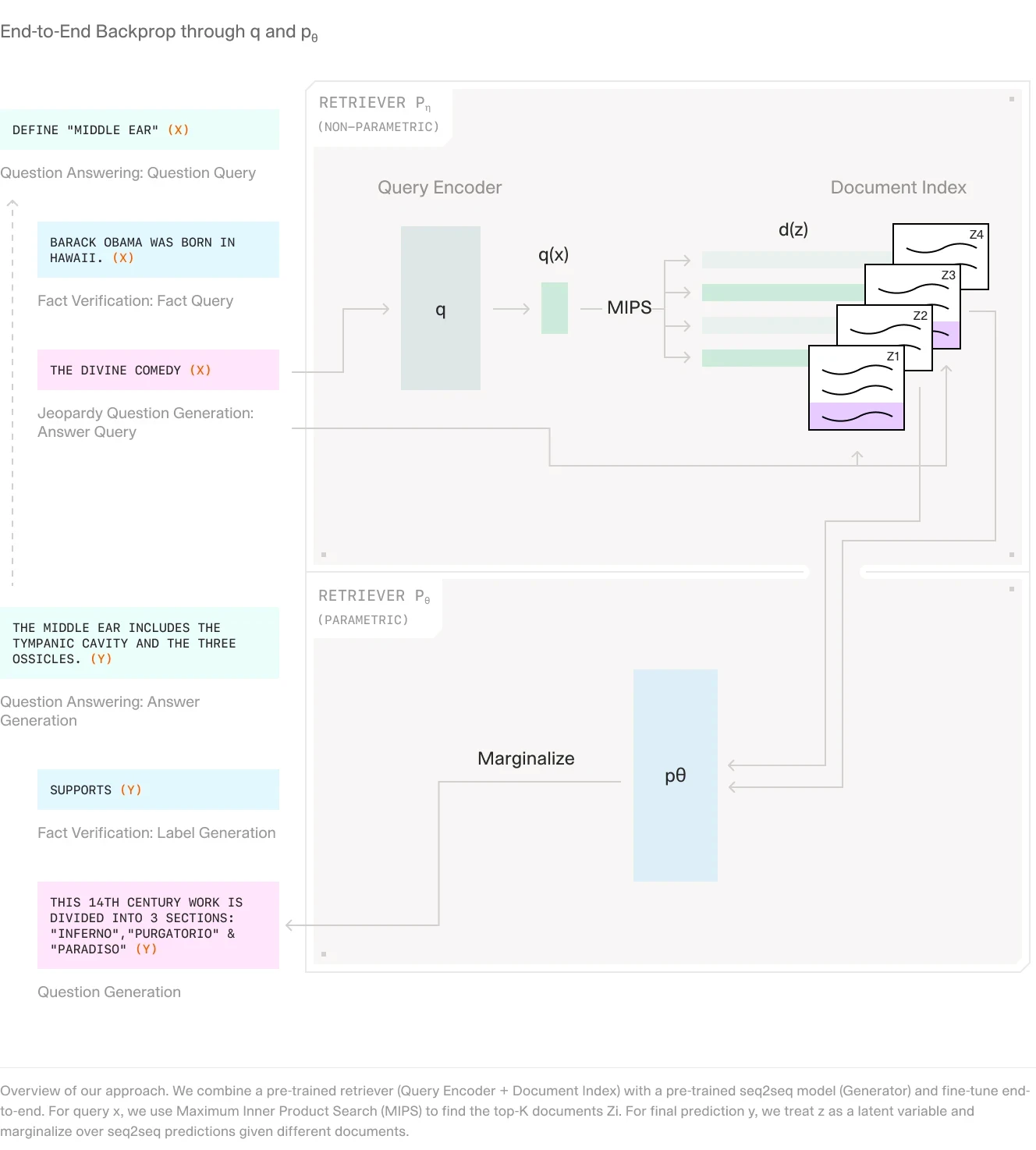
(Source)
This workflow is often visualized in platforms like V7 Go, which integrate RAG with other technologies such as Optical Character Recognition (OCR) and Intelligent Document Processing (IDP). By combining these technologies, V7 Go enhances capabilities in document automation and analysis, providing a comprehensive solution for businesses looking to streamline complex workflows.
What is RAG used for?
RAG's ability to dynamically incorporate external information makes it particularly effective for tasks requiring up-to-date knowledge or domain-specific expertise. It addresses limitations of static language models by allowing real-time updates to its knowledge base through non-parametric memory, which can be easily modified without retraining the entire model.






Some common applications include:
Customer Support: Enhancing chatbots and virtual assistants by providing accurate, up-to-date responses based on real-time data.
Legal Document Analysis: Automating contract reviews by retrieving relevant legal precedents and clauses.
Financial Services: Analyzing market trends and portfolio data rooms with current financial information.
Healthcare: Assisting in medical diagnostics by accessing the latest research papers and clinical guidelines.
Is RAG better than fine-tuning?
When comparing RAG and traditional fine-tuning for enhancing LLMs, it's essential to recognize that each approach has its strengths and hinges on the specific needs of the task at hand.
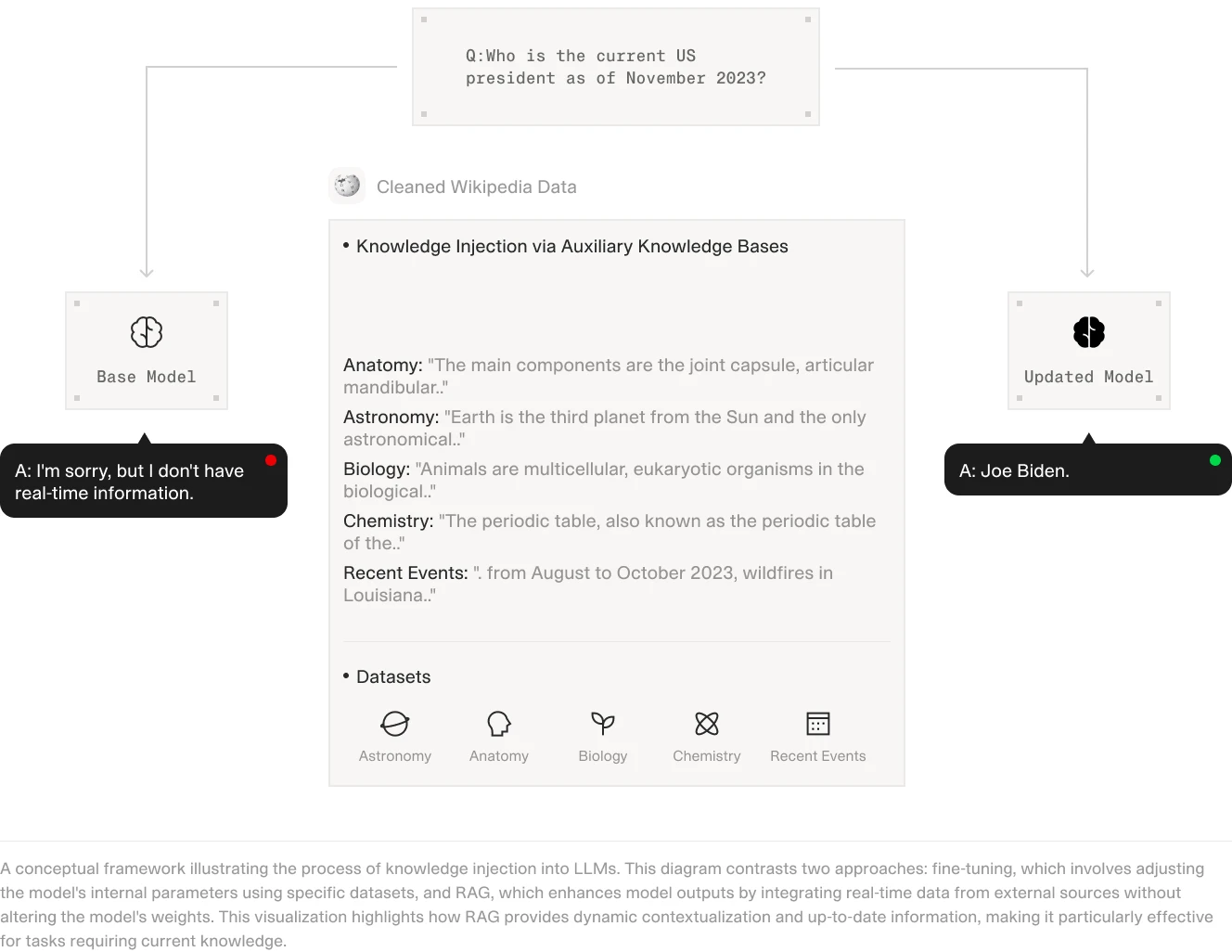
(Source)
When RAG is Better:
Dynamic Knowledge Access: RAG is particularly effective for tasks requiring access to the most current and diverse information. It excels in environments where information changes rapidly, such as news aggregation or real-time customer support. By retrieving data from external sources, RAG ensures that the AI's responses are based on the latest available information, which is crucial for applications like financial market analysis or legal updates.
Broad Domain Coverage: RAG is ideal for applications that span multiple domains or require integration of various data types. For instance, in customer service chatbots, RAG can pull relevant information from product manuals, FAQs, and user forums to provide comprehensive answers without needing domain-specific training.
Cost Efficiency: Implementing RAG can be more cost-effective than fine-tuning because it avoids the need for retraining models with new datasets. This is particularly beneficial for businesses that need to maintain AI systems with minimal operational costs while ensuring up-to-date responses.
Avoidance of Catastrophic Forgetting: As highlighted in the study by Ovadia, fine-tuning can sometimes lead to catastrophic forgetting, where a model loses previously acquired knowledge. RAG mitigates this risk by not altering the model's weights during knowledge retrieval, maintaining its original capabilities while enhancing its output with external data.
When Fine-Tuning is Better:
Domain-Specific Expertise: Fine-tuning is more suitable for tasks requiring deep expertise in a specific domain. By training a model on a specialized dataset, fine-tuning enhances the model's ability to understand and generate content specific to that domain. This approach is beneficial in fields like healthcare diagnostics or legal document analysis, where precise and accurate domain knowledge is critical.
Consistency and Precision: In scenarios where consistency and precision are paramount, such as scientific research or technical documentation, fine-tuning ensures that the model is trained on highly curated data, leading to more reliable outputs.
Controlled Outputs: Fine-tuning allows for greater control over the model's behavior and outputs, which is crucial in applications where adherence to specific guidelines or styles is necessary, such as brand-specific marketing content or educational materials.
Improved Reasoning Capabilities: While RAG excels at providing factual information, fine-tuning can enhance a model's reasoning abilities by exposing it to structured learning scenarios. This can be particularly useful in complex decision-making processes where logical reasoning based on existing knowledge is required.
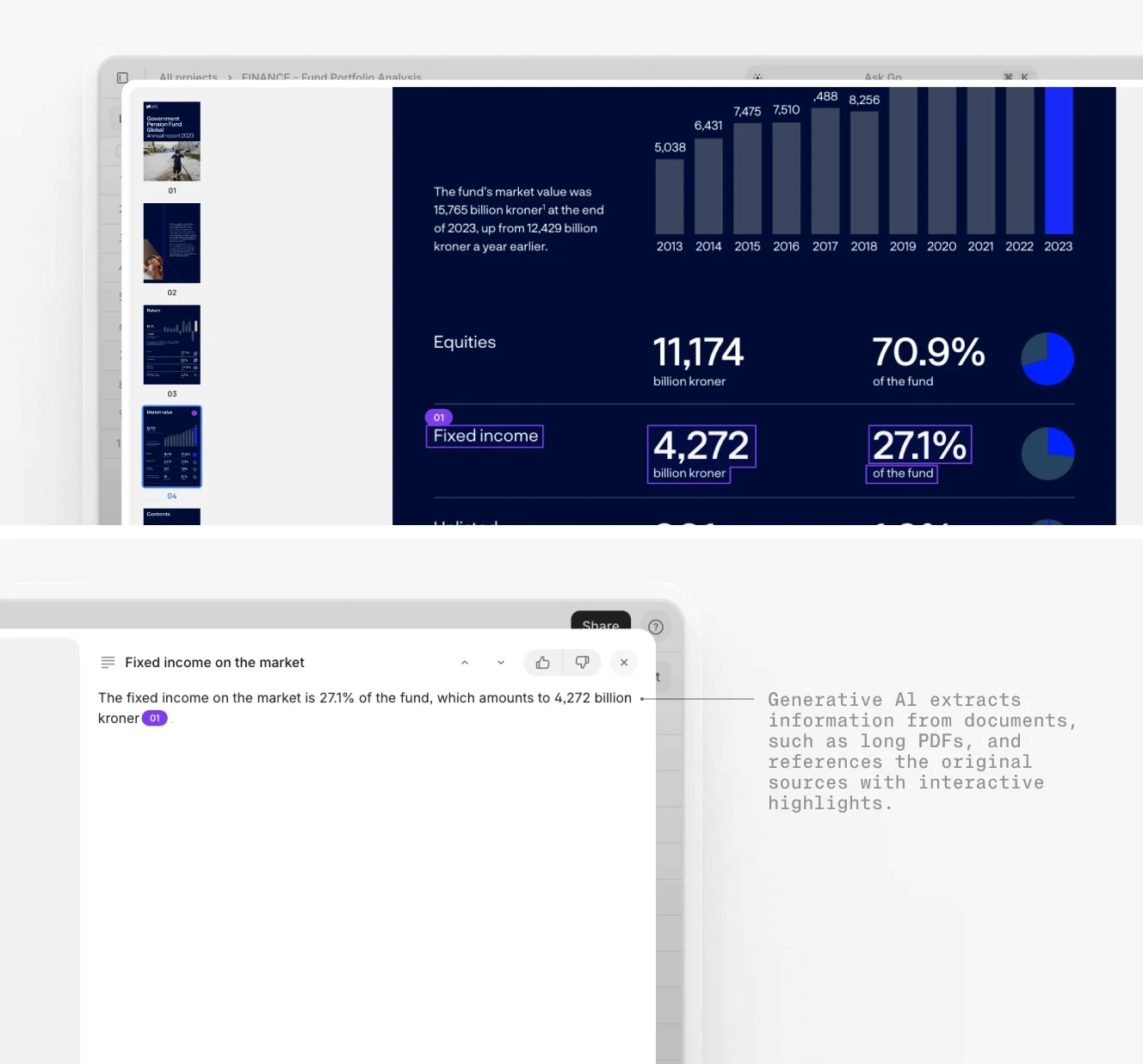
Key use cases for RAG
RAG’s ability to dynamically retrieve and utilize external information makes it particularly valuable across various business applications, especially in document-intensive industries. Here are some of the most important use cases for RAG:
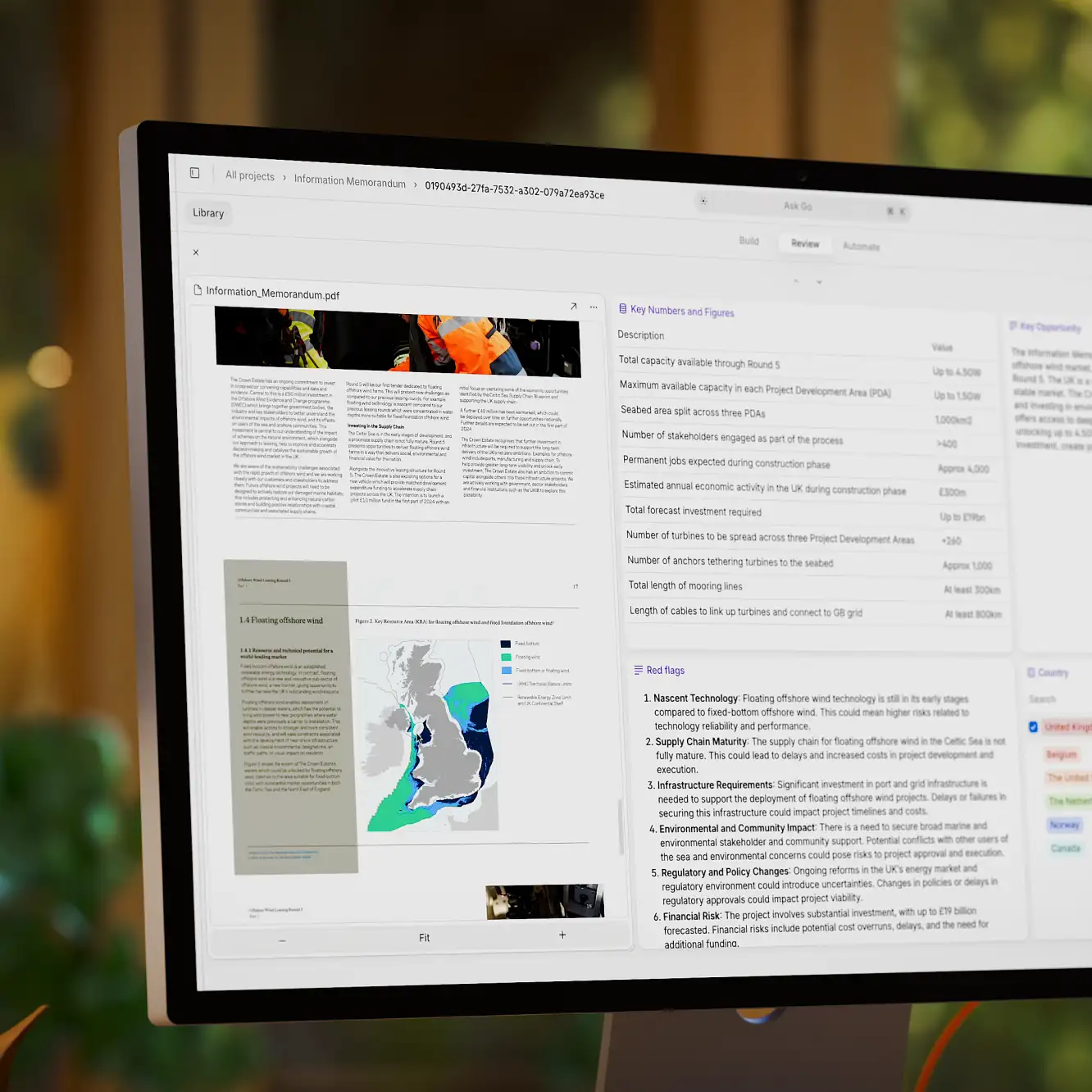
AI Contract Reviews: In the legal industry, RAG can automate the review of contracts by extracting key clauses, comparing terms against previous agreements, and ensuring compliance with regulations. Platforms like V7 Go leverage RAG to streamline these processes, drastically reducing the time and effort required for manual reviews. This not only enhances efficiency but also mitigates risks associated with human error.
For example, High-Precision-Contract-Advisor-RAG is a tool that leverages RAG to create a conversational interface for contract-related inquiries, allowing users to ask questions about contracts and receive relevant answers. It utilizes frameworks like Langchain and Azure Rag to enhance contract Q&A interactions, aiming to develop a fully autonomous contract assistant capable of handling tasks such as drafting, reviewing, and negotiation independentlyDocument Search and Data Extraction: RAG excels in searching and extracting data from large document repositories. It enables instant retrieval of specific clauses or information from thousands of contracts or legal documents, significantly cutting down review times. This capability is crucial for legal teams that need to quickly access relevant information across diverse document types.
For example, Azure AI Search combined with RAG enables complex data extraction from unstructured documents by leveraging LLMs to interpret and query document content effectively. Azure AI Search utilizes RAG to retrieve relevant information from large datasets, enhancing the accuracy and efficiency of document querying processes. A step-by-step approach for how Azure AI Search does this is outlined in this blog.Document Redlining and AI Due Diligence: By integrating RAG, businesses can automate the redlining process, highlighting changes or discrepancies in documents. This is particularly useful during due diligence processes, where identifying alterations and ensuring accuracy is critical.
For example, Intralinks is a platform that enhances document redlining and due diligence processes by providing secure virtual data rooms and AI-driven tools that streamline document analysis, comparison, and redaction, ensuring efficiency and accuracy in complex financial transactions.Document Comparison: RAG facilitates efficient document comparison by retrieving relevant sections from different versions of a document and generating a comprehensive analysis. This helps organizations maintain consistency and accuracy in their documentation practices.
For example, the LangChain Document Comparison Toolkit utilizes RAG to facilitate the comparison of two documents by creating a question-answering chain for each document. It employs vector stores to retrieve semantically similar document chunks, allowing for detailed analysis and comparison based on the content retrieved and processed by language models.Finance and Portfolio Dataroom Analysis: In the financial sector, RAG can be used to analyze portfolio datarooms by retrieving up-to-date market data and financial reports. This allows for more informed decision-making and strategic planning.
HyDE is a recent paper that explores how RAG can enhance the performance of LLMs in financial analysis. It addresses the limitations of traditional RAG pipelines, such as suboptimal text chunk retrieval, and introduces advanced methodologies to improve text retrieval quality. Key strategies include sophisticated chunking techniques, query expansion, metadata annotations, re-ranking algorithms, and fine-tuning of embedding algorithms. These improvements aim to enhance the accuracy and reliability of LLMs in processing financial documents, making RAG a powerful tool for tasks like earnings report analysis and market trend predictions.
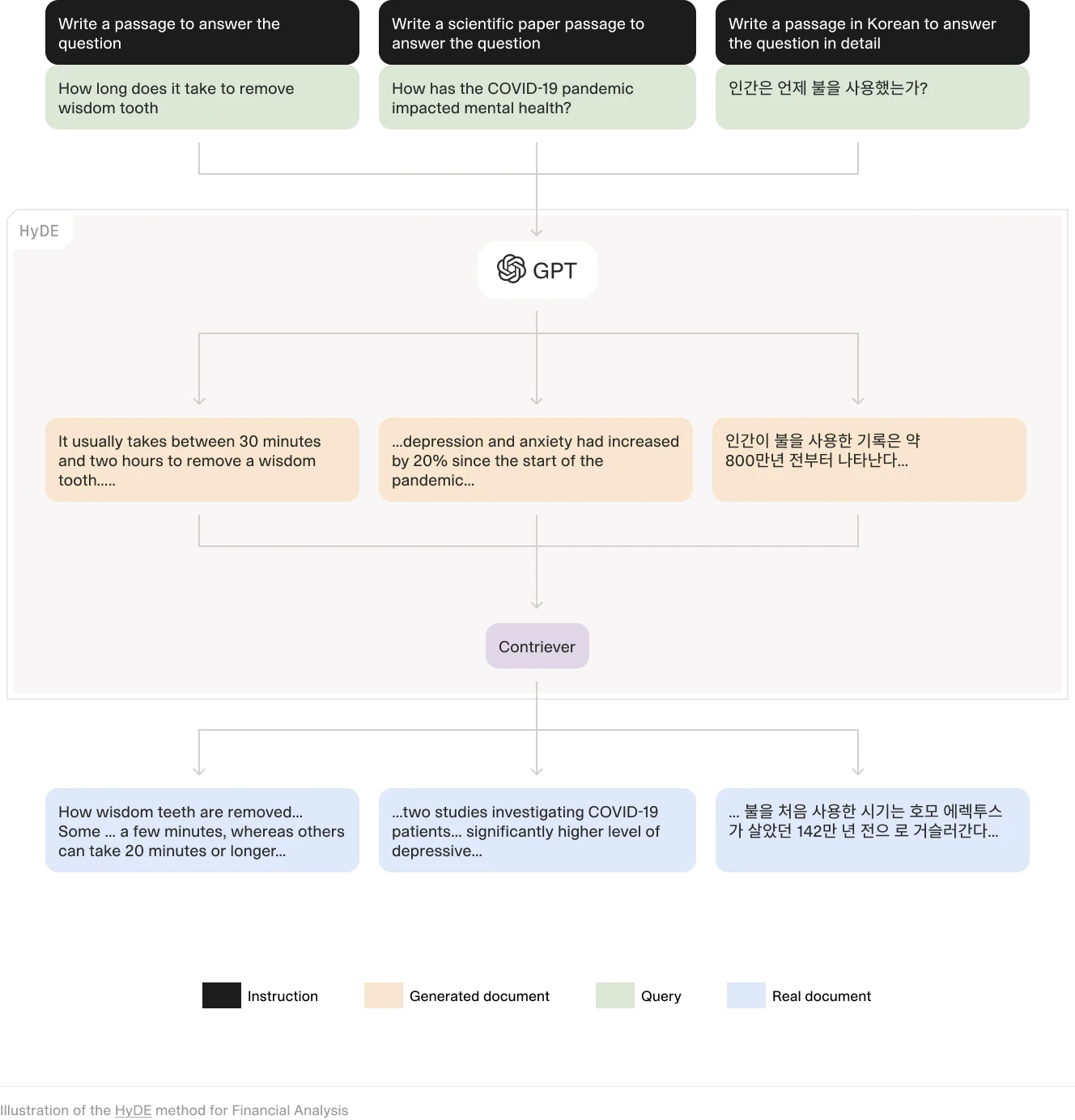
(HyDE method for Financial Analysis)
These use cases demonstrate how RAG can transform business operations by providing precise, timely, and contextually relevant information. By leveraging the power of RAG, organizations can improve their efficiency, reduce costs associated with manual data processing, and enhance their decision-making capabilities across various domains.
RAG implementation guide
Companies should consider implementing RAG in scenarios where accuracy and real-time data access are critical. This includes:
Legal Document Comparison: Ensuring precise analysis of legal documents by retrieving relevant case law and statutes.
Business Data Analysis: Enhancing decision-making processes by accessing the latest market trends and business intelligence.
Generating Financial Reports: Utilizing up-to-date financial data to produce accurate reports and forecasts through AI financial statement analysis.
Analyzing Medical Records: Integrating the latest medical research and patient data for improved diagnostics and treatment plans.
In these contexts, RAG provides a dynamic approach to information retrieval, allowing businesses to maintain high standards of accuracy and relevance.
Several frameworks support the implementation of RAG, each offering unique features:
V7 Go Index Knowledge: This framework integrates RAG with advanced indexing capabilities, making it ideal for document-intensive workflows. V7 Go enhances document processing by combining RAG with Optical Character Recognition (OCR) and Intelligent Document Processing (IDP) technologies, streamlining complex document workflows.
AWS RAG: Amazon Web Services provides scalable cloud-based solutions for integrating RAG into existing AWS ecosystems. AWS's robust infrastructure supports large-scale deployments, ensuring that businesses can efficiently manage and process vast amounts of data.
Pinecone RAG: Pinecone offers a leading vector database that enhances the speed and accuracy of RAG processes. It allows integration of embeddings from any model, providing flexibility in choosing the best fit for specific applications. Pinecone's platform is designed to handle large-scale AI workloads, making it suitable for enterprise-level implementations.
Even OpenAI supports the implementation of RAG through platforms like Azure OpenAI Service. This allows users to connect GPT models to custom data sources or knowledge bases. Additionally, tools like V7 Go Library offer integration with GPT models, facilitating the use of RAG in various applications without extensive retraining.
How to Set Up a RAG Workflow
Setting up a RAG workflow involves several key steps that integrate data retrieval with generative AI models to enhance the accuracy and relevance of the outputs.
Method 1: Out-of-the-box solution
V7 Go offers a streamlined and user-friendly way to implement RAG without needing extensive technical expertise. Here’s how it operates:
Document Upload: Simply upload your documents, such as PDFs or text files, to the V7 Go platform. These could be contracts, reports, or any other text-based files. The system is designed to handle various document types and sizes efficiently.
Query Input: Write your question or query related to the document content. V7 Go uses RAG behind the scenes, so you don’t need to manually configure retrieval settings.
Automated Analysis: The platform automatically processes the documents using RAG, retrieving relevant information and generating responses based on both the document content and pre-trained model knowledge.
Response Generation: V7 Go provides answers or extracts data, ensuring that outputs are accurate and contextually relevant, thanks to its integration with advanced AI technologies.
This approach is ideal for businesses looking for an easy-to-implement solution that automates the complexities of RAG in the background, allowing them to focus on leveraging AI insights without delving into technical details.
Here’s a detailed guide to setting up a RAG pipeline on your own, versus, using tools like V7 Go that does the heavy lifting for you automatically:
Method 2: Custom setup
Step 1: Data Preparation
Document Collection: Gather all relevant documents that will serve as the knowledge base. These could be financial reports, legal documents, or any other domain-specific texts.
Data Preprocessing: Convert these documents into a machine-readable format. This might involve cleaning the text, removing unnecessary metadata, and structuring the data for efficient processing.
Step 2: Embedding Generation
Text Embedding: Use a language model to convert text chunks into embeddings, which are numerical representations of the text. This step captures the semantic meaning of the text, enabling effective retrieval.
Chunking Strategy: Implement an effective chunking strategy to divide documents into manageable pieces. Techniques such as recursive or semantic chunking can help maintain context and relevance in each chunk.
Step 3: Indexing
Vector Database Setup: Store the generated embeddings in a vector database like Pinecone or FAISS. This database will facilitate quick retrieval of relevant text chunks based on similarity searches.
Metadata Annotations: Enhance retrieval accuracy by adding metadata annotations to each chunk. This can include document type, date, or other contextual information that aids in precise retrieval.
Step 4: Retrieval Configuration
Query Processing: When a user query is received, convert it into an embedding using the same model used for document embeddings.
Similarity Search: Perform a similarity search between the query embedding and document embeddings in the vector database to identify relevant chunks.
Re-ranking Algorithms: Use re-ranking algorithms to prioritize retrieved chunks based on their relevance to the query, ensuring that the most pertinent information is used for generation.
Step 5: Integration with LLMs
Augmenting Queries: Combine the retrieved text chunks with the original user query to form an augmented input for the language model.
Response Generation: Feed this augmented input into an LLM to generate responses that incorporate both pre-trained knowledge and real-time data from retrieved documents.
By following these steps, businesses can set up a robust RAG pipeline that enhances their AI systems' ability to deliver accurate and contextually relevant information across various applications. This setup not only improves decision-making processes but also ensures that AI outputs are grounded in reliable data sources.
What is the best RAG software?
When it comes to implementing RAG effectively, choosing the right software can significantly impact the performance and scalability of your AI applications. Here are some leading platforms that offer robust RAG capabilities:
V7 Go
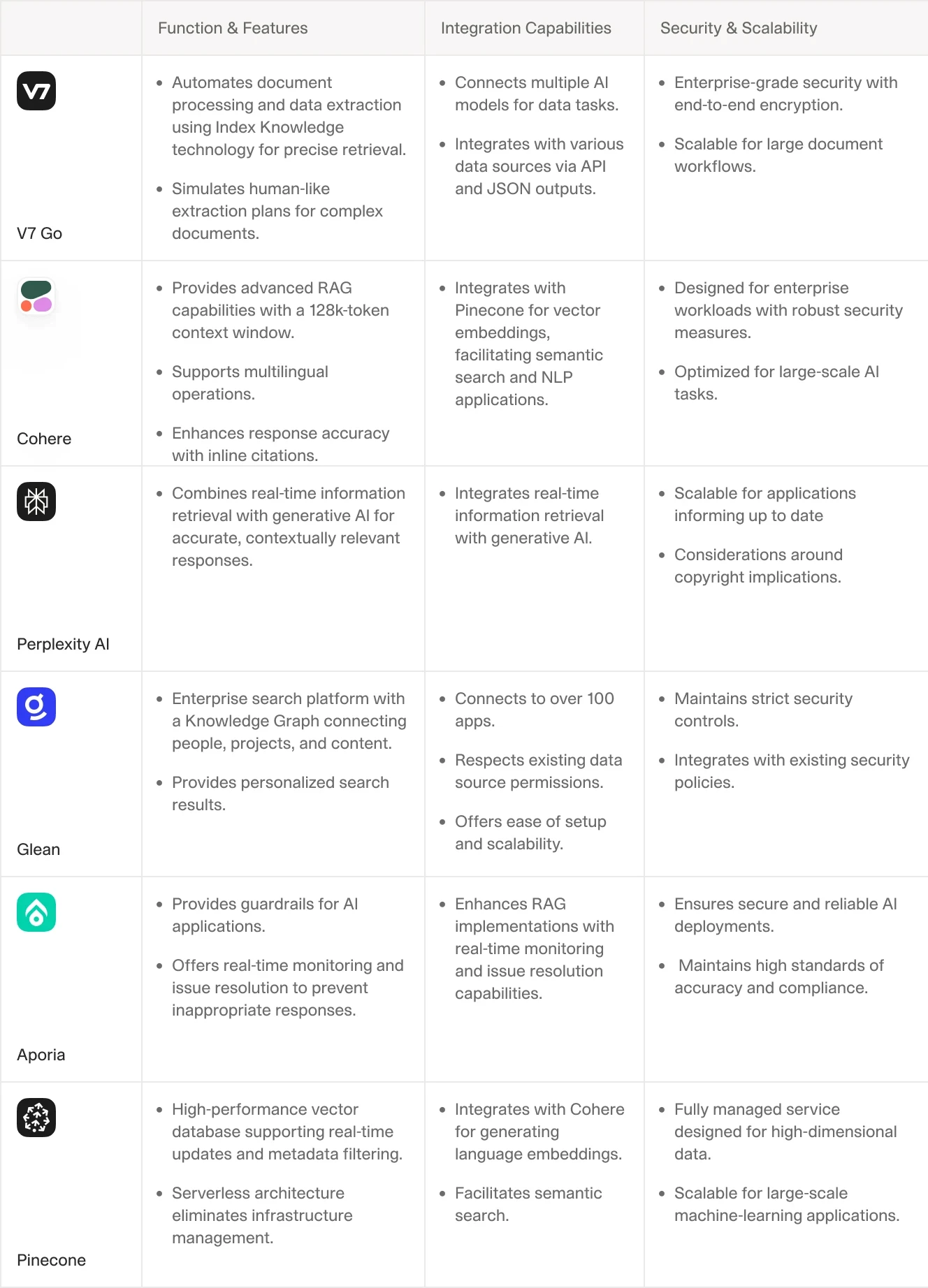
V7 Go is a comprehensive work automation platform that excels in document processing and data extraction. It leverages Index Knowledge technology to break down large files into small, searchable indexes, allowing for precise information retrieval. This approach surpasses traditional RAG techniques by simulating human-like data extraction plans, making it particularly effective for handling complex documents with numeric data and uncommon terms.
Cohere
Cohere offers advanced RAG capabilities through its Command R+ model, which is optimized for enterprise-grade workloads. This model provides a 128k-token context window and supports multilingual operations, making it ideal for businesses looking to integrate AI across various functions such as finance, HR, and marketing. Cohere's RAG solution improves response accuracy and includes in-line citations to mitigate hallucinations, enhancing the reliability of AI outputs.
Perplexity AI
Perplexity AI utilizes RAG to combine real-time information retrieval with generative AI, enabling LLMs to generate accurate and contextually relevant responses. This approach is particularly useful in applications requiring up-to-date information, although it has sparked discussions around copyright implications due to its method of retrieving external content.
Glean
Glean integrates RAG into its enterprise search platform, offering a sophisticated Knowledge Graph that connects people, projects, and content across an organization. This system ensures that AI responses are grounded in real-time company data, reducing the risk of outdated information. Glean's RAG-based architecture maintains strict security controls while providing personalized search results tailored to user roles and interactions.
Aporia
Aporia specializes in providing guardrails for AI applications, ensuring secure and reliable deployments. While not a traditional RAG platform, Aporia enhances RAG implementations by offering real-time monitoring and issue resolution capabilities. Its system is designed to prevent inappropriate responses and maintain high standards of accuracy and compliance.
Pinecone
Pinecone offers a high-performance vector database that enhances the speed and accuracy of RAG processes. It supports real-time updates and metadata filtering, making it an ideal choice for applications requiring dynamic data retrieval. Pinecone's serverless architecture eliminates infrastructure management concerns, providing a scalable solution for large-scale AI tasks.
Each of these platforms brings unique strengths to the table, allowing businesses to tailor their RAG implementations to meet specific needs and optimize their AI workflows effectively.
Conclusion
As we wrap up our journey through the world of RAG, I have to admit—even after years of working with AI, I'm still amazed at how this technology continues to evolve. And trust me, I've had my fair share of "that'll never work" moments that RAG proved wrong.
RAG represents a significant leap forward in the capabilities of LLMs, particularly in business contexts where precision and real-time data access are crucial. By integrating external information retrieval with generative AI, RAG addresses the inherent limitations of static LLMs, such as outdated knowledge and lack of domain specificity. This powerful combination enables businesses to harness AI for complex tasks like document processing, financial analysis, and legal reviews, going beyond what LLMs can achieve on their own.
Throughout this blog, we have explored the diverse applications of RAG across various industries, highlighting its ability to transform business operations by providing accurate and contextually relevant information. The implementation of RAG through robust frameworks like V7 Go, AWS RAG, and Pinecone offers scalable solutions that cater to diverse organizational needs, ensuring that AI systems remain competitive and effective.
As technology continues to evolve, the adoption of RAG is poised to expand further, driven by its potential to enhance decision-making processes and streamline complex workflows. By leveraging the power of RAG, businesses can optimize their AI strategies and gain a competitive edge in an increasingly data-driven world. Embracing innovations like RAG will be essential for organizations aiming to fully realize the potential of AI in their operations.