LLMs
Visual ChatGPT: Multimodal Capabilities and Use Cases for 2024
13 min read
—
Jan 17, 2024
Explore the image analysis features of GPT-4V for business use cases. This article will help you understand its potential and limitations, and prepare for the future of multimodal AI.

Content Creator
The AI hype, at least with regards to the appetite of the general public, seems to have peaked in mid-2023. Now, using large language models in your everyday work has become the new norm. Meanwhile, multimodal features have subtly entered the scene. In fact, GPT models which can understand user-uploaded images have been around for several months, charting new territory in machine learning.
So, what happens when ChatGPT can not only read, write, and code but also understand photos, financial charts, or hand-drawn wireframes? What are the implications for businesses? And how will it transform the landscape of data-driven decision-making?
Straddling the line between advanced natural language processing and perceptive image analysis, this iteration of GPT-4 with “vision” offers an interesting glimpse into the future of AI applications in the commercial sphere.
In this article we cover:
What is GPT-4V and how does it differ from DALL·E 3?
What are the capabilities and limitations of the new image features?
How to implement image recognition and the multimodal features of GPT models
Example use cases and future implications
What is GPT-4 with vision?
GPT-4 with vision refers to multimodal capabilities of GPT-4 models, where they have been extended to interpret not just text, but also visual content. This is achieved by integrating computer vision technologies with pre-existing natural language processing (NLP) functionalities of the model.
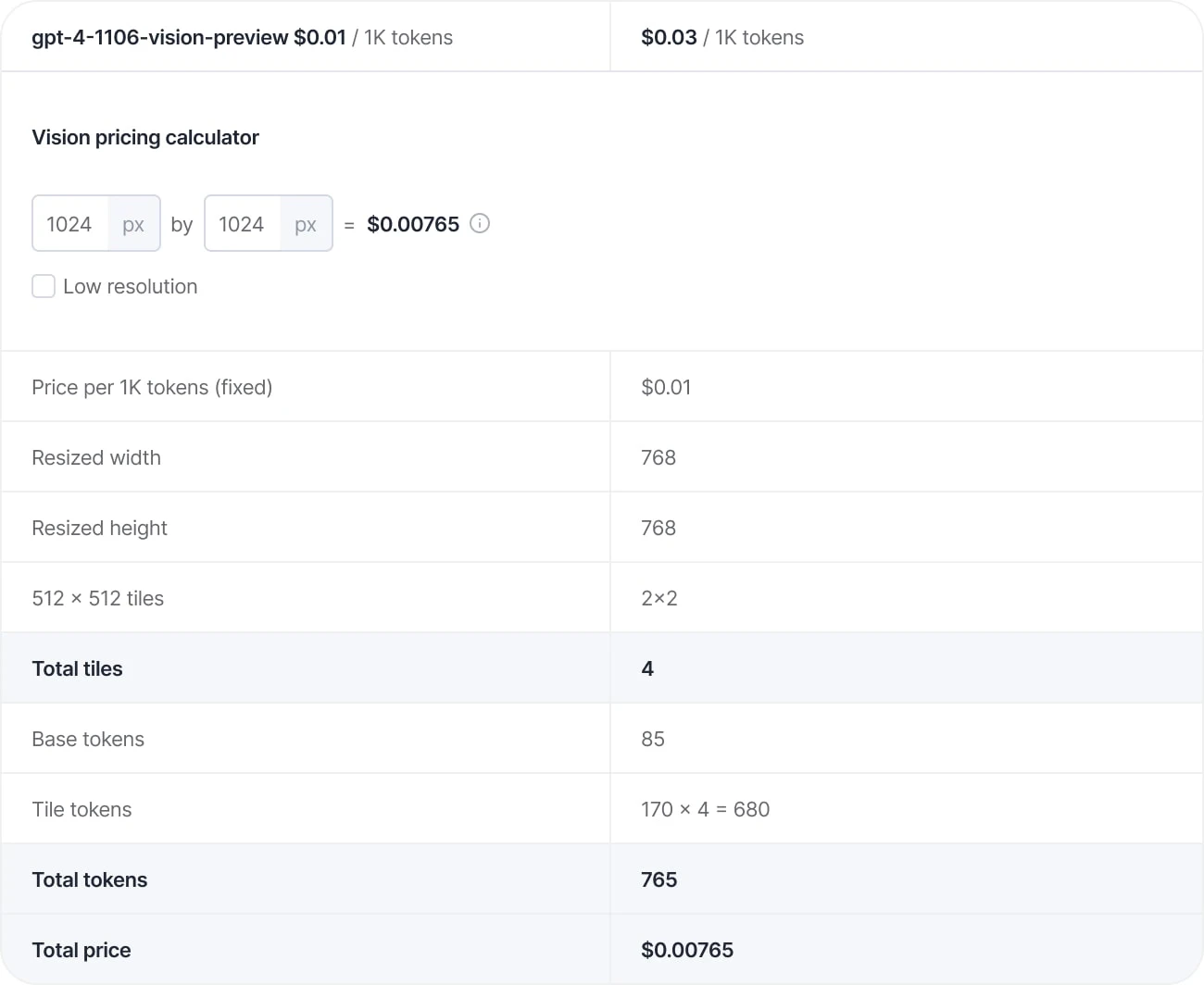
⚠️ There are some inconsistencies regarding naming conventions. Official documentation and content from OpenAI includes names like GPT-4 Vision, GPT-4 with vision, GPT-4V(ision), GPT-4V, or simply multimodal GPT-4 (with images and texts being the two most important modalities). Essentially, they all refer to the same functionality. When using a specific version of the model in the API, we need to use model names like gpt-4-1106-vision-preview.
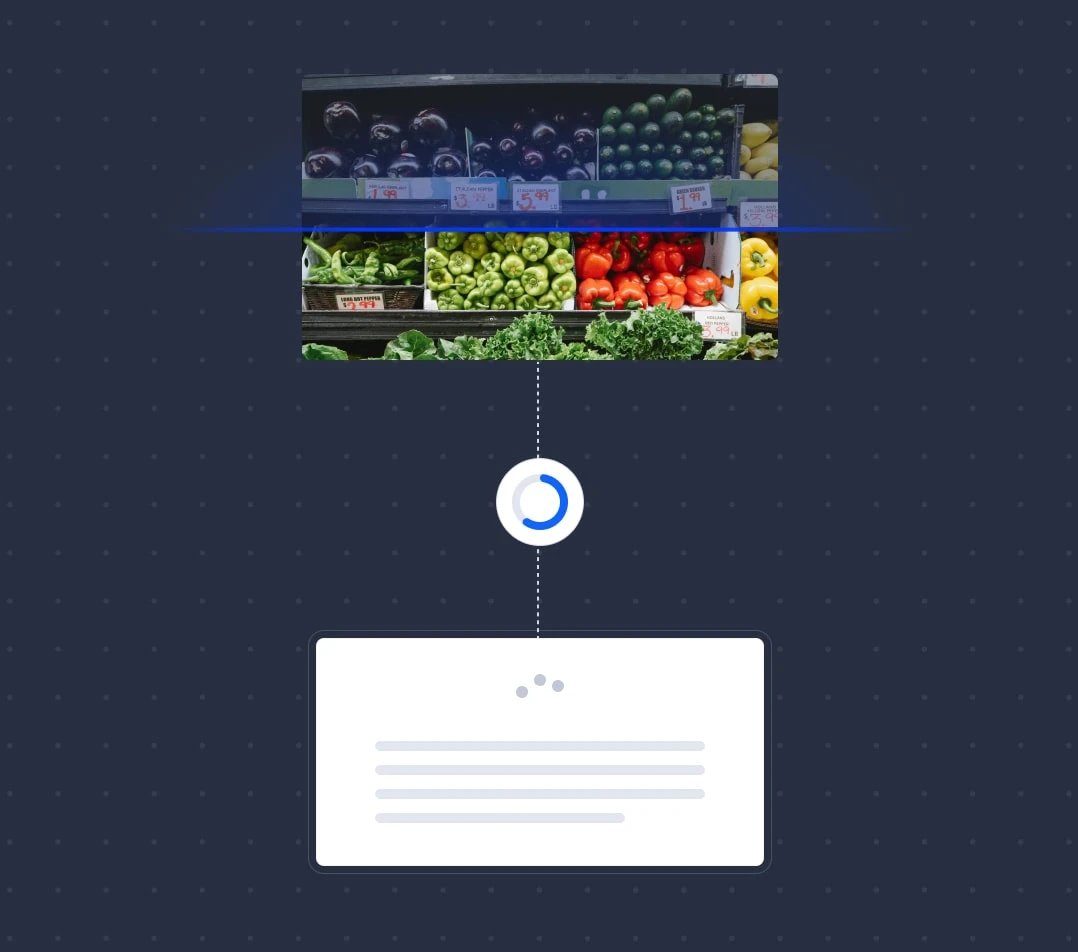
The GPT-4V AI's ability to understand and respond to images is based on extensive training with diverse datasets that teach it to recognize patterns and infer information from visual inputs. Let’s look at an example below.
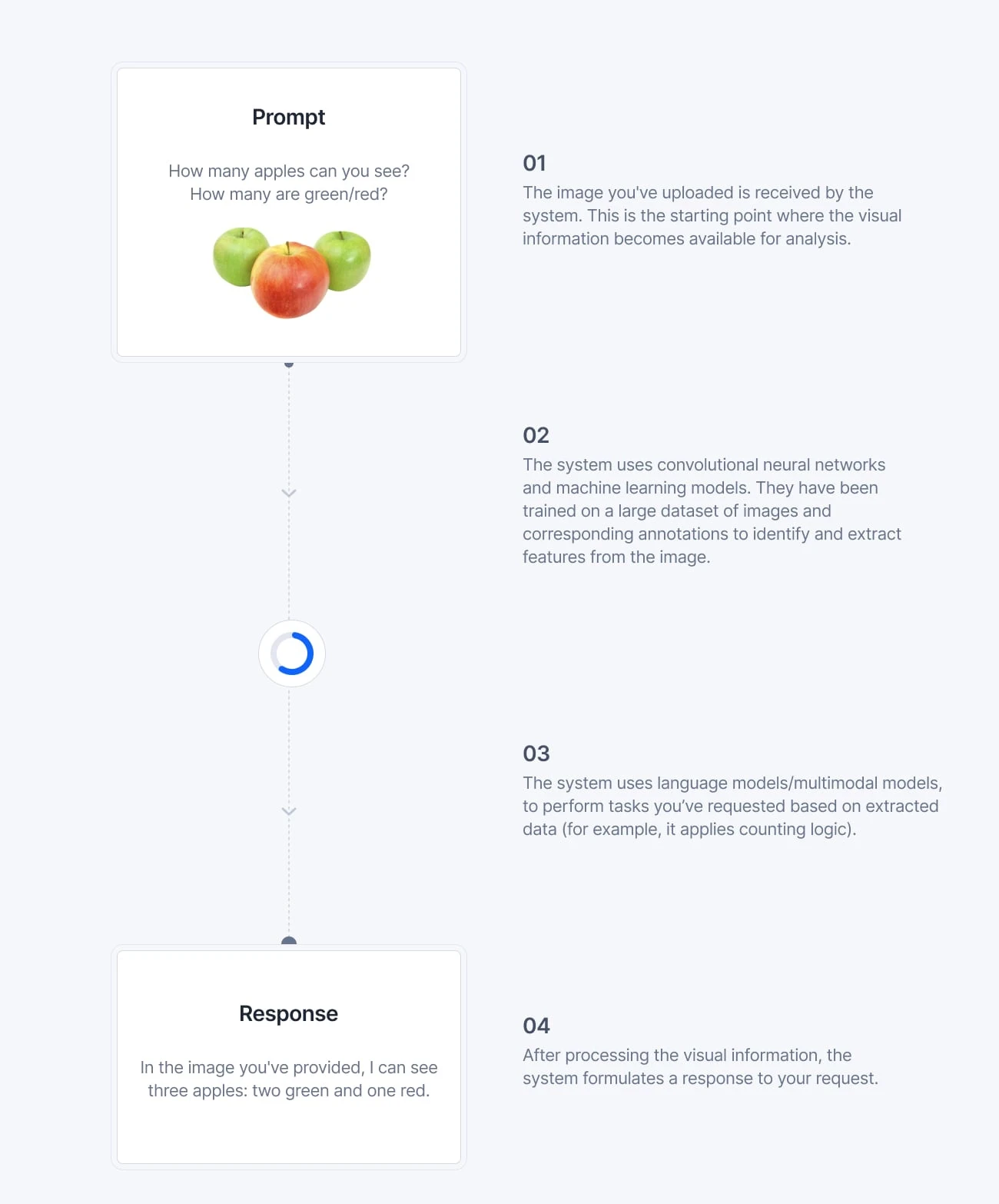
GPT-4 Vision features, which began rolling out to ChatGPT Plus and Enterprise subscribers in late 2023, have shown promise in numerous tests, from visual question answering to optical character recognition (OCR). The new GPT-4 has even been known to solve math problems presented in images.
Functionalities of ChatGPT Vision
Good performance

Performed to some extent

Despite many advances, GPT-4V does have some serious limitations.
Limitations

GPT-4 Vision’s strength lies in enhancing contextual understanding, transforming the AI from a text-only interpreter to a multimodal analyst. This capability is a boon for sectors like retail and advertising, offering richer customer insights and more personalized content.
Still, precise object detection and specialized domain analysis remain the biggest challenges, emphasizing GPT-4 Vision's role as a complementary tool rather than a standalone solution. It excels in broad pattern recognition but requires fine-tuning for specific use cases. For instance, while it can perform optical character recognition, it doesn't match the accuracy and reliability offered by specialized OCR and document automation software. Similarly, when it comes to domain-specific image analysis, particularly in medical imaging, GPT-4 Vision falls short of the detailed analysis achievable through DICOM annotation tools.
Additionally, AI image analysis is prone to bias when there is a mismatch between some elements of the input. It can be easily confused by the content of additional images within images or mislabeled objects.

The quality of data annotation remains crucial in this landscape. In fact, GPT-4 Vision can act as an auxiliary tool in preparing nuanced datasets for training, especially for tasks involving Reinforcement Learning from Human Feedback (RLHF) and specialized models. For example, in industries like fashion, it can augment clothing segmentation models by adding custom properties to specific masks, enriching the dataset's depth and utility. It can turn thousands of images into a categorized database of annotations (shirts/pants/socks) with additional information (color/size/style/material).

GPT-4 with Vision is not a plug-and-play solution for real-time applications, especially in high-stakes scenarios. Training your own model based on proprietary data pre-processed with GPT-4 with Vision is a safer solution than relying on GPT-4 with Vision as the end model.
Take, for example, the potential use of GPT-4 for wildfire detection AI. While GPT-4 with Vision can assist in labeling historical data for training computer vision models, it doesn't serve as a dependable standalone tool for real-time wildfire detection.
The model's current iteration is best suited for backend data processing and preparation, where it can enhance the richness and accuracy of training datasets, particularly in conjunction with human-in-the-loop workflows.
GPT-4 Vision vs DALL-E 2/DALL-E 3
GPT-4V specializes in image analysis and interpretation. It's geared towards applications like object recognition in existing images and automatic tag generation. DALL-E models, on the other hand, are focused on image generation from text prompts, a functionality that’s particularly useful for creating new visual content and AI-generated art.

Using the ChatGPT interface can provide a truly multimodal experience, as the AI can automatically decide which modules to use at any given moment. It can seamlessly switch between online research, image analysis, or image generation, utilizing the capabilities of Bing, Vision, or DALL·E respectively, without the need to invoke specific models.

However, in a more advanced setup, using the OpenAI API to integrate these modules separately can offer higher control and customization. Utilizing the API ensures access to the latest service features while managing costs effectively, which is crucial for commercial applications.
How to access multimodal GPT-4 with vision
If you just want to try GPT-4V for your use case, you can test it with a ChatGPT Plus subscription. Just make sure to switch your model from GPT-3.5 to GPT-4, allowing you to upload images for analysis.

ChatGPT Plus is a great way to play around and test some image analysis functionalities, but there is a limit on the number of messages, and the processing can be somewhat slow.
Due to exceptionally high demand, OpenAI also occasionally pauses new ChatGPT Plus subscriptions. This happened in late 2023 and could potentially happen again. If you want to avoid joining the waitlist, it is better to use the “developer” mode (billed per usage). Sign in to your OpenAI account, generate an authentication key, and use the API instead of the chat interface.
The API is much better than the chat interface for actual deployment and leveraging GPT-4 with vision at scale. You can select between different models, and GPT-4V is available as 'gpt-4-vision-preview' in the request configuration.
If you want to use the most recent version, you can modify this line to ensure your model is up-to-date. It's best to consult the official pricing page.
Here is an example of a request:

And this is our response generated after running the script:

As you can see, the predictions (in this particular case) are correct.
How to incorporate GPT-4V into your app or ML pipeline
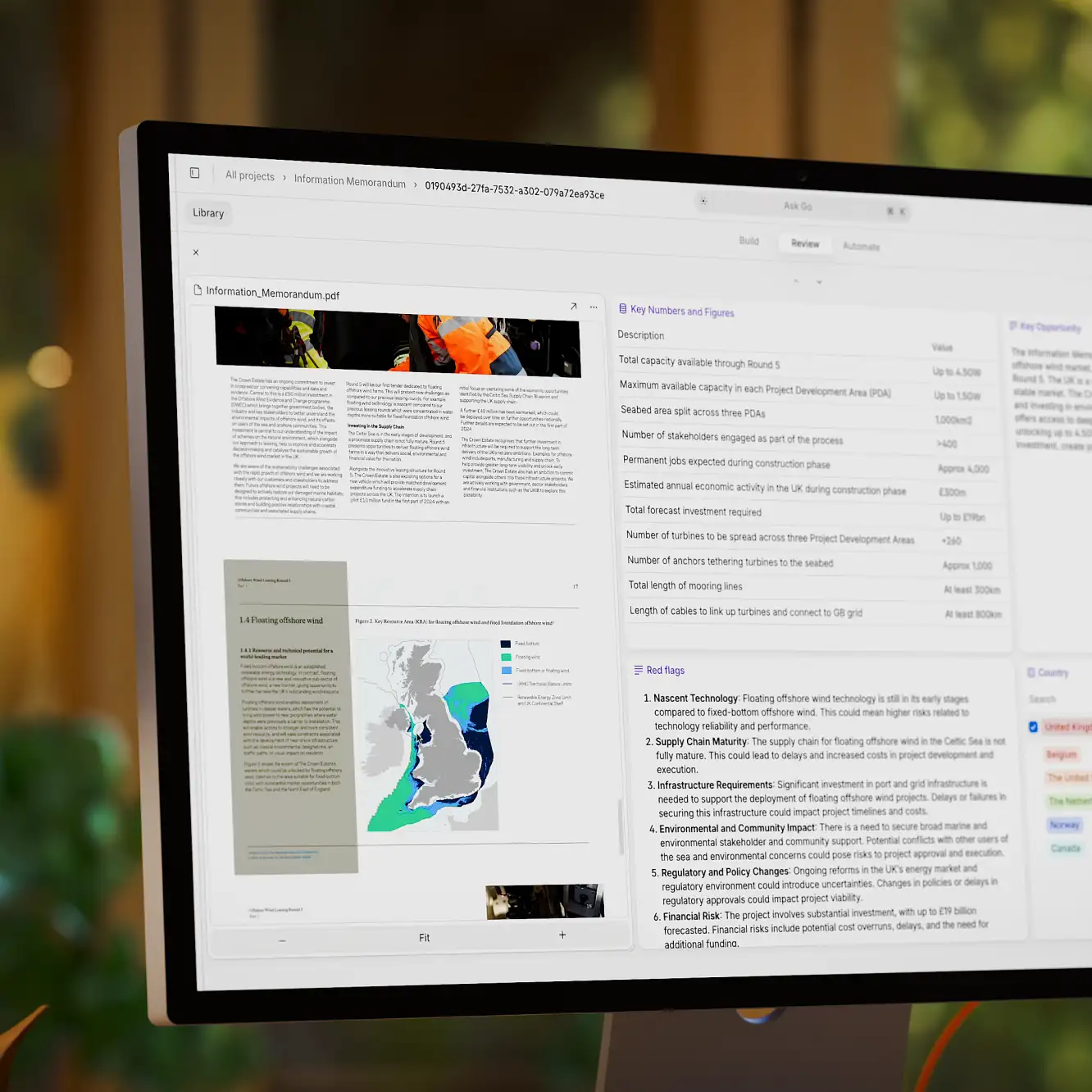
With additional code for pre-processing your input and for parsing the response, we can implement GPT-4V into any app that can handle API calls. For instance, if we want to train our own commercial AI model, we need a training data platform that can be connected to GPT-4V for labeling our datasets.
Here is an example of integrating GPT-4V and V7 Darwin:
In the video above, you can see GPT-4 with vision registered as an external model and used as a model stage in a V7 workflow. The prompt instructs GPT-4V to determine whicht emotions it can associate with the image and the outputs are mapped onto specific V7 classification tags.
All of this can be achieved with a short Python script. This is what the process looks like:
The script uses Flask to create a simple web server.
The script defines a URL endpoint where it can receive POST requests (if you want to try it out, you can deploy it with Ngrok or a similar solution).
When it receives a POST request (a JSON payload sent by V7), it checks if the request has an image URL.
If yes, it sends the image URL to the OpenAI API, asking GPT-4V for an analysis (in this case, an analysis of emotions present in the image).
The OpenAI API returns a list of primary and secondary emotions detected in the image.
The script then formats these emotions into a Darwin JSON response (for example, it determines the confidence score based on primary/secondary emotions) and sends it back to the requester. In our example, this means that new tag annotations will be automatically added to the image.
It's essential that our prompt is clear and that our output can be parsed with ease.
Here is what the request sent to GPT-4V looks like:
I'm going to share a picture with you. Determine the primary and secondary emotions that you can associate with the image.
Pick emotions ONLY from these: (Happiness, Sadness, Anger, Anxiety, Concern, Joy, Fear, Distress, Disgust, Surprise, Trust, Anticipation, Hope, Love, Contentment, Amusement, Boredom, Shame, Pride, Embarrassment, Excitement, Satisfaction, Relief, Nostalgia, Curiosity, Confusion, Admiration, Sympathy, Compassion, Contempt, Envy, Jealousy, Guilt, Defeat, Triumph, Loneliness, Despair, Euphoria, Awe, Eagerness, Enthusiasm, Melancholy, Gratitude, Indignation, Frustration, Overwhelm, Resentment, Serenity, Apprehension, Calmness, Disappointment, Optimism, Pessimism, Sorrow, Regret, Tenderness, Yearning, Schadenfreude, Wanderlust).
Use this structure in your response:
{ "primary_emotions": ["emotion1_primary", "emotion2_primary", "..."], "secondary_emotions": ["emotion1_secondary", "emotion2_secondary", "..."] }
Give me only the JSON response, with no additional commentary.
This output can be automatically parsed and turned into V7-conforming output.

As you can see, integrating GPT-4 Vision into your applications and machine learning pipelines is remarkably straightforward. OpenAI provides an accessible interface through its API, making it easy for developers to leverage the model's capabilities.
With this simple setup, you can start harnessing the power of GPT-4 Vision to analyze and understand visual content within your projects. Now, let's go through some practical examples of how this technology can be applied across various industries.






Business use cases for GPT Vision
For businesses looking to stay ahead of the curve, the integration of GPT-4's vision capabilities could be the key to developing smarter, more intuitive AI systems. From enhancing product recommendation algorithms to refining consumer data interpretation, the practical applications are very compelling.
1. Adding depth to training data with nuanced properties and tags
Traditional AI classification and detection have often been limited to broad categories. However, GPT-4 introduces a paradigm shift by enabling the assignment of nuanced properties and tags to images based on their content.
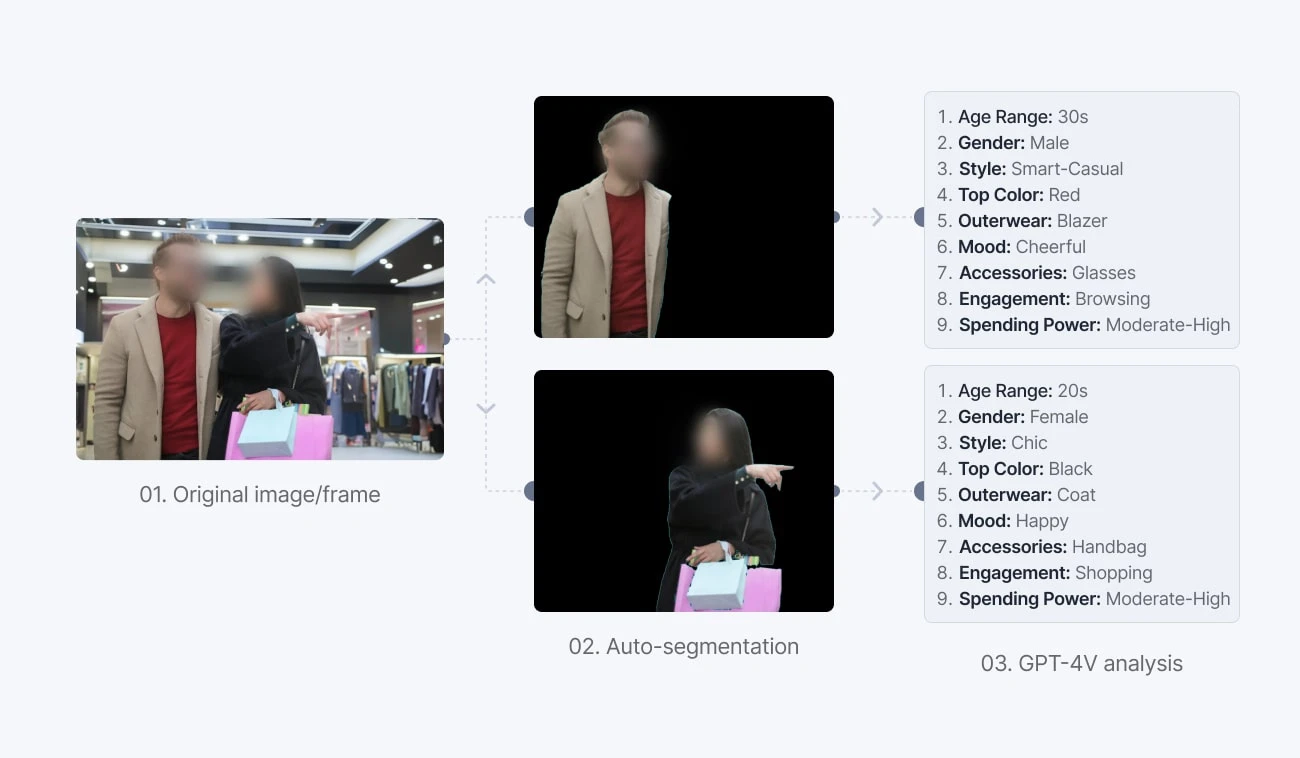
For example, in a retail context, instead of classifying an image simply as "person," GPT-4 can add detailed attributes like estimated age, clothing type, and more. By pre-processing images with open-source object detection or instance segmentation models and then enriching them with GPT-4-generated properties, businesses can develop more sophisticated AI.
2. Improving product discoverability with AI-generated descriptions
In e-commerce, the ability to auto-generate detailed product descriptions is a game-changer. GPT-4 can provide intricate details about products, including colors, materials, textures, and styles.

This capability not only enhances metadata for improved search engine optimization (SEO) but also bolsters product recommendation engines, enabling more effective upselling and cross-selling strategies.
3. Ensuring digital safety through advanced content moderation
GPT-4V's ability to evaluate images across various criteria makes it an invaluable tool for digital safety and content moderation.

It can determine the appropriateness of images, identifying and flagging content related to hate speech, NSFW material, violence, substance abuse, or harassment. This functionality is not just limited to flagging inappropriate content but also extends to content analytics, providing deeper insights into the nature of shared digital media.
4. Recognizing expressions, emotions, and activities for better security
AI image and footage analysis applications range from preventing shrinkage in retail and detecting vandalism to monitoring the exhaustion of pilots or drivers for enhanced safety measures.

By tagging historical videos, GPT-4V facilitates the training of specialized models capable of real-time activity detection, reducing the reliance on third-party applications and streamlining security protocols.
5. Speeding up AI quality control in manufacturing
In the manufacturing sector, GPT-4V can significantly expedite AI-driven quality control processes. Its advanced vision capabilities enable the quick identification of defects, inconsistencies, and potential failures in products, ensuring higher quality standards and reducing waste.

With GPT-4V, it is best to provide both the captured production line image of an item and the corresponding reference images of the product without any defects. With complex datasets, it can also be helpful to crop images and focus on identifying one particular part or defect at a time.
6. Leveraging research and behavioral insights with video analytics
By analyzing video content, businesses can gain a deeper understanding of consumer behaviors, preferences, and engagement patterns. This information can be instrumental in tailoring marketing strategies, improving product designs, and enhancing overall customer experience.
While GPT-4V does not support video analysis (yet), extracting frames at specific intervals and analyzing them as individual images can be quite effective for certain use cases. This method can be applied to monitor bacterial growth in petri dishes or to process drone footage for agricultural purposes.
Here is an example of the analysis of frames extracted from a video monitoring plant health.

7. Automating inventory classification and retail shelf space analysis
Finally, GPT-4V can revolutionize retail operations by automating inventory classification and optimizing shelf space analysis. Its ability to accurately identify and categorize products enables more efficient inventory management, reducing overhead costs and improving stock accuracy.

Additionally, analyzing shelf space and product placement through GPT-4V can lead to more effective merchandising strategies, ultimately driving sales and customer satisfaction. This can be particularly helpful when combined with customer footfall analytics.Towards Multimodal GPT: ConclusionThe GPT-4 Vision feature has already begun to redefine the boundaries of what AI can achieve, from improving product discoverability to enhancing digital safety. It has also set the stage for GPT-5, which is anticipated to further refine these capabilities. While GPT-4V functionalities like object recognition, descriptive analysis, and content summarization are making waves, its limitations in object detection precision, specialized domain analysis, and interpretation of complex visual data highlight the need for continued innovation.
As businesses adapt to these new tools, the synergy between human oversight and AI's analytical prowess will become more crucial than ever. The future will likely see AI not as a standalone solution but as a powerful assistant that augments human capabilities, ensuring that data-driven decisions are not only informed by comprehensive analysis but also tempered by human insight and expertise.
The role of GPT-4 with vision is emblematic of this shift, offering a glimpse into how AI can serve as a partner in the intricate dance of interpreting the world around us—a world that is as visual as it is textual. Whether in the bustling aisles of retail stores, the meticulous processes of manufacturing, or the vast expanses of agricultural land, visual ChatGPT is paving the way for a more intuitive and integrated approach to AI in our everyday lives.
If you want to find out more about integrating GPT-4V into your projects, you can create a V7 account and use it as your AI copilot and data management platform.