LLMs
Active Learning in Machine Learning [Guide & Examples]
17 min read
—
Aug 31, 2022
Active learning is a type of machine learning where the model is trained on only the most relevant data. Explore the benefits and limitations of the framework.

Guest Author
The modern world uses Deep Learning as the de facto algorithmic backbone for all Computer Vision tasks—from image classification and segmentation to scene reconstruction and image synthesis. However, the basis for the success of most algorithms has been the use of an enormous quantity of good-quality labeled data, i.e., examples whose ground truth is already available for training a model (a technique called Supervised Learning).
Data Labeling is a highly laborious process, consuming about 80% of the time dedicated to a Machine Learning project. Even then, some labels may be erroneous, thus adversely affecting the model training. For this reason, current methods focus on reducing the need for labeled training data and utilizing the vast amount of unstructured data available in this information technology era.
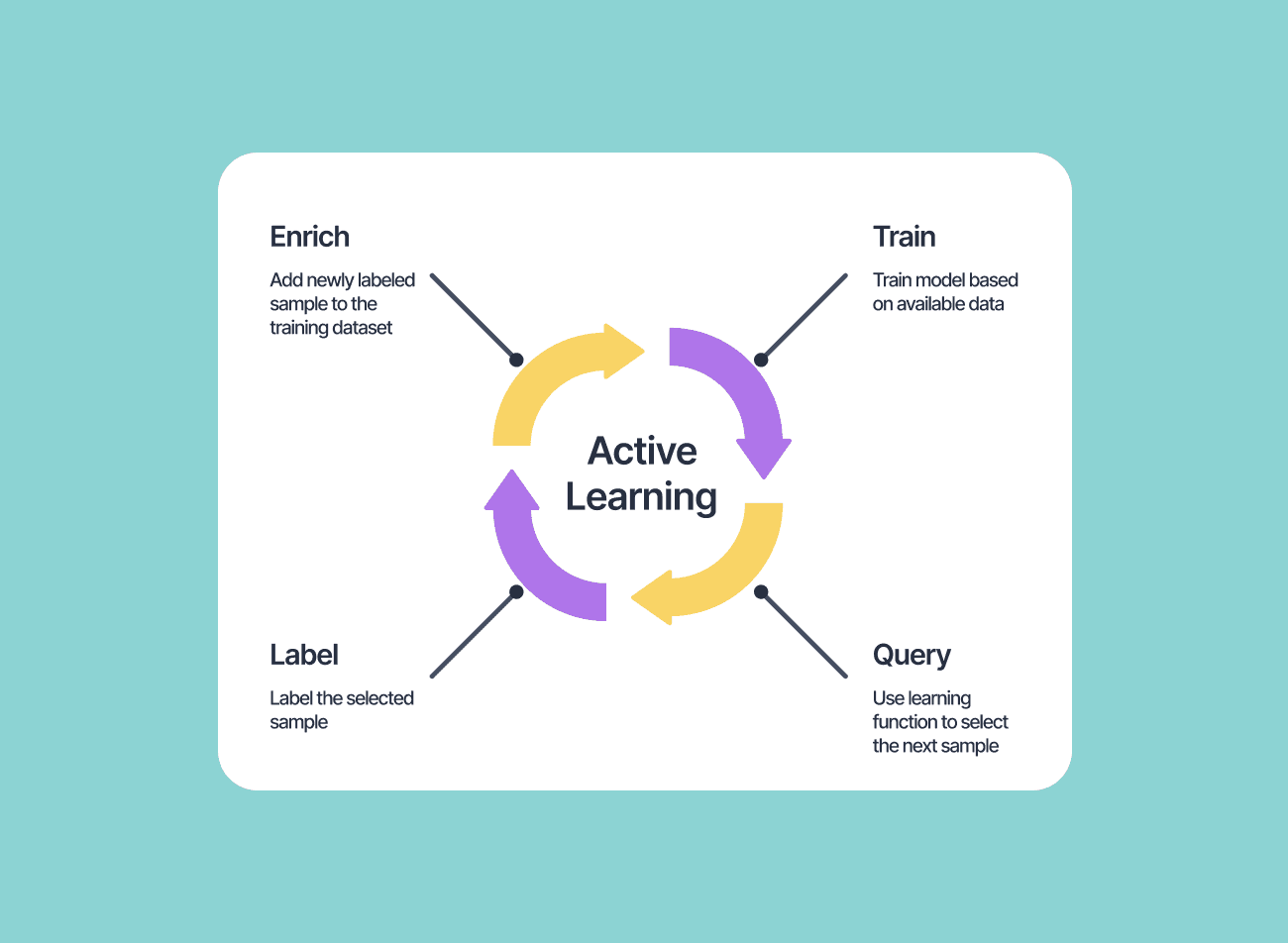
Active Learning is one such low supervision method, which belongs to the class of “Semi-Supervised Learning,” a learning paradigm where a small amount of labeled data and a large quantity of unlabeled data are used together to train a model.
But what is Active Learning, and why is it called “active”? Let us look into that next.
Here’s what we’ll cover:
What is Active Learning?
Active Learning Query Strategies
Informativeness Measures
Applications of the framework
What is Active Learning?
Before we move on to the active learning definition, consider this:
A deep learning network that is tasked with classifying dog and cat images does not just say whether an image shows a dog or a cat.
It is much more complex than that.
The network makes predictions in its task with a “confidence” score, which tells us how sure the network is of its own prediction (much like us, humans, function).
Active Learning is a “human-in-the-loop” type of Deep Learning framework that uses a large dataset of which only a small portion (say 10%) is labeled for model training. Say there is a dataset of 1,000 samples, of which 100 are labeled. An Active Learning-based model will train on the 100 samples and make predictions on the rest of the 900 samples (test set). Suppose, of these 900 samples, the confidence in prediction was very low for 10 samples. The model will now ask a human user to provide it with the labels for these 10 samples. That is, an Active Learning framework is interactive, and that’s how the name “Active” was coined.
The 10 samples in the above example are the ones that will provide the maximum learning opportunity for the model because they are confusing or difficult samples (samples whose embedding lies close to the classification boundary). The human annotator thus has to label only a handful of the discriminative samples the model asks the labels for instead of spending hours labeling samples of the same category, which the model could have generalized on without any help in the first place. This reduces the data labeling effort by several folds.
Active Learning clearly mimics the human learning process closely. A student is first trained on the basics by a teacher (initial 10% of the labeled data). Then the student is given tasks to solve in close supervision by the teacher (model training on the small labeled data). The student is then asked to solve problems on their own (predictions on the test set) and ask for help only if they get really stuck (very low confidence predictions on 10 samples). Using the knowledge gained from the mistakes the student previously made, they can now perform the same task with much more accuracy and much less external help.
Let’s dive a little deeper into the technical side of Active Learning algorithms next.
Active Learning Query Strategies
Active Learning is a method describing how to utilize labeling resources efficiently. It improves the training efficiency by selecting the most valuable data samples from an unlabeled database for annotation by the user (query). The selected samples for training are mostly unfamiliar and uncertain to the current model. The most common active learning methods can be categorized into (1) Stream-based selective sampling, (2) Pool-based sampling, and (3) Query Synthesis methods.
Let us look into these methods one by one.
Stream-based Selective Sampling
Sampling assumes a continuous stream of incoming unlabeled data points. The current model and an informativeness measure (which we’ll take a closer at in the next section) are used to decide, for each incoming data point, whether or not to ask the user(s) for an annotation-based on a pre-selected threshold value.
This query type is usually computationally inexpensive but offers limited performance benefits due to the isolated nature of each decision: the wider context of the underlying distribution is not considered. For this reason, balancing exploration and exploitation of the distribution are better captured in this sampling method than in other query types.
One example of such a method is the PAL, or Policy-based Active Learning, framework which employs stream-based selective sampling for active learning in a deep reinforcement learning problem. PAL learns a dynamic active learning strategy from data which allows for the strategy to be applied in other data settings, such as cross-lingual applications. PAL does not use a fixed heuristic but instead learns how to actively select data, formalized as a reinforcement learning problem. The stream-based learning workflow is illustrated below.

Source: Paper
Results obtained by the PAL model in sentence translation tasks compared to other Active Learning approaches are shown below.

Pal.b = Bilingual, Pal.m = Multilingual. Source: Paper
Pool-based Sampling
In Pool-based sampling, a large pool of unlabeled data is available to draw samples from and the deep active learning model seeks to select a batch of N samples from this unlabeled set. The instances in the batch that need to be labeled are sampled based on some “informativeness” measure. This measure ranks all the samples in the pool (or minibatch), and the most informative instance(s) are selected for querying the user.
An example of the usage of Pool-based sampling is the method developed in this paper. The authors take inspiration from typical deep learning architectures that use only one single loss for any simple or complex tasks and propose a loss-prediction module. The loss prediction module is attached to a deep network that is tasked with predicting the loss of a data point so that it becomes possible to select data points that are expected to have high losses.
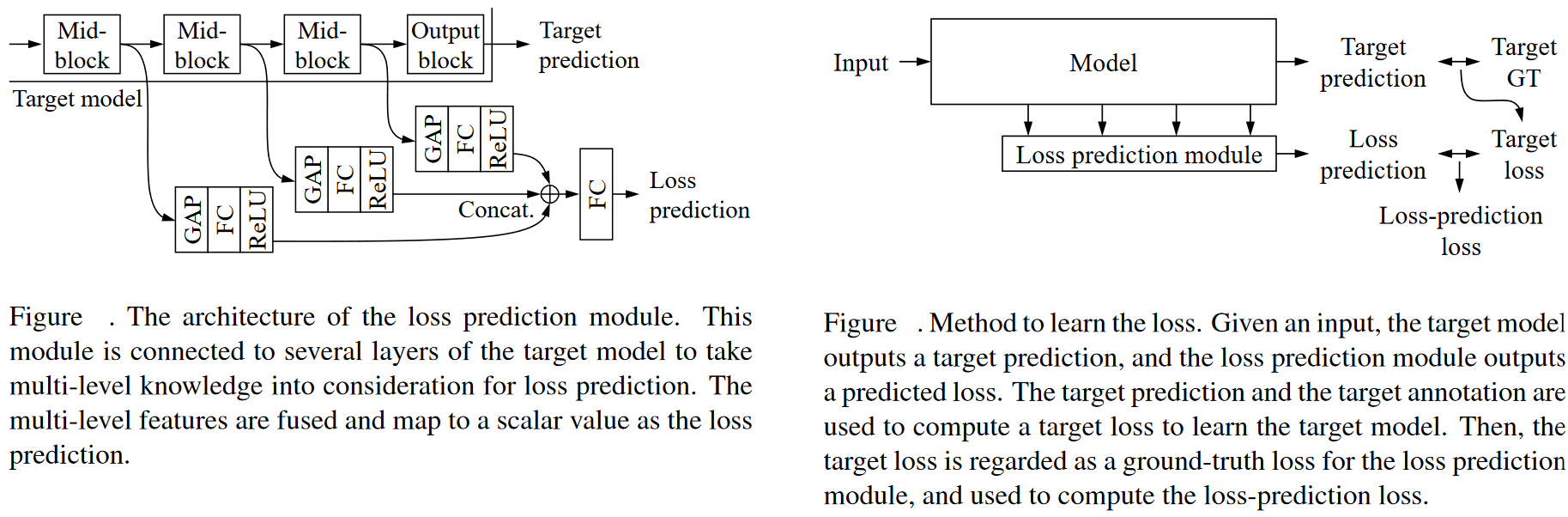
Source: Paper
The authors employed their method in a range of Vision tasks—image classification, human pose estimation, and object detection, to validate the framework. The results obtained by the authors are shown below.
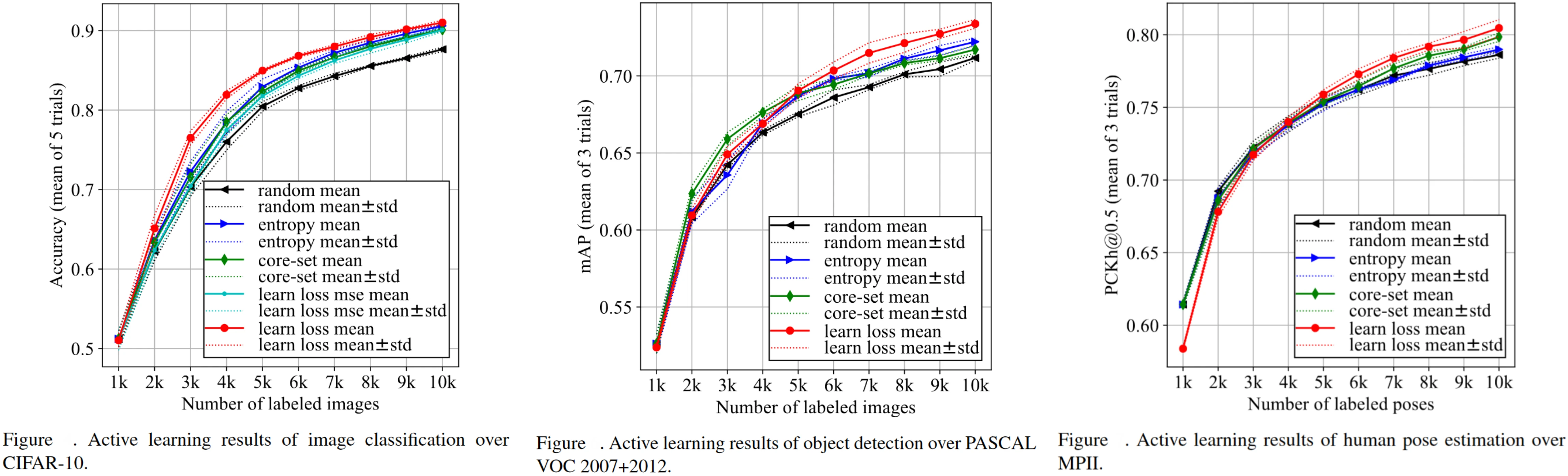
Source: Paper
Query Synthesis Methods
Query-synthesis methods apply generative models to generate training instances based on unlabeled pools. That is, rather than drawing from a real-world distribution of data points, the model generates a data point that the current model ‘believes’ will be most informative to itself. Generative Adversarial Networks (GANs) are the go-to methods for curating data points that resemble real data, including delicate areas like synthetic biomedical image generation.
GANs typically have two separate networks—one is called the generator, and the other is called the discriminator. The generator is tasked with generating new samples to mimic real data points to fool the discriminator. The discriminator’s job is to classify incoming samples as real or fake (generated by the generator model). This leads to an adversarial game that forces the generator to produce more realistic samples and the discriminator to be a better critic.
For example, this paper proposed Adversarial Sampling for Active Learning (ASAL), which was the first to use a GAN model for adversarial sampling to tackle multi-class problems. ASAL’s model architecture is shown below schematically.
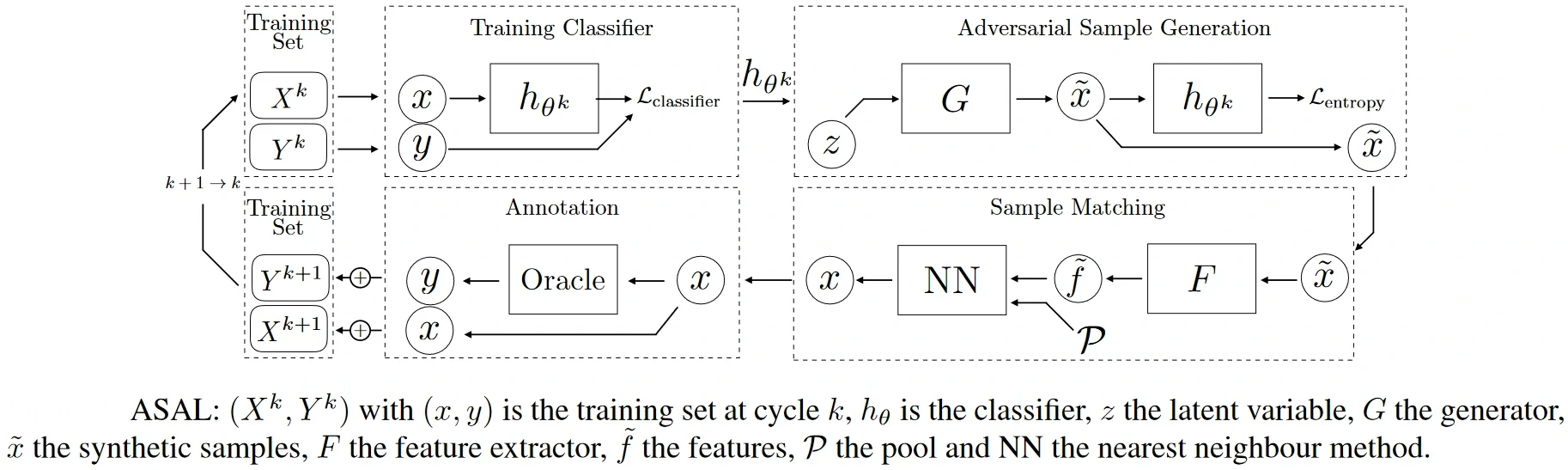
Source: Paper
Informativeness Measures
Several informativeness measures have been proposed to decide which samples in a batch (or data stream) to query the user. Let us discuss the most popular ones here.
Uncertainty-based Sampling
In an Uncertainty Sampling framework, an active learner queries the instances about which it is least certain how to label, i.e., the samples which lie close to the classification boundary. This approach is often straightforward for probabilistic learning models. For example, when using a probabilistic model for binary classification, uncertainty sampling simply queries the instance whose posterior probability of being positive is nearest 0.5. Alternatively, for multi-class problems, the network's confidence in prediction is used as the uncertainty measure.
Another common measure for uncertainty is entropy since the entropy measure does not favor instances where only one of the labels is highly unlikely because the model might be fairly certain that it is not the true label.
For example, Uncertainty Sampling with Diversity Maximization (USDM) is a multi-class active learning framework that leverages all the data in the active pool for uncertainty evaluation. USDM is able to globally evaluate the informativeness of the pool data across multiple classes, leading to a more accurate evaluation.
Also, in contrast to traditional Active Learning algorithms that merely consider the uncertainty score for active learning, USDM proposes to select the most uncertain data, which is as diverse as possible. It means that the data selected for labeling should be sufficiently different from each other.
USDM has been validated on different tasks—action recognition (on 2 datasets), object classification, and scene recognition. The results obtained by the authors from their experiments are shown below.
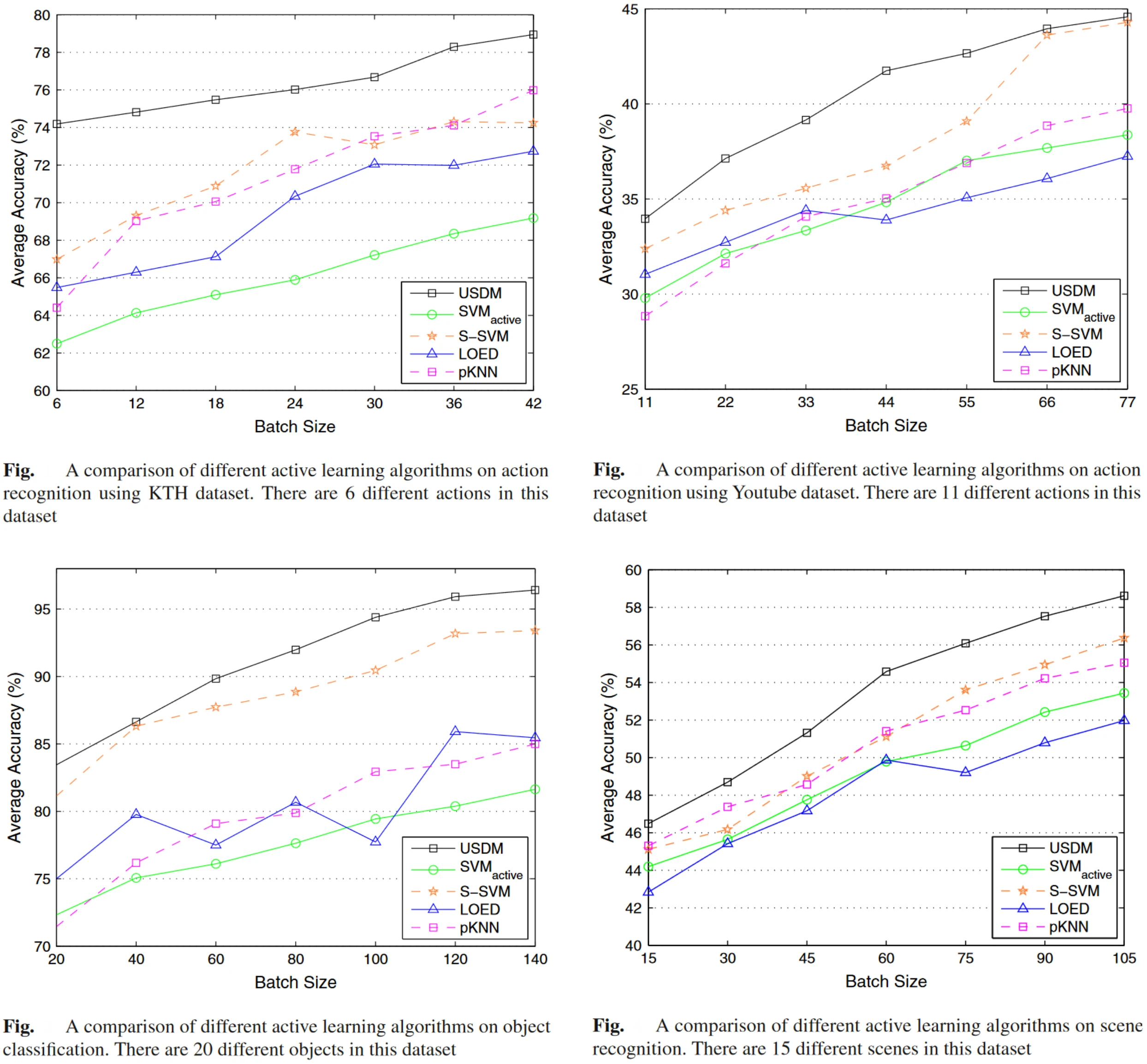
Source: Paper
Query-By-Committee Sampling
The Query-By-Committee (QBC) approach involves maintaining a committee of models which are all trained on the current labeled set but represent competing hypotheses. Each committee member is then allowed to vote on the labelings of query candidates. The most informative query is considered to be the instance about which they most disagree. This method is inspired by Ensemble Learning frameworks.
This paper proposes one example of this method, which developed a low computation adaptation of the Query-By-Committee strategy (QBC) for deep learning. Since deep architectures have a huge number of trainable parameters, training a committee of deep networks is infeasible. Instead, the authors train a Convolutional Neural Network (CNN) on a selection of training samples, but the selection is handled by a committee of partial CNNs. To build the committee, the authors use batch-wise dropout on the current full CNN in order to define as many partial CNNs as batch-wise dropout runs, thus reducing the computational cost of the standard QBC technique.
Results obtained by the authors on the MNIST and USPS classification datasets are shown below.
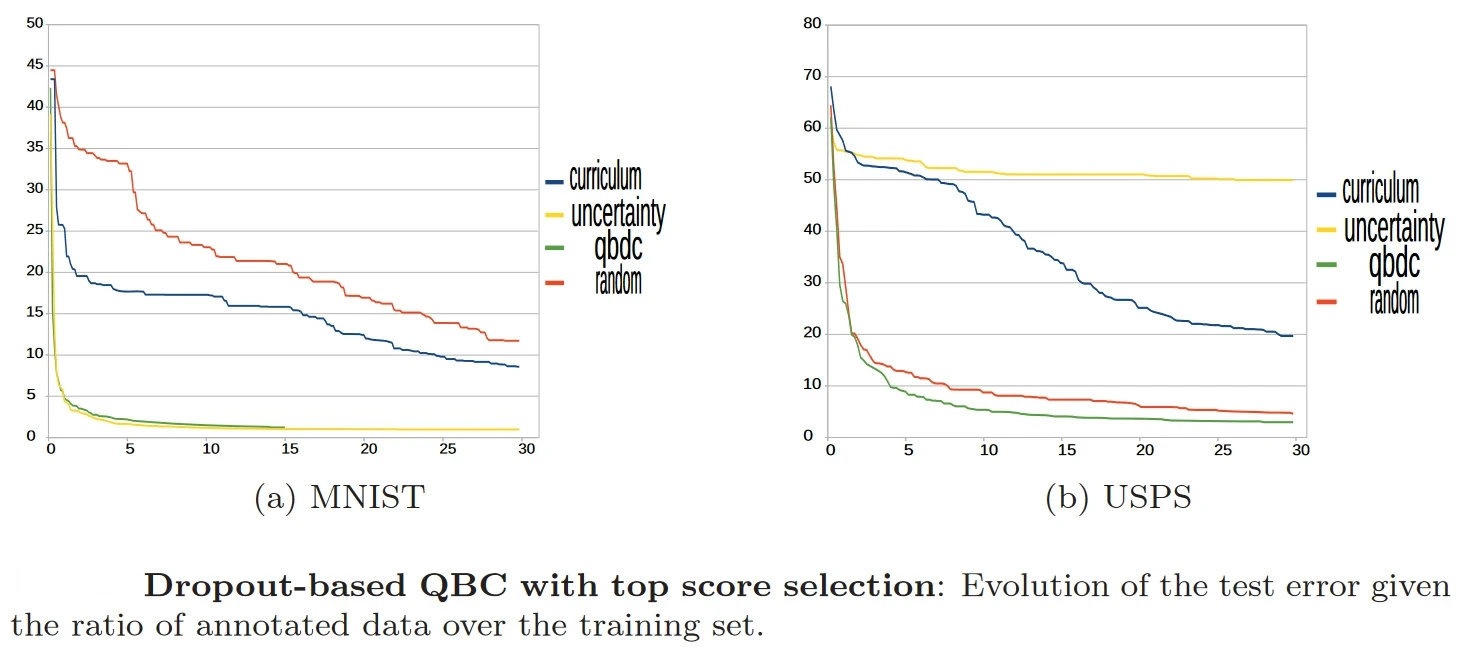
Source: Paper
Expected Model-change-based Sampling
Another general active learning framework uses a decision-theoretic approach, which involves selecting the instance that would impart the most significant change to the current model if we knew its label.
For example, this paper proposed a general active learning framework for regression problems by maximizing the model change. The authors proposed an Expected Model Change Maximization (EMCM) framework, which measures the change as the difference between the current model parameters and the new parameters trained with the enlarged labeled training set. The EMCM model uses the gradient of the error with respect to a candidate example to estimate the model change. An example of this is shown below.
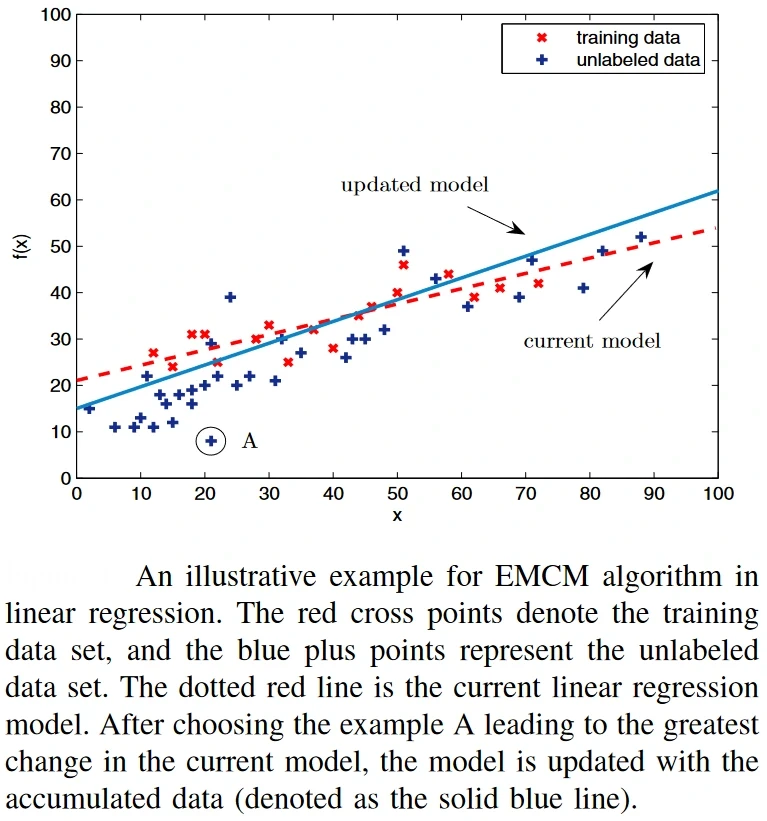
Source: Paper
Some results obtained by the EMCM algorithm with respect to contemporary state-of-the-art models are shown below.
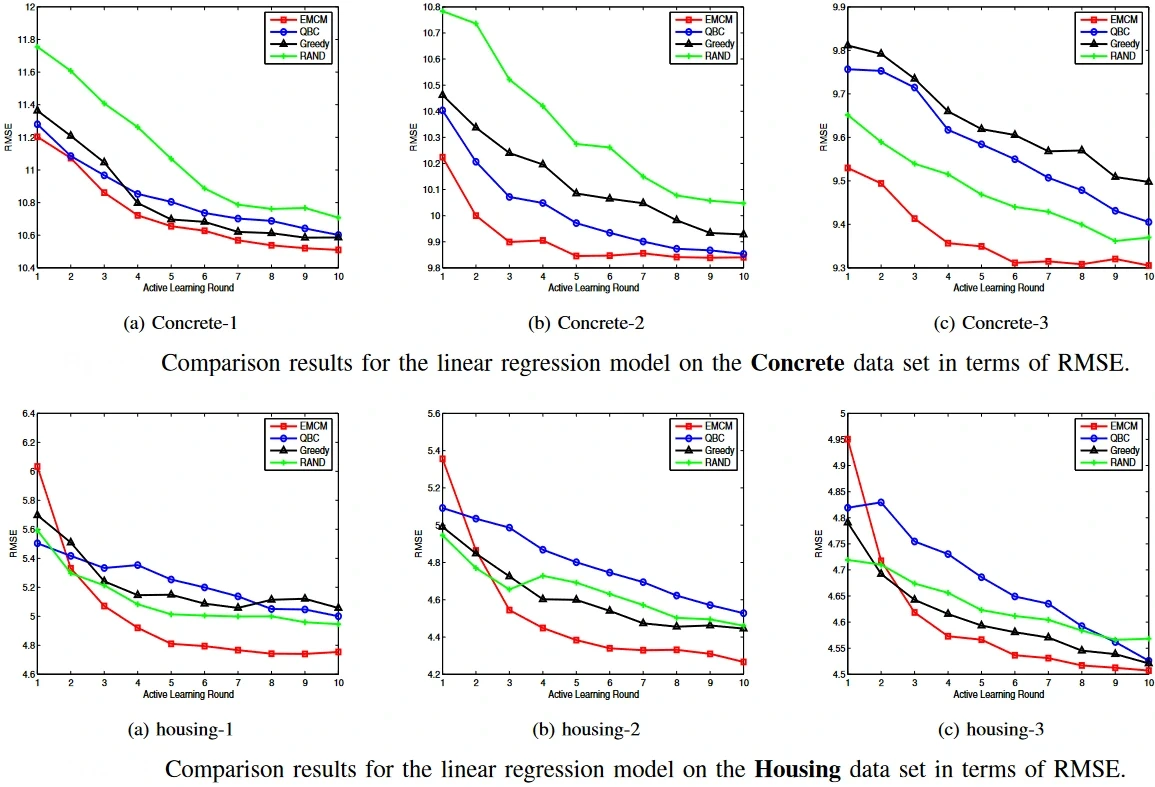
Source: Paper
Expected Error Reduction
Expected Error Reduction (EER) measures how much the generalization error is likely to be reduced rather than how much the model is likely to change like in the previous approach. The concept here is to estimate the expected future error of a model when trained with the existing labeled set, along with the sample that will be queried, on the remaining unlabeled samples. The instance with the minimal expected future error (called “risk”) is queried.
EER brings a huge time cost owing to its error reduction estimation. That is, for each datapoint, the classifier has to be re-optimized with its possible labels, and the labels of other data points need to be re-inferred to calculate its expected generalization error. This paper proposed a novel criterion called approximated error reduction (AER) to address this limitation. AER estimates the error reduction of a candidate based on an expected impact over all data points and an approximated ratio between the error reduction and the impact over its nearby data points.
Results obtained by the AER method on 6 datasets are shown below.
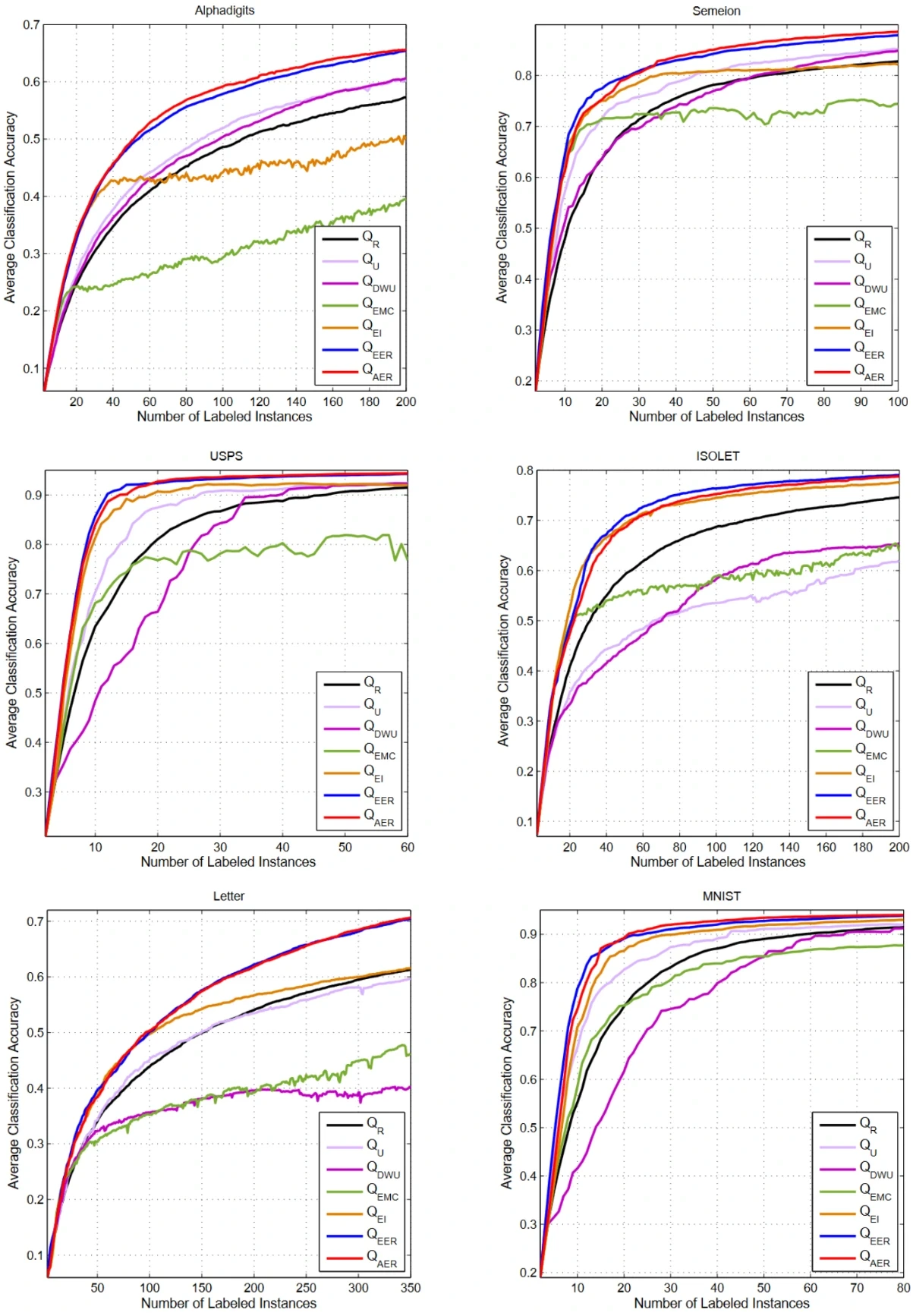
Source: Paper
Density-Weighted Methods
A central idea of the estimated error frameworks is that they focus on the entire input space rather than individual instances. Thus, they are less prone to querying outliers than more straightforward query strategies like uncertainty sampling and QBC approaches. The least certain instance lies on the classification boundary. However, it is not “representative” of other instances in the distribution, so knowing its label is unlikely to improve the accuracy of the data as a whole.
The main idea of Density-Weighted methods is that informative instances should be not only those which are uncertain but also those which are “representative” of the underlying distribution (i.e., inhabit dense regions of the input space).
To this end, this paper presents Suggestive Annotation, a deep active learning framework for medical image segmentation, which uses an alternative formulation of uncertainty sampling combined with a form of representativeness density weighting. Their method consists of training multiple models that each exclude a portion of the training data, which are used to calculate an ensemble-based uncertainty measure.
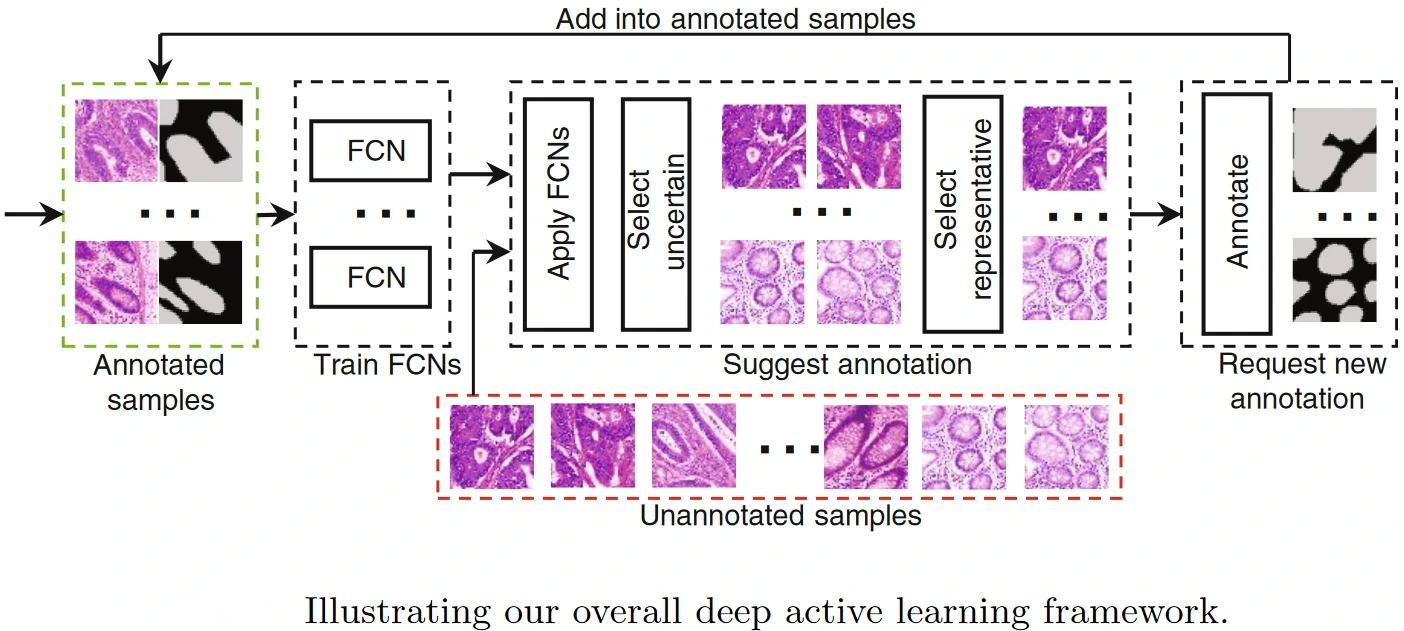
Source: Paper
An example showing the efficacy of the Density-Weighted method for the segmentation problem posed by the authors is shown below.

Source: Paper
Applications
Active Learning has widespread practical applications in all domains of Artificial Intelligence due to its ability to produce optimal performance even with few labeled samples. It is commonly used instead of traditional Supervised Learning, saving a lot of resources for ML teams. Let us look into some of them next.
Computer Vision
Computer Vision encompasses methods ranging from image classification and segmentation to object detection, image restoration, and enhancement. Active Learning is widely used in this field because of the vast amount of unlabeled data available through the internet. Let us explore some of these applications.
Image Classification
Image Classification is the process of determining the category/categories to which an image belongs. The CEAL or Cost-Effective Active Learning model, for example, employs Active Learning in the image classification problem, which, unlike typical approaches that consider only the most informative and representative samples, proposes to automatically select and pseudo-annotate unlabeled samples.
Samples from the unlabeled set are progressively passed to the CNN, which selects two kinds of samples for fine-tuning: (1) minority samples with low prediction confidence—these are the samples that are sent to the user for labeling since they are the most informative samples; (2) majority samples with high confidence—the predicted labels are assigned as the pseudo-labels. To update the model, both the already labeled set and the samples pseudo-labeled up until now are used for fine-tuning. The overall framework of the CEAL model is shown below.
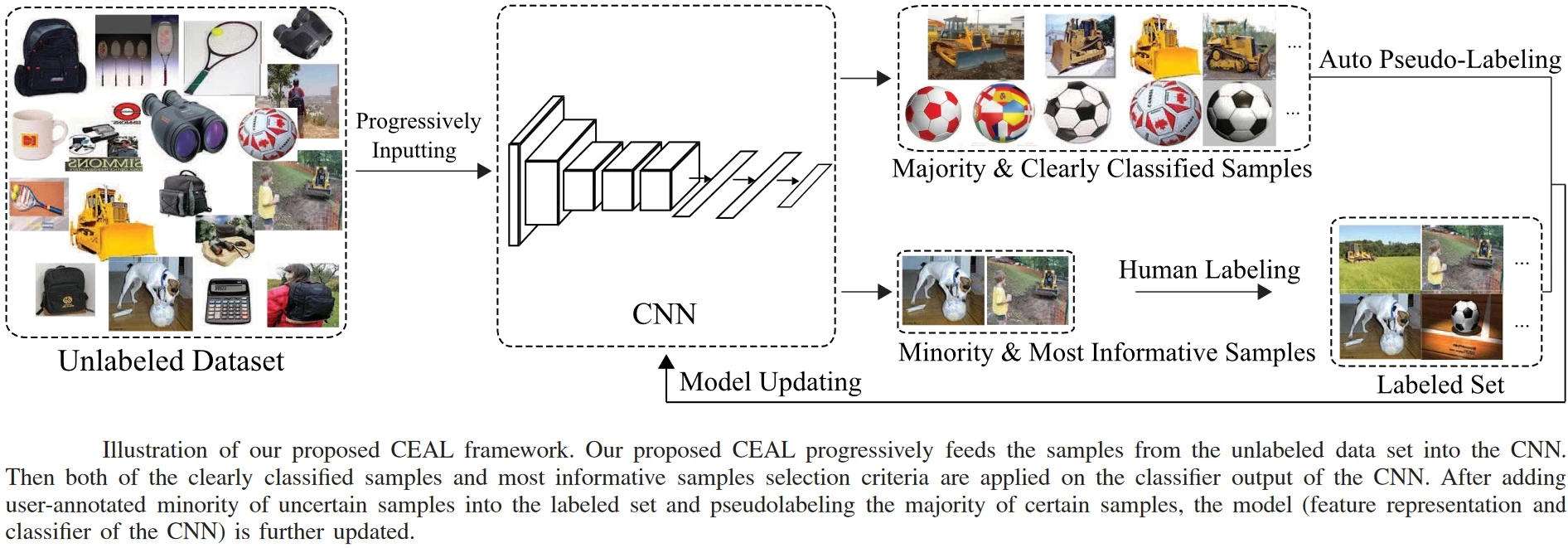
Object Detection
Object Detection is a Computer Vision method that deals with sifting out salient objects from an image. It is different from image classification in the sense that in image classification, the entirety of the image is assumed to belong to one class- say, “busy road.” However, in object detection, a single image comprises several local regions belonging to different classes—like “car,” “scooter,” or “pedestrian,” as shown below.

An example of Active Learning being used for the task of object detection is the MI-AOD or Multiple Instance Active Object Detection model. Using discrepancy learning and multiple instance learning, the MI-AOD model selects informative images from the unlabeled set to have the user's label. A feature pyramid network is used for the purpose of computing the uncertainty in the predictions of the unlabeled set. A schematic of the MI-AOD method compared to conventional Active Learning Object Detectors is shown below.
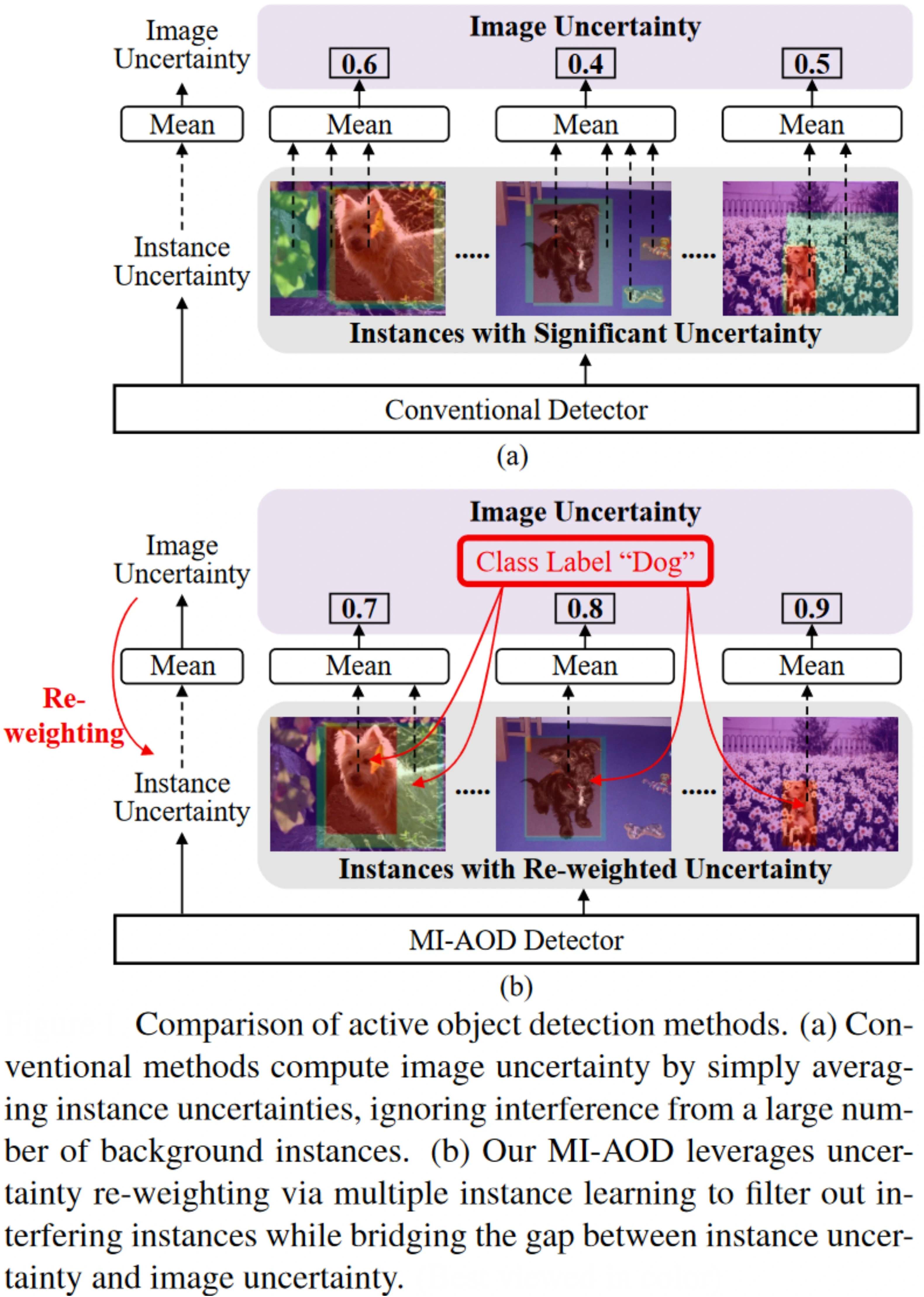
Some visual results obtained by the MI-AOD model on unlabeled images are shown below. The objects are detected in tight bounding boxes portraying the efficacy of the method.
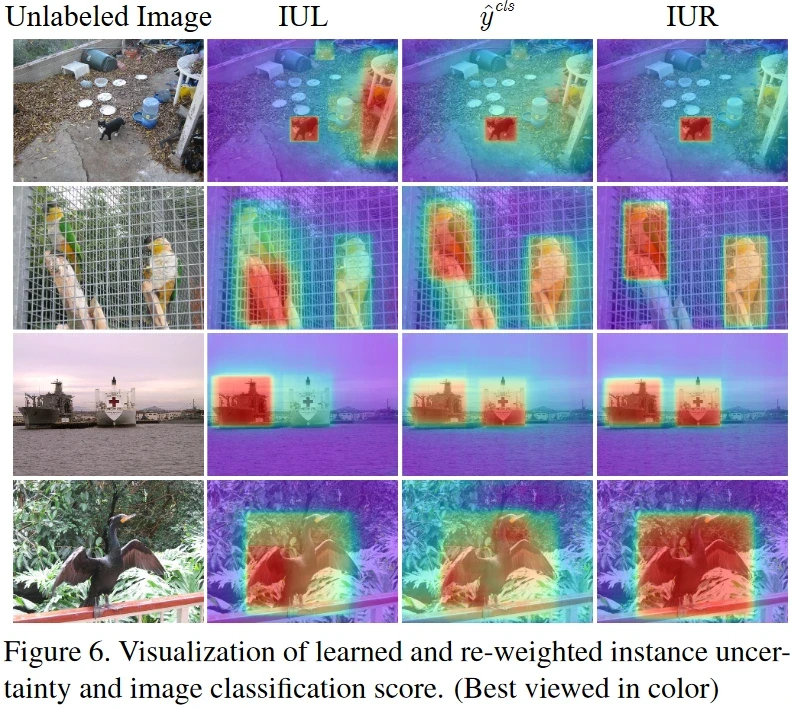
Image Restoration
Restoration of images is an important task in Computer Vision since photos can degrade due to several reasons—lossy image compression, noisy transfer of images through internet servers, etc. Different image restoration tasks include image inpainting, pixel interpolation, image deblurring, and image denoising.

An example of this is the method proposed in this paper, which addresses a wide variety of image restoration problems using one generalized model. On top of that, contrary to conventional models that only perform well for a particular fixed level of difficulty (called “Fixated” models), the authors proposed a deep network in an Active Learning setting that can perform optimally on all difficulty levels.
The authors use an on-demand learning solution for training general deep networks across varied difficulty levels. The approach relies on a feedback mechanism, where at each epoch, the model guides its own learning towards the right proportion of sub-tasks per difficulty level. In this way, the system itself can discover which sub-tasks deserve more or less attention. The architecture of the deep network proposed by the authors is shown below.
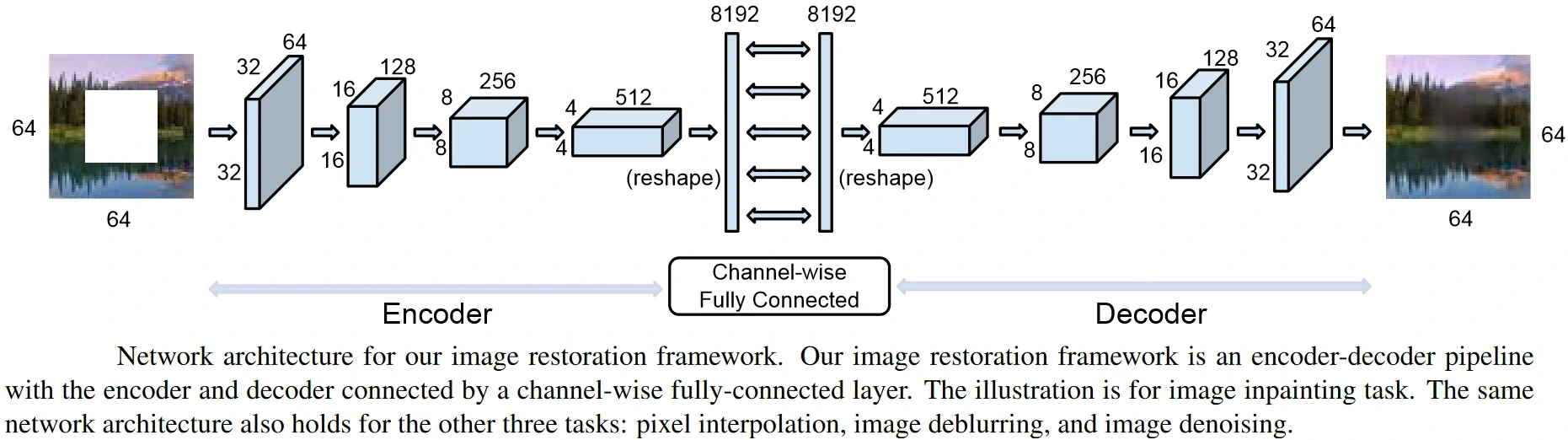
Examples of qualitative results obtained by the method proposed on different image restoration tasks are shown and compared with different models below. Clearly, the active learning procedure presented better results than Fixated models, which only perform well for specific difficulty levels.

Natural Language Processing
Natural Language Processing (NLP) is a branch of Artificial Intelligence that can comprehend natural human language (text in most cases). This includes tasks like text completion, text emotion recognition, etc. Active Learning has been popularly used for different NLP tasks in the last decade as well, owing to its massive success in Computer Vision.
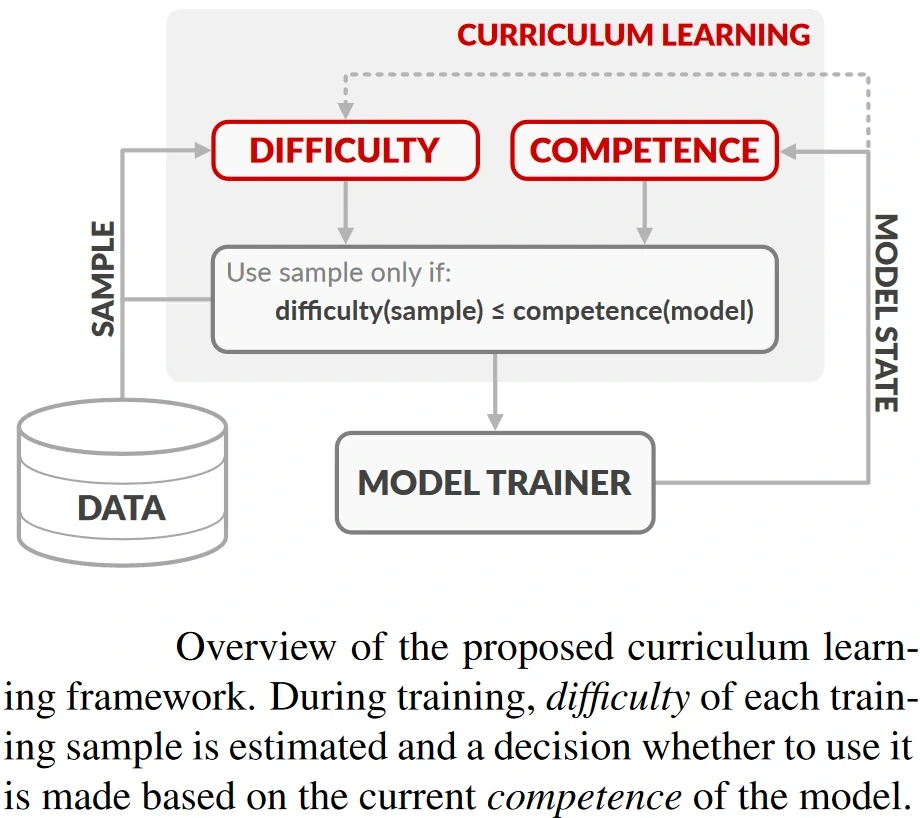
For example, this paper used Active Learning to address the Neural Machine Translation (NMT) problem, which deals with using deep learning models for translating text from one language to another. The authors developed a Curriculum Learning framework (a learning paradigm that trains a model from easy samples first and then progressively provides harder samples) to train their model.
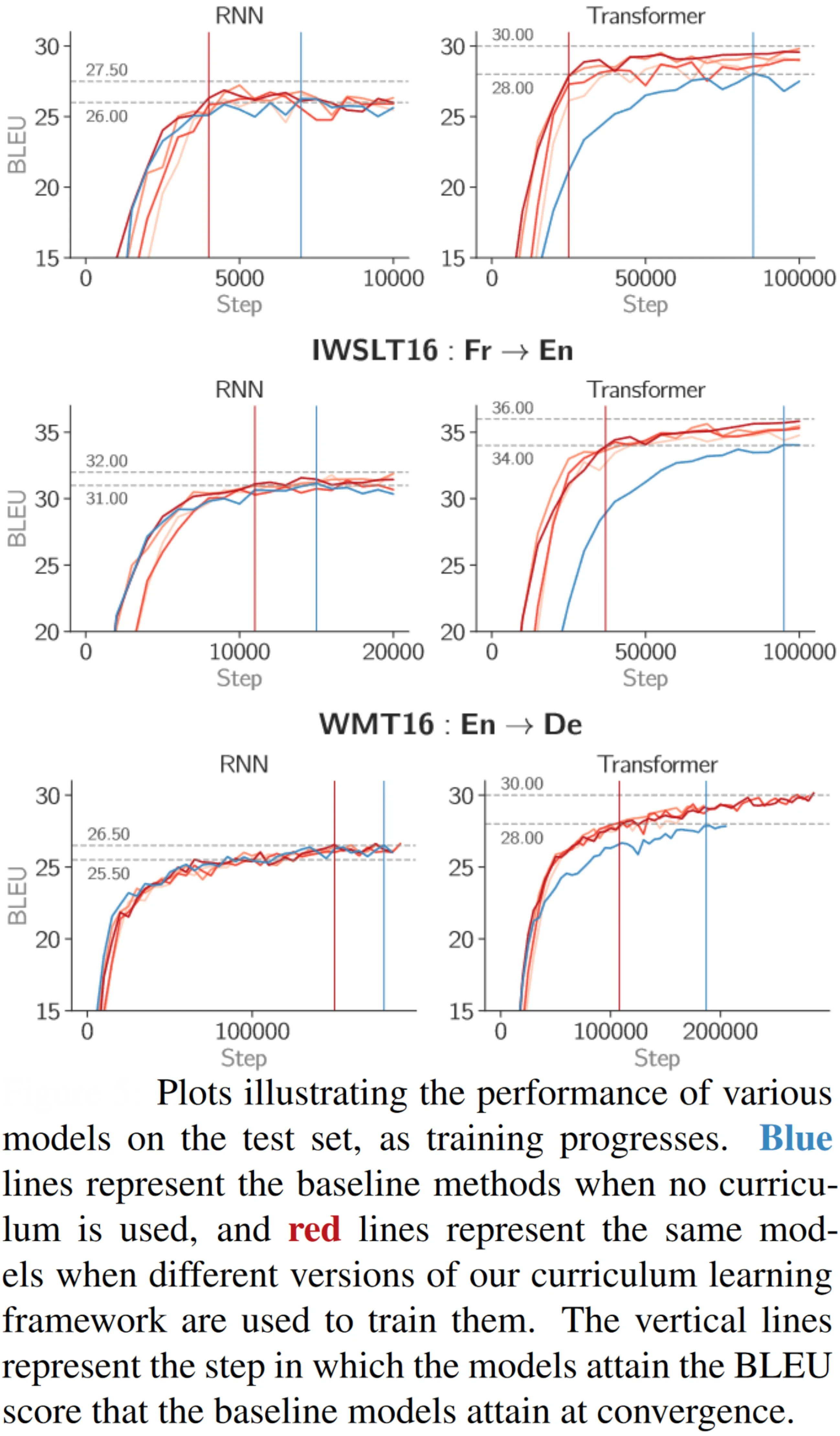
The motivation for Curriculum Learning is that training algorithms can perform better if training data is presented in a specific order, starting from easy examples and moving on to more difficult ones, as the learner becomes more competent. The authors experiment not only with Recurrent Neural Networks but also with Transformer networks which are much harder to train. The authors found that using Curriculum Learning speeds up network convergence and also increases model performance. The schematic of the framework proposed by the authors is shown below.
Some of the results obtained by the authors are shown below.
Audio Processing
Audio processing includes important automated tasks like spoken language identification (which is important in multilingual applications), audio completion, audio synthesis, etc. For example, this paper addressed the speech recognition problem using Active Learning.
The authors proposed a loss prediction module on active learning to try leveraging the loss information computed on all path probabilities to address the Automatic Speech Recognition and Loss Prediction joint model in an end-to-end framework. The loss prediction module aims to learn a good prediction model for a length normalized ranking metric of data selection. Their loss prediction-based active learning framework is schematically represented below.
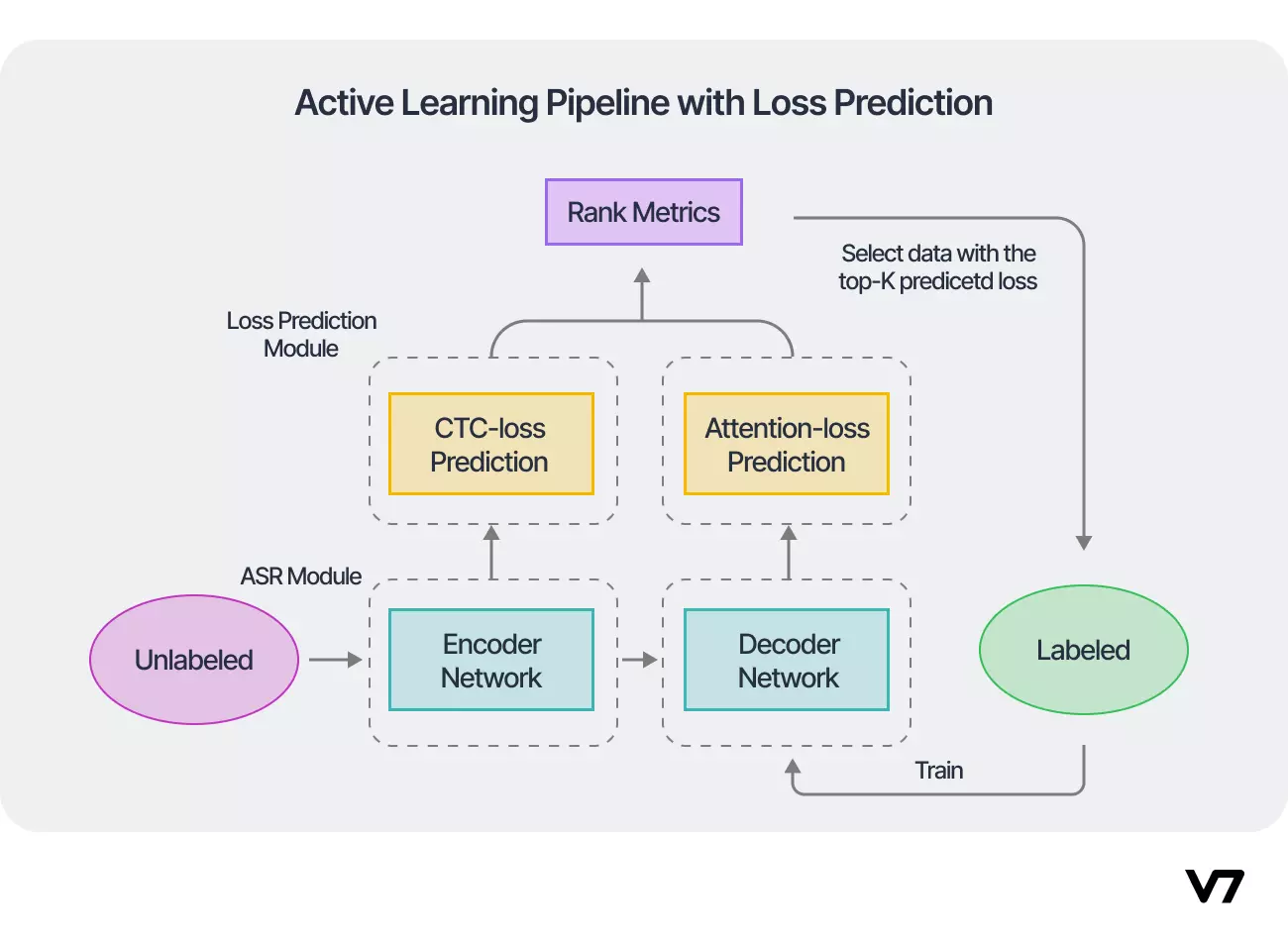
The loss prediction model proposed by the authors performed better than contemporary state-of-the-art active learning models, as shown below.
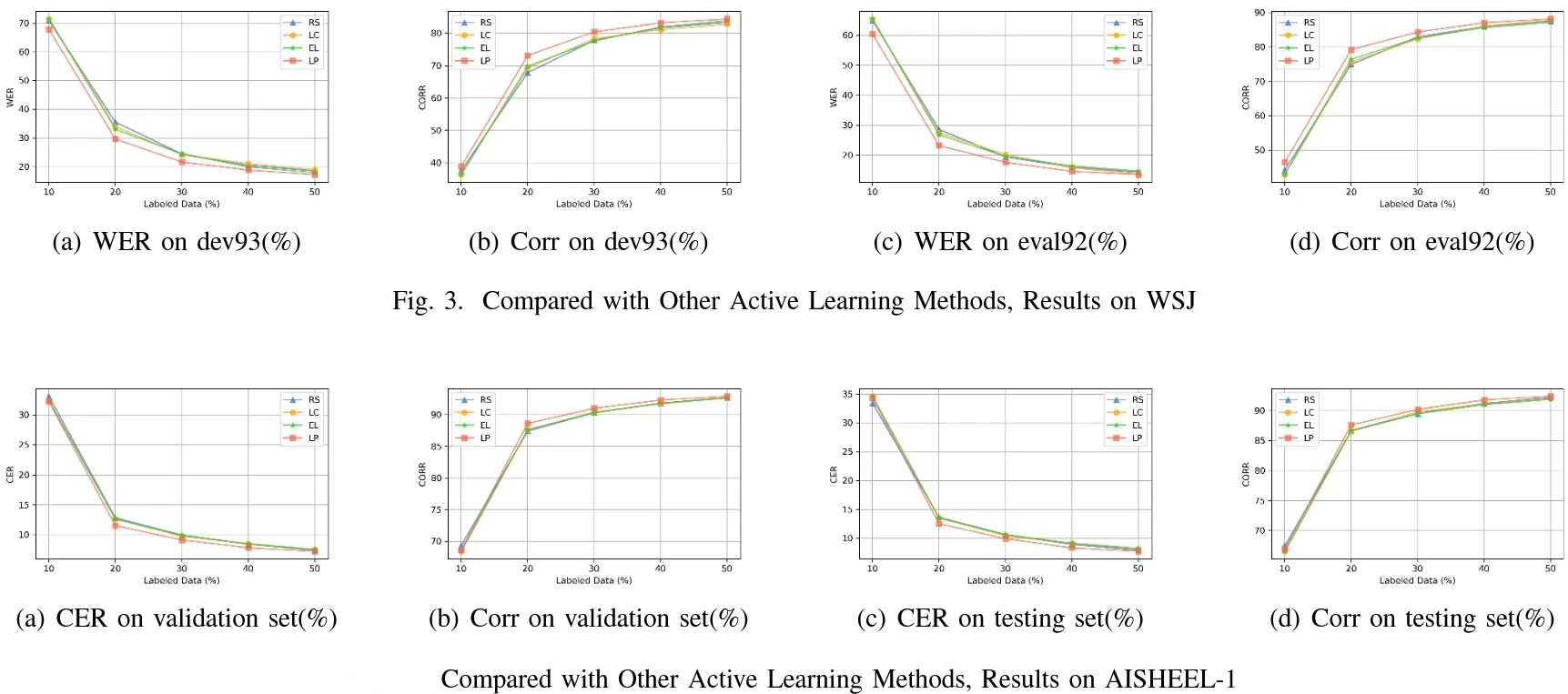
Conclusion
Since its inception, Deep Learning has revolutionized solutions to Computer Vision problems. However, the availability of quality labeled data is the primary bottleneck restricting applications in several domains (like biomedicine). Although data labels are not readily available, unstructured data are plentiful in this era of Information Technology, which calls for the need for an efficient Semi-Supervised approach that can utilize this large pool of unlabeled data along with a handful of labeled samples.
Active Learning is the solution to this, which, inspired by the Reinforcement Learning literature, lets the machine autonomously decide which sample from the pool of unlabeled data points a user can label for it to provide better predictive performance. Strategies to judge the importance of labeling samples are abundant, each with its own set of pros and cons.
Active Learning has proven successful not only in complex Computer Vision tasks like image segmentation, scene recognition, etc. but also in other paradigms of Artificial Intelligence like NLP and speech processing. Research on Active Learning strategies now focuses on requiring even lesser labeled samples (or choosing the optimal sample with lesser computational cost) while maintaining predictive performance close to or better than traditional Supervised Learning methods.
If you’re interested in other articles on related topics, have a look at these: