Computer vision
What Is Computer Vision? [Basic Tasks & Techniques]
16 min read
—

From self driving cars, through defect detection to medical imaging—here's how computer vision is helping modern businesses to solve complex visual tasks.

Hmrishav Bandyopadhyay
Guest Author

Let's start with a simple question: What do you see on this page?
There is a a table of contents on your left, my name and headshot right above, and the wall of text that you are now reading.
I bet that you noticed all of that without even thinking about it. It also probably took you less than 3 seconds.
But—
Things aren't that fast and easy when it comes to machines.
Enabling computers to see the world in the same way humans do is still a complex challenge that data scientists work hard on resolving.
Luckily, there's also good news—
The computer vision field has been rapidly developing, finding real-world applications, and even surpassing humans in solving some of the visual tasks. All of this thanks to the recent advances in artificial intelligence and deep learning.
Computer vision can solve a variety of problems in business, science, and healthcare. With the right training data, you can create anything from AI that can detect cancer cells to AI that can read financial statements.
So, in case you are still confused about this whole computer vision thing, in this article we will walk you through the most important concepts.
Here’s what we’ll cover:
What is computer vision?
How does computer vision work?
7 common computer vision tasks
Computer vision challenges
8 real-world computer vision applications
Let’s get started.

Video annotation
AI video annotation
Get started today
Ready to streamline AI product deployment right away? Check out:
What is computer vision?
Computer Vision is a subfield of Deep Learning and Artificial Intelligence where humans teach computers to see and interpret the world around them.
While humans and animals naturally solve vision as a problem from a very young age, helping machines interpret and perceive their surroundings via vision remains a largely unsolved problem.
Limited perception of the human vision along with the infinitely varying scenery of our dynamic world is what makes Machine Vision complex at its core.

A brief history of computer vision
Like all great things in the world of technology, computer vision started with a cat.
Two Swedish scientists, Hubel and Wiesel, placed a cat in a restricting harness and an electrode in its visual cortex. The scientists showed the cat a series of images through a projector, hoping its brain cells in the visual cortex would start firing.


With no avail with images, the eureka moment happened when a projector slide was removed, and a single horizontal line of light appeared on the wall—
Neurons fired, emitting a crackling electrical noise.
The scientists had just realized that the early layers of the visual cortex respond to simple shapes, like lines and curves, much like those in the early layers of a deep neural network.
They then used an oscilloscope to create these and observe the brain’s reaction.


Computer vision vs. human vision
The notion that machine vision must be derived from the animal vision was predominant as early as 1959—when the neurophysiologists mentioned above tried to understand cat vision.
Since then, the history of computer vision is dotted with milestones formed by the rapid development of image capturing and scanning instruments complemented by state-of-the-art image processing algorithms’ design.
The 1960s saw the emergence of AI as an academic field of study, followed by the development of the first robust Optical Character Recognition system in 1974.
By the 2000s, the focus of Computer Vision has been shifted to much more complex topics, including:
Object identification
Facial recognition
Image Segmentation
Image Classification
And more—
All of them have achieved commendable accuracies over the years.
The year 2010 saw the birth of the ImageNet dataset with millions of labeled images freely available for research. This led to the formation of the AlexNet architecture two years later— making it one of the biggest breakthroughs in Computer Vision, cited over 82K times.
Image Processing as a Part of Computer Vision
Digital Image Processing, or Image Processing, in short, is a subset of Computer Vision. It deals with enhancing and understanding images through various algorithms.
More than just a subset, Image Processing forms the precursor of modern-day computer vision, overseeing the development of numerous rule-based and optimization-based algorithms that have led machine vision to what it is today.
Image Processing may be defined as the task of performing a set of operations on an image based on data collected by algorithms to analyze and manipulate the contents of an image or the image data.
Now that you know the theory behind computer vision let’s talk about its practical side.
How does computer vision work?
Here’s a simple visual representation that answers this question on the most basic level.

However—
While the three steps outlining the basics of computer vision seem easy, processing and understanding an image via machine vision are quite difficult. Here’s why—
An image consists of several pixels, with a pixel being the smallest quanta in which the image can be divided into.
Computers process images in the form of an array of pixels, where each pixel has a set of values, representing the presence and intensity of the three primary colors: red, green, and blue.
All pixels come together to form a digital image.
The digital image, thus, becomes a matrix, and Computer Vision becomes a study of matrices. While the simplest computer vision algorithms use linear algebra to manipulate these matrices, complex applications involve operations like convolutions with learnable kernels and downsampling via pooling.
Below is an example of how a computer “sees” a small image.

The values represent the pixel values at the particular coordinates in the image, with 255 representing a complete white point and 0 representing a complete dark point.
For larger images, matrices are much larger.
While it is easy for us to get an idea of the image by looking at it, a peek at the pixel values shows that the pixel matrix gives us no information on the image!
Therefore, the computer has to perform complex calculations on these matrices and formulate relationships with neighboring pixel elements just to say that this image represents a person’s face.
Developing algorithms for recognizing complex patterns in images might make you realize how complex our brains are to excel at pattern recognition so naturally.
Pro tip: Are you looking for quality training data? Check out 65+ free datasets for machine learning.
Some operations commonly used in computer vision based on a Deep Learning perspective include:
Convolution: Convolution in computer vision is an operation in which a learnable kernel is “convolved” with the image. In other words—the kernel is slided across the image pixel by pixel, and an element-wise multiplication is performed between the kernel and the image at every pixel group.
Pooling: Pooling is an operation used to reduce the dimensions of an image by performing operations at a pixel level. A pooling kernel slides across the image, and only one pixel from the corresponding pixel group is selected for further processing, thus reducing the image size., eg., Max Pooling, Average Pooling.
Non-Linear Activations: Non-Linear activations introduce non-linearity to the neural network, thereby allowing the stacking of multiple convolutions and pooling blocks to increase model depth.
Pro tip: Here's a quick recap of 12 Types of Neural Network Activation Functions.
7 common computer vision tasks
In essence, computer vision tasks are about making computers understand digital images as well as visual data from the real world. This can involve extracting, processing, and analyzing information from such inputs to make decisions.
The evolution of machine vision saw the large-scale formalization of difficult problems into popular solvable problem statements.
Division of topics into well-formed groups with proper nomenclature helped researchers around the globe identify problems and work on them efficiently.
The most popular computer vision tasks that we regularly find in AI jargon include:

Image classification
Image classification is one of the most studied topics ever since the ImageNet dataset was released in 2010.
Being the most popular computer vision task taken up by both beginners and experts, image classification as a problem statement is quite simple.
Given a group of images, the task is to classify them into a set of predefined classes using solely a set of sample images that have already been classified.
As opposed to complex topics like object detection and image segmentation, which have to localize (or give positions for) the features they detect, image classification deals with processing the entire image as a whole and assigning a specific label to it.
Object detection
Object detection, as the name suggests, refers to detection and localization of objects using bounding boxes.
Object detection looks for class-specific details in an image or a video and identifies them whenever they appear. These classes can be cars, animals, humans, or anything on which the detection model has been trained.
Previously methods of object detection used Haar Features, SIFT, and HOG Features to detect features in an image and classify them based on classical machine learning approaches.
Pro tip: Looking for the perfect bounding box tool? Check out 9 Essential Features for a Bounding Box Annotation Tool.
This process, other than being time-consuming and largely inaccurate, has severe limitations on the number of objects that can be detected.
As such, Deep Learning models like YOLO, RCNN, SSD that use millions of parameters to break through these limitations are popularly employed for this task.
Object detection is often accompanied by Object Recognition, also known as Object Classification.
Image segmentation
Image segmentation is the division of an image into subparts or sub-objects to demonstrate that the machine can discern an object from the background and/or another object in the same image.
A “segment” of an image represents a particular class of object that the neural network has identified in an image, represented by a pixel mask that can be used to extract it.
Pro tip: Read The Beginner’s Guide to Semantic Segmentation to learn more.
This popular domain of Computer Vision has been studied widely both with the use of traditional image processing algorithms like watershed algorithms, clustering-based segmentation and with the use of popular modern-day deep learning architectures like PSPNet, FPN, U-Net, SegNet, etc.

Face and person recognition
Facial Recognition is a subpart of object detection where the primary object being detected is the human face.
While similar to object detection as a task, where features are detected and localized, facial recognition performs not only detection, but also recognition of the detected face.

Facial recognition systems search for common features and landmarks like eyes, lips, or a nose, and classify a face using these features and the positioning of these landmarks.
Traditional Image Processing based methods for facial recognition include Haar Cascades, which is easily accessible via the OpenCV library. Some more robust methods using Deep Learning based algorithms can be found in papers like FaceNet.
Pro tip: Would you like to build your own facial recognition dataset? Check out 13 Best Image Annotation Tools to choose the best tool for your needs.
Edge detection
Edge detection is the task of detecting boundaries in objects.
It is algorithmically performed with the help of mathematical methods that help detect sharp changes or discontinuities in the brightness of the image. Often used as a data pre-processing step for many tasks, edge detection is primarily done by traditional image processing-based algorithms like Canny Edge detection and by convolutions with specially designed edge detection filters.
Furthermore, edges in an image give us paramount information about the image contents, resulting in all deep learning methods performing edge detection internally for the capture of global low-level features with the help of learnable kernels.
Pro tip: Check out 15+ Top Computer Vision Project Ideas for Beginners to start building your own computer vision models in less than an hour.
Image Restoration
Image Restoration refers to the restoration or the reconstruction of faded and old image hard copies that have been captured and stored in an improper manner, leading to loss of quality of the image.

Typical image restoration processes involve the reduction of additive noise via mathematical tools, while at times, reconstruction requires major changes, leading to further analysis and the use of image inpainting.
In Image inpainting, damaged parts of an image are filled with the help of generative models that make an estimate of what the image is trying to convey. Often the restoration process is followed by a colorization process that colors the subject of the picture (if black and white) in the most realistic manner possible.
Pro tip: Want to learn more about image restoration techniques? Read An Introduction to Autoencoders: Everything You Need to Know.
Feature matching
Features in computer vision are regions of an image that tell us the most about a particular object in the image.
While edges are strong indicators of object detail and. therefor,e important features, much more localized and sharp details—like corners, also serve as features. Feature matching helps us to relate the features of similar region of one image with those of another image.
The applications of feature matching are found in computer vision tasks like object identification and camera calibration. The task of feature matching is generally performed in the following order:
Detection of features: Detection of regions of interest is generally performed by Image Processing algorithms like Harris Corner Detection, SIFT, and SURF.
Formation of local descriptors: After features are detected, the region surrounding each keypoint is captured and the local descriptors of these regions of interest are obtained. A local descriptor is the representation of a point’s local neighborhood and thus can be helpful for feature matching.
Feature matching: The features and their local descriptors are matched in the corresponding images to complete the feature matching step.

Scene reconstruction
One of the most complex problems of computer vision, scene reconstruction is the digital 3D reconstruction of an object from a photograph.
Most algorithms in scene reconstruction roughly work by forming a point cloud at the surface of the object and reconstructing a mesh from this point cloud.
Video motion analysis
Video motion analysis is a task in machine vision that refers to the study of moving objects or animals and the trajectory of their bodies.
Motion analysis as a whole is a combination of many subtasks, particularly object detection, tracking, segmentation, and pose estimation.
While human motion analysis is used in areas like sports, medicine, intelligent video analytics, and physical therapy, motion analysis is also used in other areas like manufacturing and to count and track microorganisms like bacteria and viruses.
Computer vision technology challenges
One of the biggest challenges in machine vision is our lack of understanding of how the human brain and the human visual system works.
We have an enhanced and complex sense of vision that we can figure out at a very young age but are unable to explain the process by which we can understand what we see.
Furthermore, day-to-day tasks like walking across the street at the zebra crossing, pointing at something in the sky, checking out the time on the clock, require us to know enough about the objects around us to understand our surroundings.
Such aspects are quite different from simple vision, but are largely inseparable from it. The simulation of human vision via algorithms and mathematical representation thus requires the identification of an object in an image and an understanding of its presence and its behaviour.





7 real-world computer vision applications
Finally, let's discuss some of the most common computer vision use cases.
Self-driving cars
Probably one of the most popular applications of computer vision right now is the self-driving car. With companies like Tesla coming up with innovative models of autonomous vehicles, it's becoming clear that this industry will play an important role in fueling the development of new computer vision algorithms.
Pro tip: You can use V7 auto-annotator tool to easily annotate your data frame by frame.

Augmented reality
Augmented reality (AR) is a method of providing an experience of the natural surroundings with a computer-generated augmentation appropriate to the surroundings. With the help of computer vision, AR can be virtually limitless, with augmentations providing translations of written text and applying filters to objects in the world we see, directly when we see them.
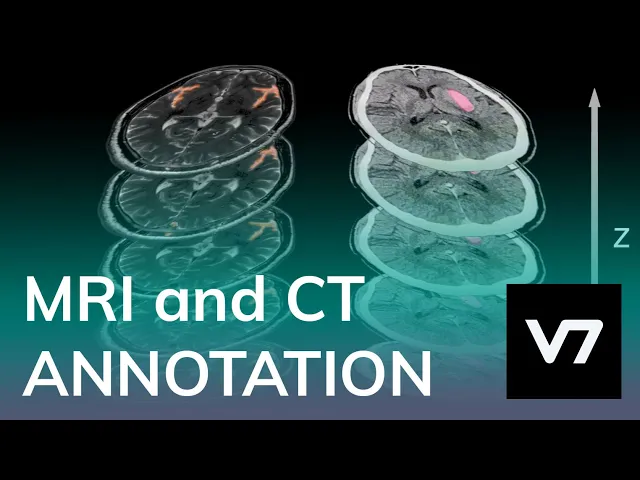
Medical imaging
Medical Imaging is an important and relevant subdiscipline of computer vision where images of X-rays and 3D scans like MRIs are classified into diseases like pneumonia and cancer.

Pro tip: Check out 21+ Best Healthcare Datasets for Computer Vision if you are looking for medical data.
Early diagnosis of diseases made possible with computer vision can save thousands of lives.
Here's how you can annotate your medical data using V7.
Intelligent Video Analytics
Computer Vision has been used to develop state of the art algorithms for the monitoring of security cameras via methods like pose estimation, face and person detection and object tracking.
Object detection is used in intelligent video analytics (IVA) anywhere CCTV cameras are present—in retail venues to understand how shoppers are interacting with products, in factories, airports and transport hubs to track queue lengths and access to restricted areas.

Manufacturing and Construction
Computer vision is an integral part of manufacturing industries that are striving to automate their processes with a range of AI systems, such as freight invoice automation, as well as visual tasks.
With the development of computer vision systems like defect detection and safety inspections, the quality of the manufactured goods increases.
Furthermore 3D vision systems enable efficient inspections to be carried out in a production line that would not be possible by humans.

OCR
One of the oldest applications of computer vision is optical character recognition.
With simple optical character recognition algorithms being experimented on as early as 1974, today, OCR is at a much-advanced state with Deep Learning systems being developed that can detect and translate text in natural environments and random places without human supervision.

Applying computer vision technology, low compute efficient OCR systems have been developed that can function even in smartphones and mobile devices.
Here's how you can perform OCR using V7's Text Scanner.
See here for a full guide to the best AI OCR software.
Retail
Computer vision in retail can potentially transform customer experience by huge standards. With AI stores like “amazon-go” springing up throughout the US, retail seems to be possibly the most revolutionizing stop for computer vision.

Pro tip: Check out Autonomous Retail with V7 to learn how computer vision can be applied in this industry.
Computer vision in a nutshell: Key Takeaways
Let's do a quick recap of everything we've learned in this computer vision guide:
Computer Vision is a subfield of Deep Learning and Artificial Intelligence that enables computers to see and interpret the world around them.
Applying computer vision technology isn't new—it dates back to the 1950s.
In its most basic form, computer vision is about acquiring, processing, and understanding an image.
Some of the common e computer vision problems include image classification, object localization and detection, and image segmentation.
Computer vision applications include fields like: facial recognition technology, medical image analysis, self-driving cars, and intelligent video analytics.
Nowadays, a computer vision system can surpass a human vision system.
Read next:
An Introductory Guide to Quality Training Data for Machine Learning
What is Data Labeling and How to Do It Efficiently [Tutorial]
A Comprehensive Guide to Convolutional Neural Networks
The Complete Guide to CVAT—Pros & Cons
YOLO: Real-Time Object Detection Explained
The Beginner’s Guide to Contrastive Learning
9 Reinforcement Learning Real-Life Applications
Mean Average Precision (mAP) Explained: Everything You Need to Know
A Step-by-Step Guide to Text Annotation [+Free OCR Tool]
The Essential Guide to Data Augmentation in Deep Learning
Knowledge Distillation: Principles & Algorithms [+Applications]

Hmrishav Bandyopadhyay
Hmrishav Bandyopadhyay studies Electronics and Telecommunication Engineering at Jadavpur University. He previously worked as a researcher at the University of California, Irvine, and Carnegie Mellon Univeristy. His deep learning research revolves around unsupervised image de-warping and segmentation.









