AI implementation
Multimodal Deep Learning: Definition, Examples, Applications
18 min read
—
Dec 15, 2022
Learn how multimodal deep learning works. See the challenges of using multimodal datasets, and how deep learning models process multimodal inputs.

Guest Author
Humans use five senses to experience and interpret the world around them. Our five senses capture information from five different sources, and five different modalities. A modality refers to the way in which something happens, is experienced, or captured. AI is on a quest to mimic the human brain.
Human brains consist of neural networks that can process multiple modalities simultaneously. Imagine having a conversation—your brain’s neural networks process multimodal inputs (audio, vision, text, odors). After a deep subconscious modality fusion, you can reason about what your interlocutor is saying, their emotional state, and your/their surroundings. This allows for a more holistic view and deeper comprehension of the situation.
For artificial intelligence to match human intelligence, it's imperative that it learns to interpret, reason, and fuse multimodal information. One of the latest and most promising trends in Deep Learning research is Multimodal Deep Learning. In this article, we demystify multimodal deep learning. We discuss multimodal fusion, multimodal datasets, multimodal applications, and explain how machine learning models that perceive the world more holistically are built.
Here’s what we’ll cover:
What is Multimodal Deep Learning
Multimodal Learning Challenges
How Multimodal Learning works
Five Multimodal Deep Learning applications
Ready to streamline AI product deployment right away? Check out:
What is Multimodal Deep Learning
Multimodal machine learning is the study of computer algorithms that learn and improve performance through the use of multimodal datasets.
Multimodal Deep Learning is a machine learning subfield that aims to train AI models to process and find relationships between different types of data (modalities)—typically, images, video, audio, and text. By combining different modalities, a deep learning model can comprehend its environment more universally since some cues exist only in certain modalities. Imagine the task of emotion recognition. There is more to it than just looking at a human face (visual modality). The tone and pitch of a person’s voice (audio modality) encode enormous amounts of information about their emotional state, which might not be visible through their facial expressions, even if they are often in sync.
Unimodal or Monomodal models, models that process only a single modality, have been researched to a great extent and have provided extraordinary results in advancing fields like computer vision and natural language processing. However, unimodal deep learning has limited capabilities, so the need for multimodal models arises. The image below is an example of how unimodal models fail in some tasks, like recognizing sarcasm or hate speech. The figure is part of META’s multimodal dataset “Hateful Memes”.

Combining image and text to create a sarcastic meme. Unimodal models are unable to perceive such kind of sarcasm since each individual modality contains just half the information. In contrast, a multimodal model that processes both text and images can relate the two and discover the deeper meaning. (source)
Multimodal models, more often than not, rely on deep neural networks even though other machine learning models, such as hidden Markov models HMM or Restricted Boltzman Machines RBM have been incorporated in earlier research.
In multimodal deep learning, the most typical modalities are visual (images, videos), textual, and auditory (voice, sounds, music). However, other less typical modalities include 3D visual data, depth sensor data, and LiDAR data (typical in self-driving cars). In clinical practice, imaging modalities include computed tomography (CT) scans and X-ray images, while non-image modalities include electroencephalogram (EEG) data. Sensor data like thermal data or data from eye-tracking devices can also be included in the list.
Any combination of the above unimodal data results in a multimodal dataset. For example, combining
Video + LiDAR+ depth data creates an excellent dataset for self-driving car applications.
EEG + eye tracking device data, creates a multimodal dataset that connects eye movements with brain activity.
However, the most popular combinations are combinations of the three most popular modalities
Image + Text
Image + Audio
Image + Text + Audio
Text + Audio
Multimodal Learning Challenges
Multimodal deep learning aims to solve five core challenges that are active areas of research. Solutions or improvements on any of the below challenges will advance multimodal AI research and practice.
Representation
Multimodal representation is the task of encoding data from multiple modalities in the form of a vector or tensor. Good representations that capture semantic information of raw data are very important for the success of machine learning models. However, feature extraction from heterogeneous data in a way that exploits the synergies between them is very hard. Moreover, fully exploiting the complementarity of different modalities and not paying attention to redundant information is essential.
Multimodal representations fall into two categories.
1. Joint representation: each individual modality is encoded and then placed into a mutual high dimensional space. This is the most direct way and may work well when modalities are of similar nature.
2. Coordinated representation: each individual modality is encoded irrespective of one another, but their representations are then coordinated by imposing a restriction. For example, their linear projections should be maximally correlated
Fusion
Fusion is the task of joining information from two or more modalities to perform a prediction task. Effective fusion of multiple modalities, such as video, speech, and text, is challenging due to the heterogeneous nature of multimodal data.
Fusing heterogeneous information is the core of multimodal research but comes with a big set of challenges. Practical challenges involve solving problems such as different formats, different lengths, and non-synchronized data. Theoretical challenges involve finding the most optimal fusion technique. Options include simple operations such as concatenation or weighted sum, and more sophisticated attention mechanisms such as transformer networks, or attention-based recurrent neural networks (RNNs).
Finally, one may also need to choose between early or late fusion. In early fusion, features are integrated immediately after feature extraction with some of the above fusion mechanisms. On the other hand, during late fusion, integration is performed only after each unimodal network outputs a prediction (classification, regression). Voting schemes, weighted averages, and other techniques or usually used on late fusion. Hybrid fusion techniques have also been proposed. These combine outputs from early fusion and unimodal predictors.
Alignment
Alignment refers to the task of identifying direct relationships between different modalities. Current research in multimodal learning aims to create modality-invariant representations. This means that when different modalities refer to a similar semantic concept, their representations must be similar/close together in a latent space. For example, the sentence “she dived into the pool”, an image of a pool, and the audio signal of a splash sound should lie close together in a manifold of the representation space.
Translation
Translating is the act of mapping one modality to another. The main idea is how one modality (e.g., textual modality) can be translated to another (e.g., visual modalities) while retaining the semantic meaning. Translations, however, are open-ended, subjective, and no perfect answer exists, which adds to the complexity of the task.
Part of the current research in multimodal learning is to construct generative models that make translations between different modalities. The recent DALL-E and other text-to-image models are great examples of such generative models that translate text modalities to visual modalities.
Read more: If you’re interested in the subject of using AI for creating works of art, read our article AI-Generated Art: From Text to Images & Beyond
Co-Learning
Multimodal Co-learning aims to transfer information learned through one or more modalities to tasks involving another. Co-learning is especially important in cases of low-resource target tasks, fully/partly missing or noisy modalities.
Translation—explained in the section above—may be used as a method of co-learning to transfer knowledge from one modality to another. Neuroscience suggests that humans may use methods of co-learning through translation, as well. People who suffer from aphantasia, the inability to create mental images in their heads, perform worse on memory tests. The opposite is also true, people who do create such mappings, textual/auditory to visual, perform better on memory tests. This suggests that being able to convert representations between different modalities is an important aspect of human cognition and memory.
How does Multimodal Learning work
Multimodal neural networks are usually a combination of multiple unimodal neural networks. For example, an audiovisual model might consist of two unimodal networks, one for visual data and one for audio data. These unimodal neural networks usually process their inputs separately. This process is called encoding. After unimodal encoding takes place, the information extracted from each model must be fused together. Multiple fusion techniques have been proposed that range from simple concatenation to attention mechanisms. The process of multimodal data fusion is one of the most important success factors. After fusion takes place, a final “decision” network accepts the fused encoded information and is trained on the end task.
To put it simply, multimodal architectures usually consist of three parts:
Unimodal encoders that encode individual modalities. Usually, one for each input modality.
A fusion network that combines the features extracted from each input modality, during the encoding phase.
A classifier that accepts the fused data and makes predictions.
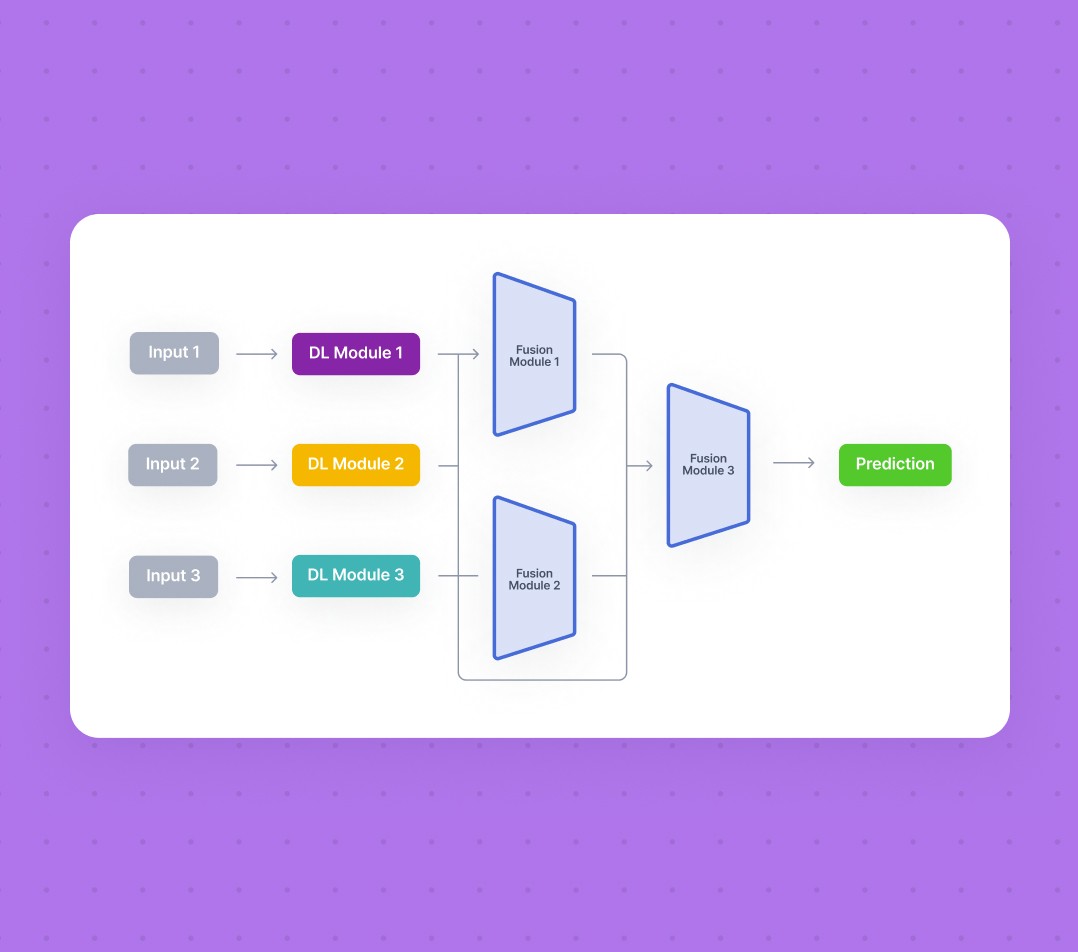
We refer to the above as the encoding module (DL Module in the image below), fusion module, and classification module.
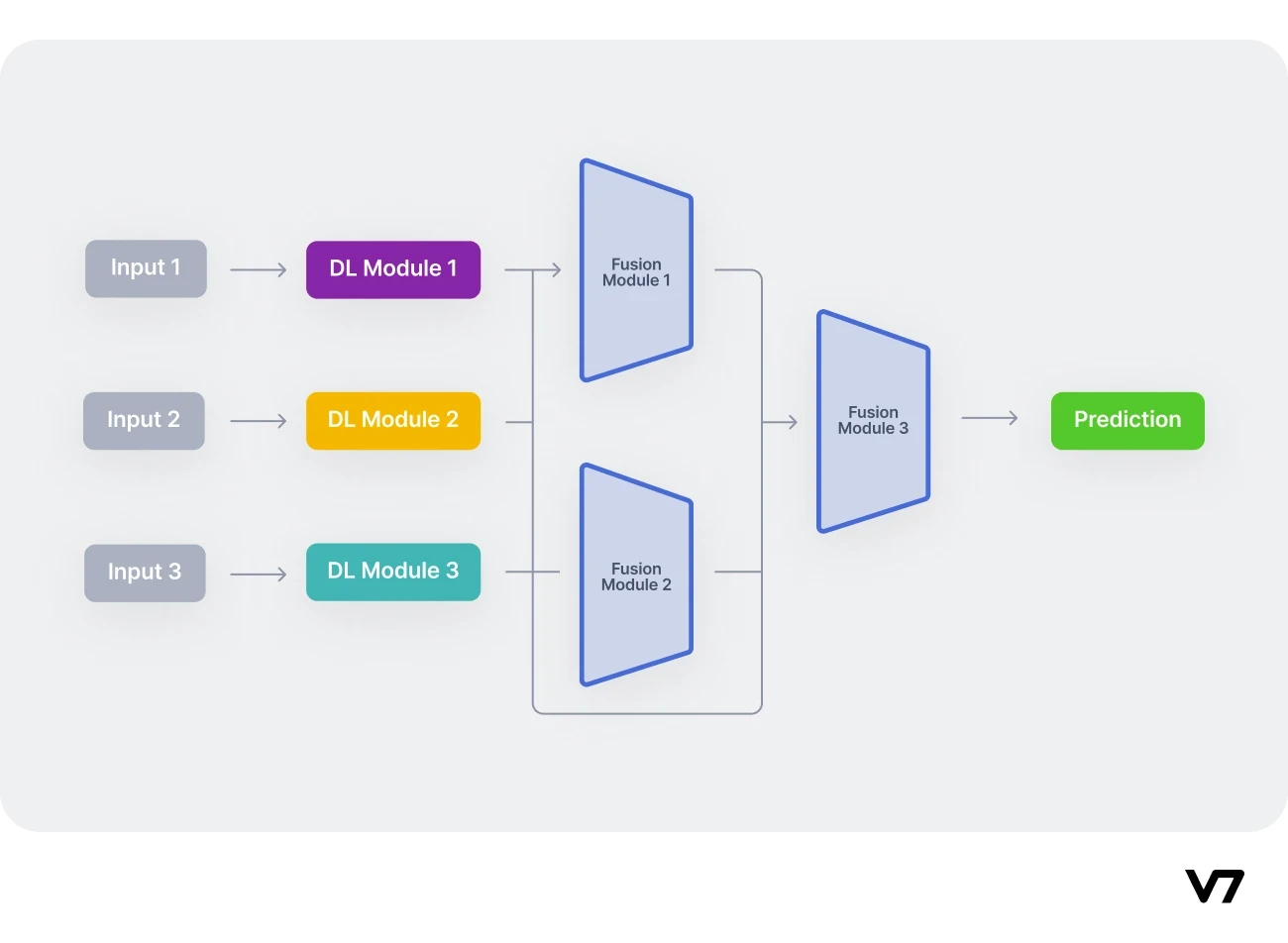
Workflow of a typical multimodal. Three unimodal neural networks encode the different input modalities independently. After feature extraction, fusion modules combine the different modalities (optionally in pairs), and finally, the fused features are inserted into a classification network.
Let’s now dive a little deeper into each component.
Encoding
During encoding, we seek to create meaningful representations. Usually, each individual modality is handled by a different monomodal encoder. However, it’s often the case that the inputs are in the form of embeddings instead of their raw form. For example, word2vec embeddings may be used for text, and COVAREP embeddings for audio. Multimodal embeddings such as data2veq, which translate video, text, and audio data into embeddings in a high dimensional space, are one of the latest practices and have outperformed other embeddings achieving SOTA performance in many tasks.
Deciding whether it's more suitable to use joint representations or coordinated representations (explained in the representation challenge) is an important decision. Usually, a joint representation method works well when modalities are similar in nature, and it’s the one most often used.
In practice when designing multimodal networks, encoders are chosen based on what works well in each area since more emphasis is given to designing the fusion method. Many research papers use the all-time-classic ResNets for the visual modalities and RoBERTA for text.
Read more: Learn more about supervised vs. unsupervised learning and see examples of each.
Fusion
The fusion module is responsible for combining each individual modality after feature extraction is completed. The method/architecture used for fusion is probably the most important ingredient for success.
The simplest method is to use simple operations such as concatenating or summing the different unimodal representations. However, more sophisticated and successful methods have been researched and implemented. For example, the cross-attention layer mechanism is one of the more recent and successful fusion methods. It has been used to capture cross-modal interactions and fuse modalities in a more meaningful way. The equation below describes the cross-attention mechanism and assumes basic familiarity with self-attention.
$$\alpha_{kl} = s(\frac{K_lQ_k}{\sqrt{d}})V_l$$
In the case of three or more modalities, multiple cross-attention mechanisms may be used so that every different combination is calculated. For example, if we have vision (V), text (T), and audio (A) modalities, then we create the combinations VT, VA, TA, and AVT in order to capture all possible cross-modal interactions.
Even after using an attention mechanism, a concatenation of the above cross-modal vectors is often performed to produce the fused vector F. Sum(.), max(.) even pooling operations may also be used instead.
Classification
Finally, once the fusion has been completed, vector F is fed into a classification model. This is usually a neural network with one or two hidden layers. The input vector F encodes complementary information from multiple modalities, thus providing a richer representation compared to the individual modalities V, A, and T. Hence, it should increase the predictive power of the classifier.
Mathematically, the aim of a unimodal model is to minimize the loss
In contrast, the aim of multimodal learning is to minimize the loss
5 Multimodal Deep Learning applications
Here are some examples of Multimodal Deep Learning applications within the computer vision field:
Image captioning
Image captioning is the task of generating short text descriptions for a given image. It’s a multimodal task that involves multimodal datasets consisting of images and short text descriptions. It solves the translation challenge described previously by translating visual representations into textual ones. The task can also be extended to video captioning, where text coherently describes short videos.
For a model to translate visual modalities into text, it has to capture the semantics of a picture. It needs to detect the key objects, key actions, and key characteristics of objects. Referencing the example of fig. 3, “A horse (key object) carrying (key action) a large load (key characteristic) of hay (key object) and two people (key object) sitting on it.” Moreover, it needs to reason about the relationship between objects in an image, e.g., “Bunk bed with a narrow shelf sitting underneath it (spatial relationship).”
However, as already mentioned, the task of multimodal translation is open-ended and subjective. Hence the caption “Two men are riding a horse carriage full of hay,” and “Two men transfer hay with a horse carriage,” are also valid captions.
Image captioning models can be applied to provide text alternatives to images, which help blind and visually-impaired users.

Examples of image captioning, images on top with short text explanations below (source)
Pro Tip: Check out V7 Go for image captioning tasks.
Image retrieval
Image retrieval is the task of finding images inside a large database relevant to a retrieval key. The task is also sometimes referenced as Content-based image research (CBIR) and content-based visual information retrieval (CBVIR).
Such an action may be performed through a traditional tag-matching algorithm, but deep learning multimodal models provide a broader solution with more capabilities which also partially eliminates the need for tags. Image retrieval can be extended to video retrieval. Moreover, the retrieval key may take the form of a text caption, an audio sound even another image, but text descriptions are the most common.
Several cross-modal image retrieval tasks have been developed. Examples include
Text-to-image retrieval: images related to text explanations are retrieved
Composing text and image: a query image and a text that describes desired modifications
Cross-view image retrieval
Sketch-to-image retrieval: a human-made pencil sketch is used to retrieve relevant images
Whenever you make a search query on your browser, the search engine provides an “images” section showing a plethora of images related to your search query. This is a real-world example of image retrieval.
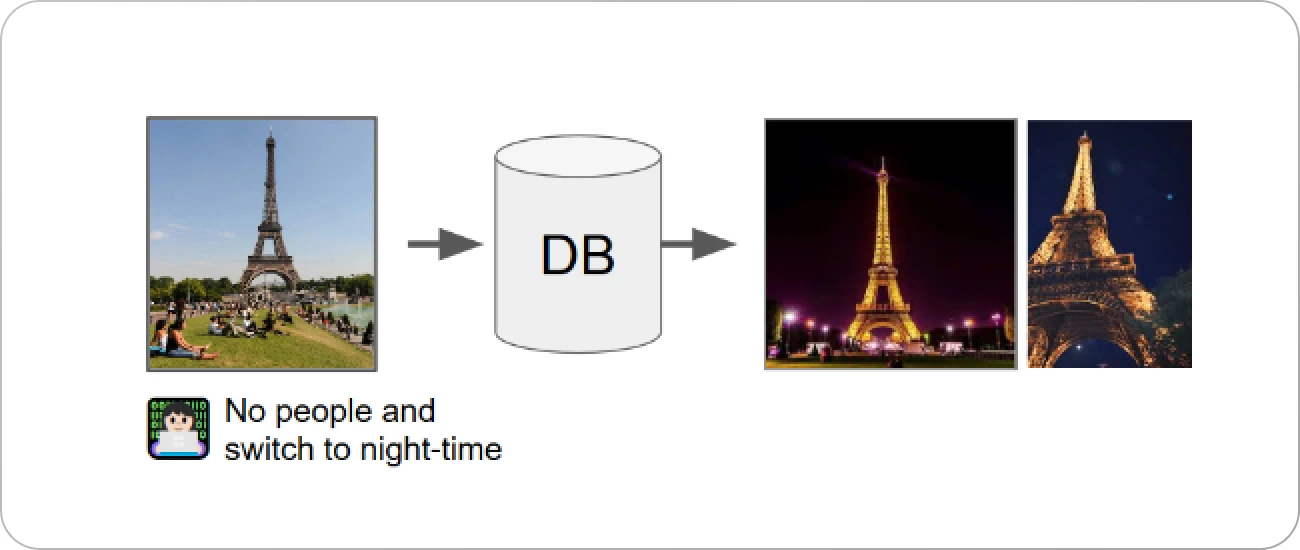
An example of multimodal image retrieval, using composing text + image method. The fetched images are fetched through a database if they meet the criteria of the query image and the text’s description (source)
Text-to-Image Generation
Text-to-image generation is currently one of the most popular multimodal learning applications. It directly solves the translation challenge. Models like Open-AI’s DALL-E and Google’s Imagen have been making headlines.
What these models do can be considered the inverse of image captioning. Given short text descriptions as a prompt, a text-to-image model creates a novel image that accurately reflects the text’s semantic meaning. Recently, text-to-video models also made their first debut.
These models can be applied to aid photoshopping and graphics design while also providing inspiration for digital art.

Example of text-to-image generation. The text on the bottom acts as a prompt, and the model creates the novel image depicted on top (source)
Visual Question Answering (VQA)
Visual Question Answering is another multimodal task that combines visual modalities (image, video) with text modality. During VQA, the user can ask a question about an image or a video, and the model must answer the question based on what is happening in the image. A strong visual understanding of a scene, along with common sense knowledge, is required to successfully tackle this problem. Simple examples of closed-form VQA include “How many people are in the picture”, and “Where is the child sitting?” However, VQA can expand to free-form, open-ended questions which require a more complex thought process, like the image below.
Visual question answering is a multimodal application that incorporates both translation and alignment challenges.
These models can be applied to help blind and visually-impaired users or provide advanced visual content retrieval.

Examples of open-ended, free-form questions for VQA tasks. Answering requires a complex thought process, precise decoding, and linking of both modalities involved (source)
Emotion Recognition
Emotion recognition is a great example of why multimodal datasets are preferred over monomodal ones. Emotion recognition can be performed with just monomodal datasets, but performance may be improved if multimodal datasets are used as input. The multimodal input may take the form of video + text + audio, but sensor data like encephalogram data may also be incorporated in the multimodal input.
However, it has been shown that sometimes using multiple input modalities may actually degrade performance compared to single modality counterparts, even though a dataset with multiple modalities will always convey more information. This is attributed to the difficulty of training multimodal networks. If you are interested in learning more about the difficulties, this paper should prove useful.
Multimodal Deep Learning Datasets
Without data, there is no learning.
Multimodal machine learning is no exception to this. To advance the field, researchers and organizations have created and distributed multiple multimodal datasets. Here’s a comprehensive list of the most popular datasets:
COCO-Captions Dataset: A multimodal dataset that contains 330K images accompanied by short text descriptions. This dataset was released by Microsoft and aims to advance the research in image captioning.
VQA: A Visual Question Answering multimodal dataset that contains 265K images (vision) with at least three questions (text) for each image. These questions require an understanding of vision, language, and commonsense knowledge to answer. Suitable for visual-question answering and image captioning.
CMU-MOSEI: Multimodal Opinion Sentiment and Emotion Intensity (MOSEI) is a multimodal dataset for human emotion recognition and sentiment analysis. It contains 23,500 sentences pronounced by 1,000 YouTube speakers. This dataset combines video, audio, and text modalities all in one. A perfect dataset for training models on the three most popular data modalities.
Social-IQ: A perfect multimodal dataset to train deep learning models on visual reasoning, multimodal question answering, and social interaction understanding. Contains 1250 audio videos rigorously annotated (on the action level) with questions and answers (text) related to the actions taking place in each scene.
Kinetics 400/600/700: This audiovisual dataset is a collection of Youtube videos for human action recognition. It contains video (visual modality) and sound (audio modality) of people performing various actions such as playing music, hugging, playing sports, etc. The dataset is suitable for action recognition, human pose estimation, or scene understanding.
RGB-D Object Dataset: A multimodal dataset that combines visual and sensor modalities. One sensor is RGB and encodes colors in a picture, while the other is a depth sensor that encodes the distance of an object from the camera. This dataset contains videos of 300 household objects and 22 scenes, equal to 250K images. It has been used for 3D object detection, or depth estimation tasks.
Other multimodal datasets include IEMOCAP, CMU-MOSI, MPI-SINTEL, SCENE-FLOW, HOW2, COIN, and MOUD.
Pro tip: If you’re looking for quality training data for your next computer vision project, explore our repository of 500+ open datasets.
Key takeaways
Multimodal deep learning is a step toward more powerful AI models.
Datasets with multiple modalities convey more information than unimodal datasets, so machine learning models should, in theory, improve their predictive performance by processing multiple input modalities. However, the challenges and difficulties of training multimodal networks often pose a barrier to improving performance.
Nonetheless, multimodal applications open a new world of possibilities for AI. Some tasks which humans may be very good at performing are only possible when models incorporate multiple modalities into their training. Multimodal deep learning is a very active research area and has applications in multiple fields.
Konstantinos Poulinakis is a machine learning researcher and technical blogger. He has an M.Eng. in Electrical & Computer Engineering and an M.Sc.Eng in Data Science and Machine Learning from NTUA. His research interests include self-supervised and multimodal learning.

