Computer vision
Video Classification: Methods, Use Cases, Tutorial
19 min read
—
Mar 14, 2023

What are the different techniques used for video classification? What are its greatest challenges and how to overcome them? And how to build a video classifier? Let's find out.

Guest Author
With the rapid growth of video content on the internet, video classification has become an important task in computer vision. From identifying a person's actions in a surveillance video to understanding video's content for video retrieval and recommendation, video classification has a wide range of applications for many industries.
In this article, we will explore the different techniques used for video classification. We will also discuss the challenges that come with video classification and how to overcome them. Whether you are a computer vision researcher, a machine learning engineer, or just someone interested in the topic, this article will come in handy.
In this article, we’ll cover:
What is video classification?
Video classification datasets
Video classification methods
Video classification use cases
How to build a video classifier with V7?
And if you’d like to start annotating your videos right away, check out:
What is video classification?
Video classification is a rapidly growing field in computer vision and machine learning. Much like image classification, video classification involves sorting videos into respective categories, such as actions being performed (e.g., dancing, walking, running) or behavioral emotions (e.g., cheerful, sad, surprised).
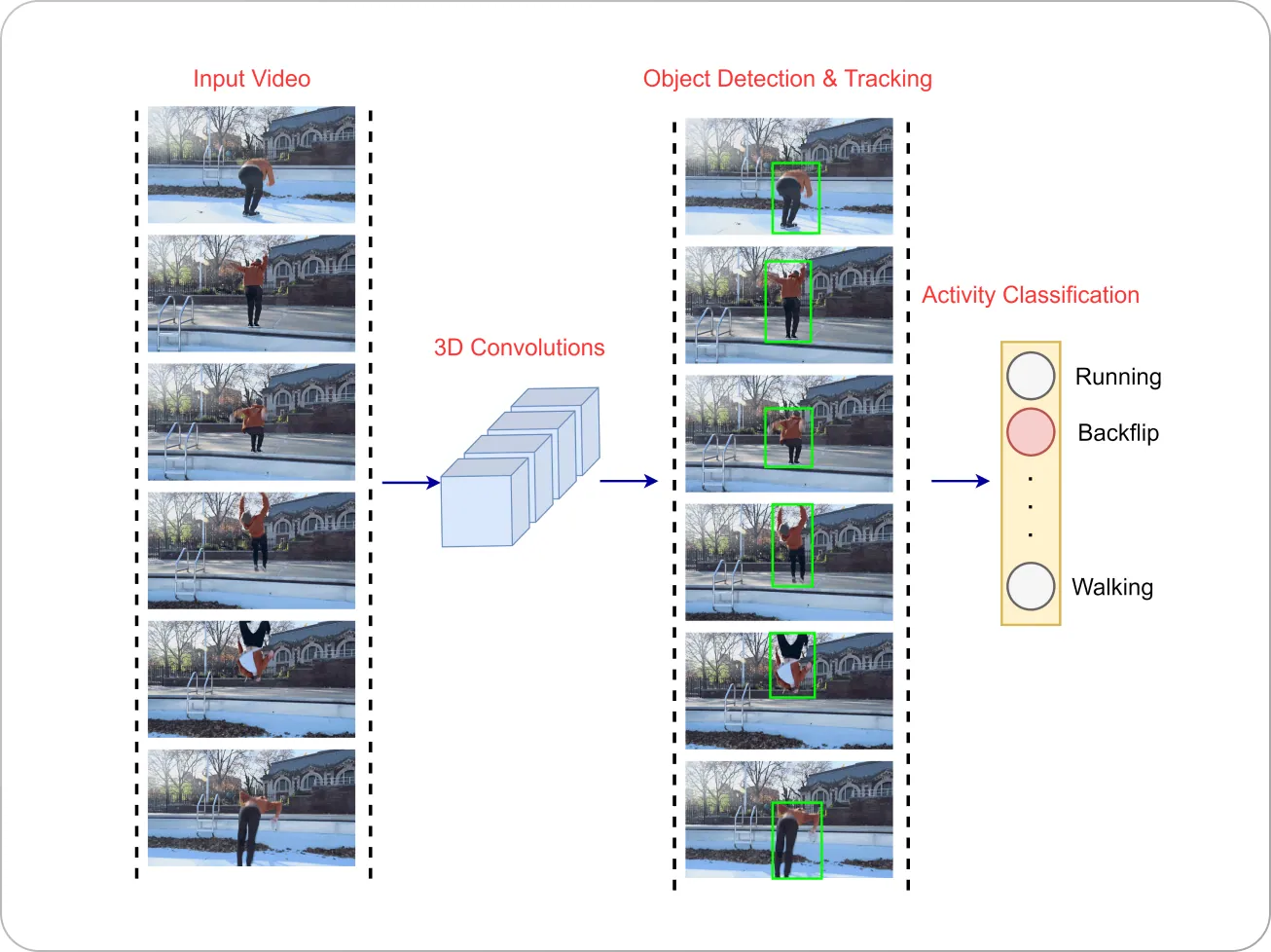
However, while images are classified based on the spatial content (e.g., a picture of a person vs. a picture of a dog), videos need to be classified based on both their spatial and temporal (time-domain) content—since two videos can contain the same person (same spatial information) performing different actions (difference in temporal content).
One of the key challenges in video classification is the sheer volume of data that must be processed. A video typically consists of a large number of frames, each containing a wealth of information. To make matters even more complicated, videos can also be shot in different lighting conditions, from different angles, and at different frame rates. Here are the most common video classification challenges:
Scalability: As the volume of video data continues to grow, it is becoming increasingly challenging to process and classify all of it in a reasonable amount of time. This is particularly problematic for deep learning approaches, which require large amounts of data and computational resources to train.
Generalization: Many video classification algorithms are designed to work on a specific dataset or task but may not generalize well to other datasets or tasks.
Video annotation: Labeling large amounts of video data is a time-consuming and labor-intensive task. This can make it difficult to obtain large, high-quality datasets for training and evaluating video classification algorithms—especially supervised learning models.
Privacy and security: The use of video data raises a number of privacy and security concerns, particularly when it comes to surveillance and facial recognition. There are also concerns about the potential misuse of video data, such as in the case of DeepFake videos.
Video quality: Videos can come in various qualities and formats, which can be difficult to handle and may adversely affect the performance of the video classifier.
To overcome these challenges, a variety of techniques and algorithms have been developed for video classification, most of which use deep learning for automation.
Video Classification Datasets
Open-sourced video classification datasets provide researchers with labeled video data that can be used to train and evaluate video classification models. Several open datasets exist for video classification, which helps researchers standardize their models and compare them against the existing state-of-the-art.
Some of the most widely used datasets for video classification are:
UCF101: One of the most widely used video classification datasets is the UCF101 dataset, which consists of 13320 videos from 101 different action classes, such as walking, jogging, and playing soccer. The dataset is commonly used for evaluating the performance of video classification algorithms in a wide range of action recognition tasks. The UCF101 also has several daughter datasets that are subsets of the same containing fewer or some specific action classes—such as the UCF50, UCF11 (YouTube Action), UCF Aerial Action, etc.
HMDB51: This dataset contains 6849 videos from 51 different action classes. This dataset is similar to UCF101, but it has a smaller number of classes and videos. Therefore, it’s more suitable for less complex models (such as fine-tuning student models in Knowledge Distillation pipelines).
Kinetics: Kinetics is another popular video classification dataset consisting of over 400,000 videos from 600 human action classes. The videos in Kinetics dataset are taken from YouTube and other sources and labeled by human annotators.
YouTube-8M: YouTube-8M is another large-scale dataset that includes 8 million YouTube video URLs and associated labels from a vocabulary of 4716 classes. Unlike the previous ones, this dataset is not specific to action recognition but encompasses a wide range of video classification tasks.
Sports-1M: This sports action recognition dataset contains 1 million videos from 487 classes of sports, such as basketball, soccer, and ice hockey.
In addition to the datasets that are publicly available, researchers also create their own datasets for specific research projects. This can be especially useful when the available datasets do not have the necessary classes or enough samples for a particular research problem.
It is important to note that the quality and size of the dataset can greatly affect the performance of the video classification algorithms. Datasets that are larger and have more diverse classes tend to result in better performance, as they provide the model with more diverse examples and improve the generalization capabilities of the model.
Pro tip: Check out V7’s collection of 500+ open datasets
Video classification methods
Over the years, several different types of deep learning-based algorithms have been developed for video classification. Most of them use supervised learning, a framework that uses videos and their labels to train a neural network (Convolutional Neural Networks or Recurrent Neural Networks). However, recent methods focus on reducing the reliance on labeled data since they are difficult and expensive to collect.
Although low supervision methods sound perfect on paper, most of the time, they come at the price of accuracy. So, the question of whether to use supervised or low supervision methods depends on the use case. Sensitive applications, such as surveillance and healthcare, value accuracy over computational burden. On the other hand, sports or general-purpose action recognition (such as entertainment) can work with comparatively lower accuracy models. They still need efficient storage solutions, since such domains often have large amounts of unlabelled data readily available.
Let us look into both supervised and low supervision methods for video classification next.
Supervised
Supervised learning is a type of machine learning in which a model is trained to make predictions based on labeled data. A set of labeled data is split into train, validation, and test sets for evaluating a model. Then, the trained model is used on unlabeled data to check the model’s performance qualitatively. In the context of video classification, supervised learning can be used to train a model to recognize specific objects, actions, or scenes in a video.
Early attempts at supervised learning-based video classification include this paper that extensively studied CNN models for the task at a time when CNNs gained popularity for image recognition.
However, CNNs require extensively long periods of training time to effectively optimize the millions of model parameters. This difficulty rises when extending the connectivity of the architecture temporally—the network must process not just one image but several frames of video at a time.
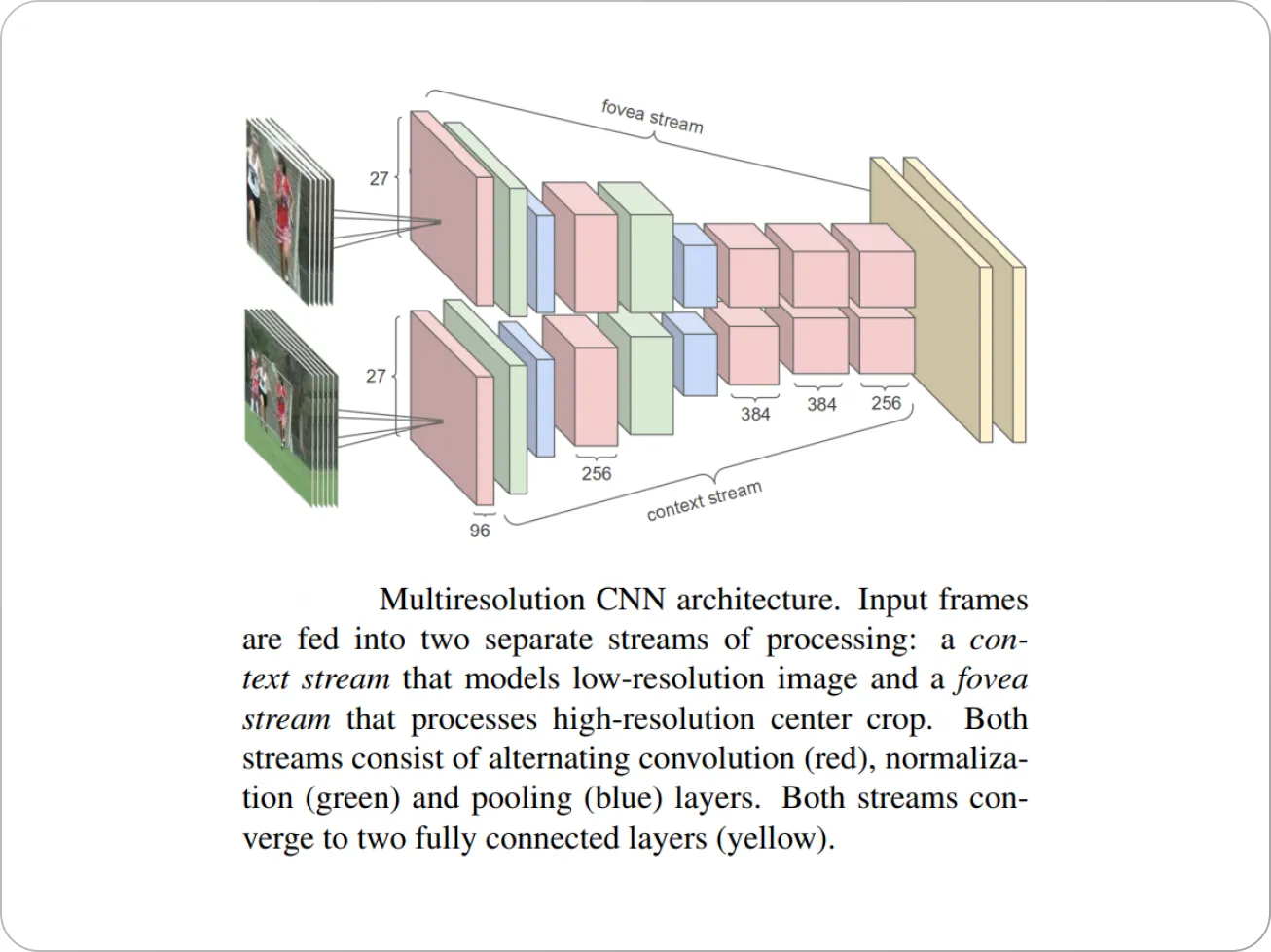
The authors of the paper modified the CNN architectures to contain two separate streams of processing: a “context” stream that learns features on low-resolution frames, and a high-resolution “fovea” stream that only operates on the middle portion of the frame, which yielded a 2-4x boost in runtime performance.
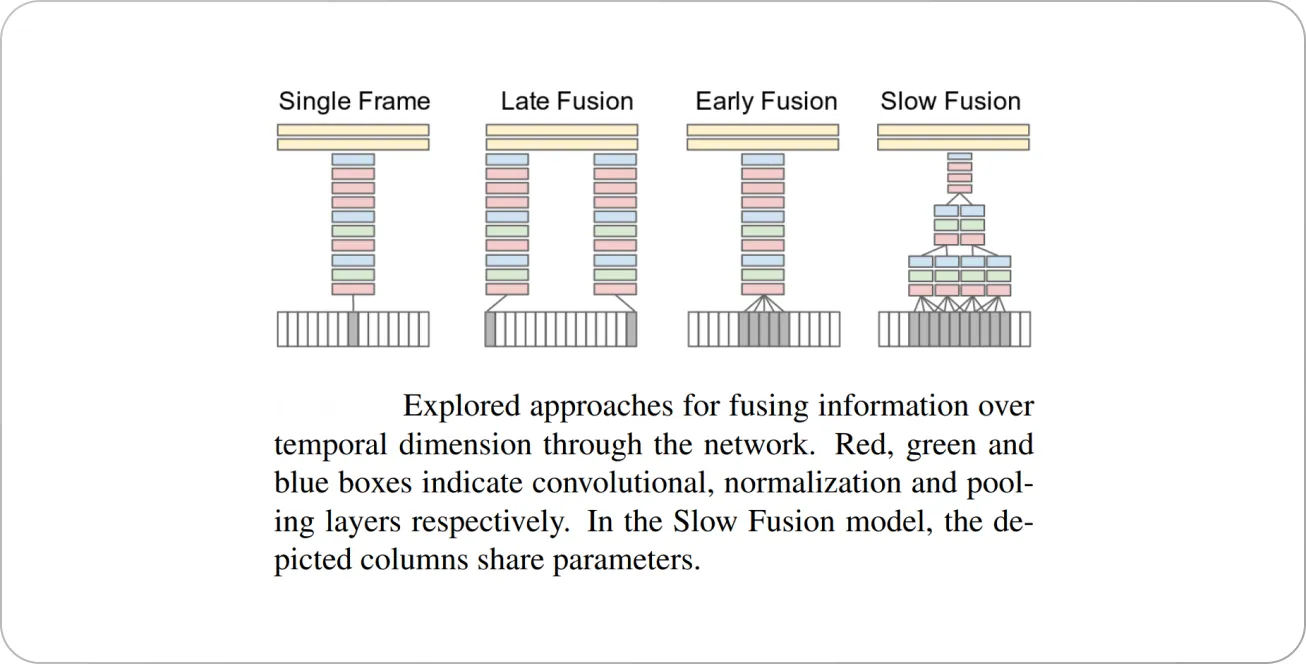
The authors studied several approaches to fusing information across the temporal domain (figure below)—the fusion can be done early in the network by modifying the first layer convolutional filters to extend in time, or it can be done late by placing two separate single-frame networks some distance in time apart and fusing their outputs later in the processing.
Additionally, the authors studied Multi-Resolution CNNs (figure below) to speed up the CNN training time from 5 clips per second to 20 clips per second while retaining performance.
Here are some qualitative results obtained by the authors with their model:

Semi-supervised
Semi-supervised learning is a machine learning paradigm in which a model is trained on both labeled and unlabelled data. In such cases, usually, the percentage of labeled data in the dataset is small (like 5% or 10%) and is used sparingly, while a large amount of unstructured data is readily available.
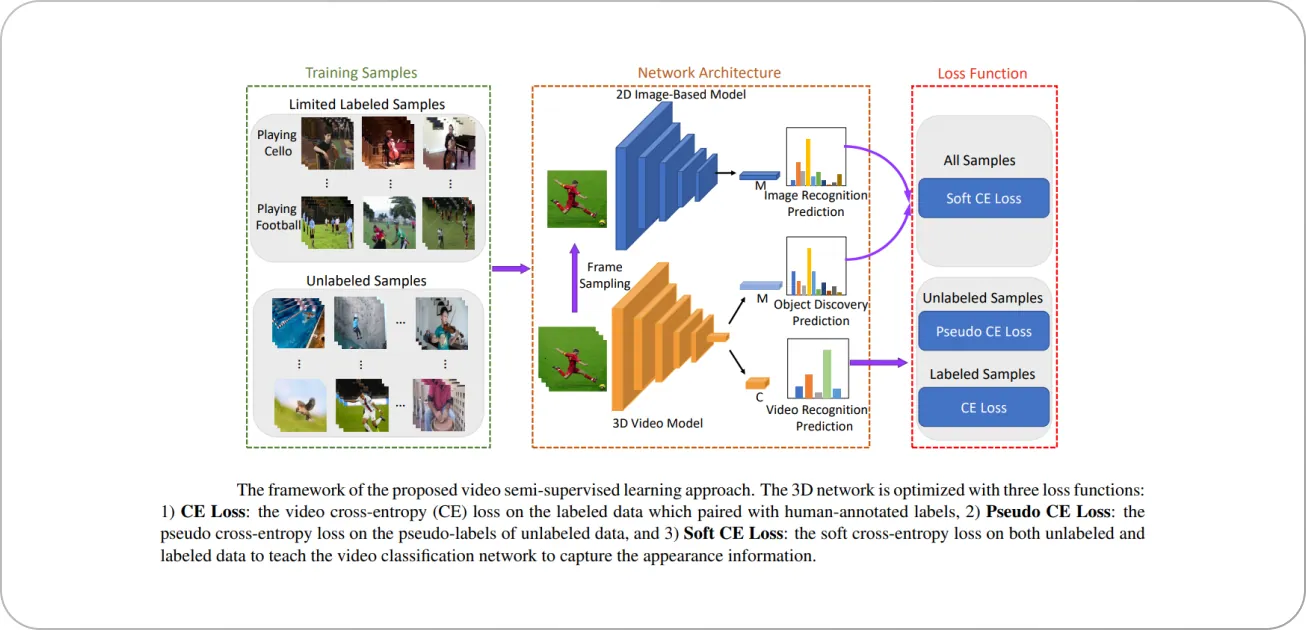
VideoSSL is a framework that attempts video classification using semi-supervised learning. Given a small fraction of the annotated training samples, VideoSSL leverages two supervisory signals extracted from the unlabeled data to enhance classifier performance:
Pseudo-labels of the unlabeled 3D video clips
Appearance cues of objects of interest, distilled by the prediction of a 2D image classifier CNN on a random video frame.
The overview of the framework is shown below.
Here are a few examples of qualitative results obtained by VideoSSL:

Results obtained by VideoSSL. Red color indicates wrong predictions.
Weakly-supervised
Weakly-supervised video classification is a type of machine learning task that involves training a model to classify videos based on weak labels, i.e., the exact classification labels are not available, but some other helpful information might be. This is in contrast to fully supervised video classification, where the model is trained with a large amount of labeled data, including the class labels of each frame or segment of the video.
An example of such a framework is the UntrimmedNet model that addresses the action recognition problem from untrimmed raw videos. Here, the weak labels are the video-level annotations (say, bowling, running, etc.), and the goal is to perform temporal annotation, i.e., find timestamps between which the actual action occurs in the video.
UntrimmedNet is composed of two components- a classification module and a selection module. UntrimmedNet starts with generating clip proposals, which may contain action instances, by using uniform or shot-based sampling, which is fed into a deep network for feature extraction. Based on these clip-level representations, the classification module aims to predict the classification scores for each clip proposal. In contrast, the selection module tries to select or rank those clip proposals.
The results of the two modules are fused with an attention-weighted sum of products to produce the temporal annotation. The workflow of the UntrimmedNet model is shown below.

Self-supervised
Self-supervised learning is a unique approach to unsupervised machine learning, where a model, when given training data samples, generates (pseudo) labels. From these pseudo-labels, the ones which have been predicted with high confidence are used as the ground truth for the next iteration of the training algorithm. This way, the entire training dataset is labeled, and the network is sufficiently trained, which is then evaluated on a test set.
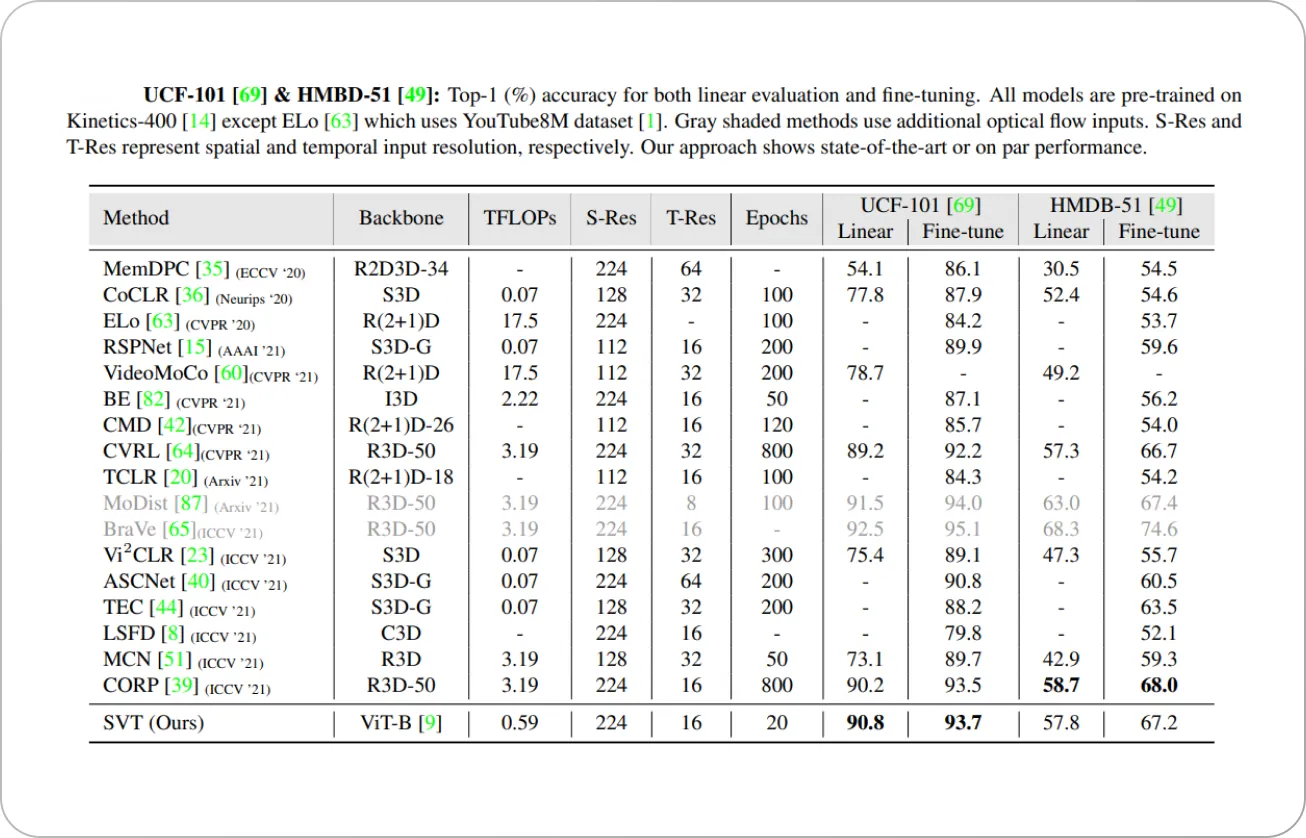
An example of this approach is the Self-Supervised Video Transformer (SVT) framework that uses a Vision Transformer (ViT) in a self-supervised knowledge distillation setting. In short, knowledge distillation involves training a task-specific simpler model (student network) with the aid of the learned semantics by a complex model (teacher network) trained for general-purpose tasks.
SVT trains student and teacher models with a similarity objective that matches the feature representations along the spatial and temporal dimensions by space and time attention mechanisms. The authors achieve this by creating positive spatiotemporal views that differ in spatial sizes and are sampled at different time frames from a single video. The workflow of the SVT framework is shown below.

During training, the teacher video transformer parameters are updated as an exponential moving average of the student video transformer. Both of these networks process different spatiotemporal views of the same video, and SVT’s objective function is designed to predict one view from the other in the feature space. This allows SVT to learn robust features that are invariant to spatiotemporal changes in videos while generating discriminative features across videos.
Unlike contrastive learning methods, SVT does not require negative class mining and can converge efficiently in only 20 iterations while achieving state-of-the-art results (as shown below).
Video classification use cases
Video classification has a wide range of applications in various fields, including entertainment, security, surveillance, healthcare, and education. Let’s take a quick look into some of the most common use cases.
Human Activity Recognition
Video classification for human activity recognition involves analyzing videos of people to identify and classify the actions they are performing. This can include activities such as walking, running, jumping, and even more complex activities like playing sports or dancing.
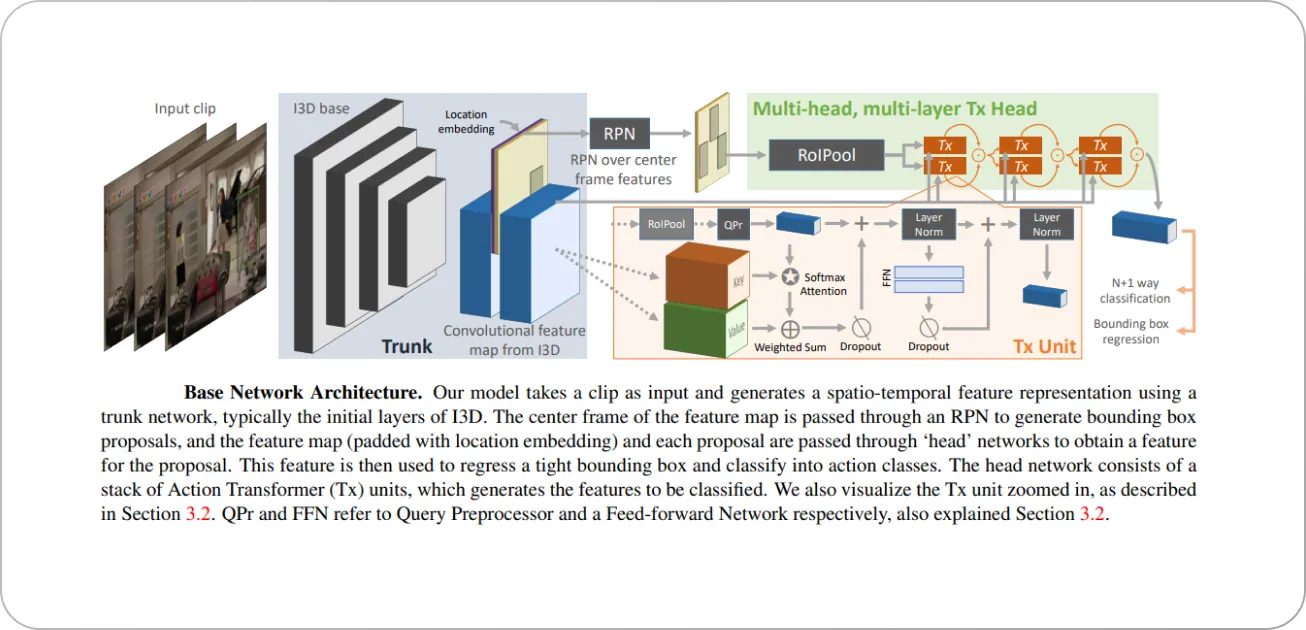
The action transformer model is an example of a framework that addresses the action recognition problem. The authors hypothesized that context information helps boost model performance—for example, detecting that a person is speaking is easier when another person is present in the video.
The action transformer framework consists of distinct “base” and “head” networks. The base network is a 3D CNN for generating features and region proposals for the people present in the video. The head network is a modified transformer architecture to classify the actions of the people of interest using the feature maps from the base network. The schematic overview of the model is shown below.
Here are some results obtained by the action transformer model.

Healthcare
Video classification can be used in the healthcare sector to automatically analyze medical videos, such as endoscopy or surgery footage, to detect and classify abnormalities or to aid in diagnosis and treatment planning.
For example, this paper uses 3D CNN architectures for automated interpretation of ultrasound videos of the heart. The authors find that two-stream CNN networks work the best for the problem, where one stream encodes the spatial information of every frame of the video, and the second stream encodes the temporal information.
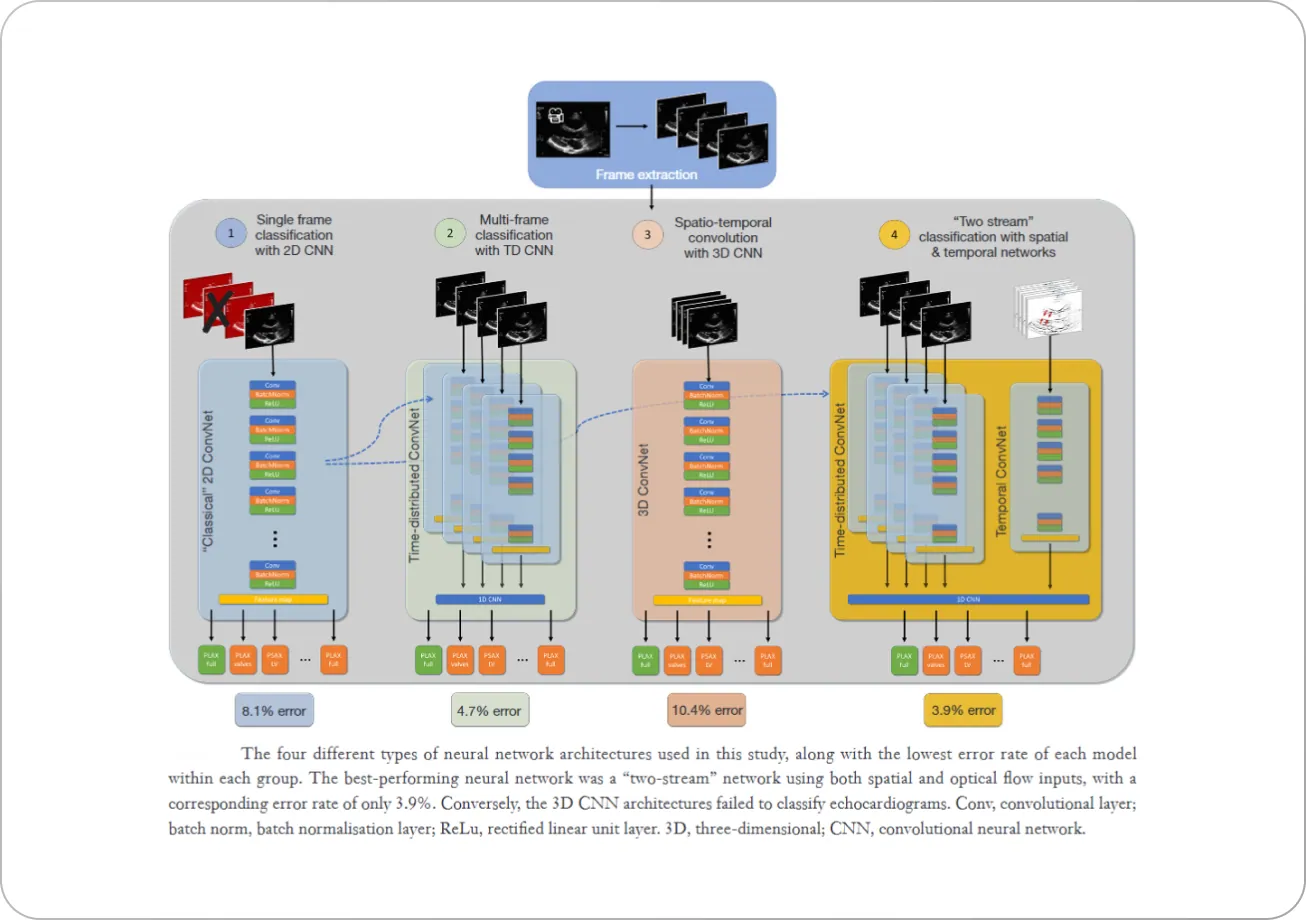
An example of the two-stream model’s performance obtained by the authors is shown below, where the saliency maps derived from the network streams highlight the features of the video that contribute most towards the CNN model’s performance. The spatial stream is influenced by the anatomical borders of the significant structures, while the movement in the pulmonary valves influences the temporal stream.

Autonomous vehicles
A deep learning model trained for video classification can be used to detect and track other vehicles on the road, allowing the autonomous vehicle to make decisions about when to change lanes or merge onto a highway. Similarly, the model can be used to identify pedestrians and other objects in the vehicle's path, allowing the vehicle to take appropriate actions to avoid collisions.
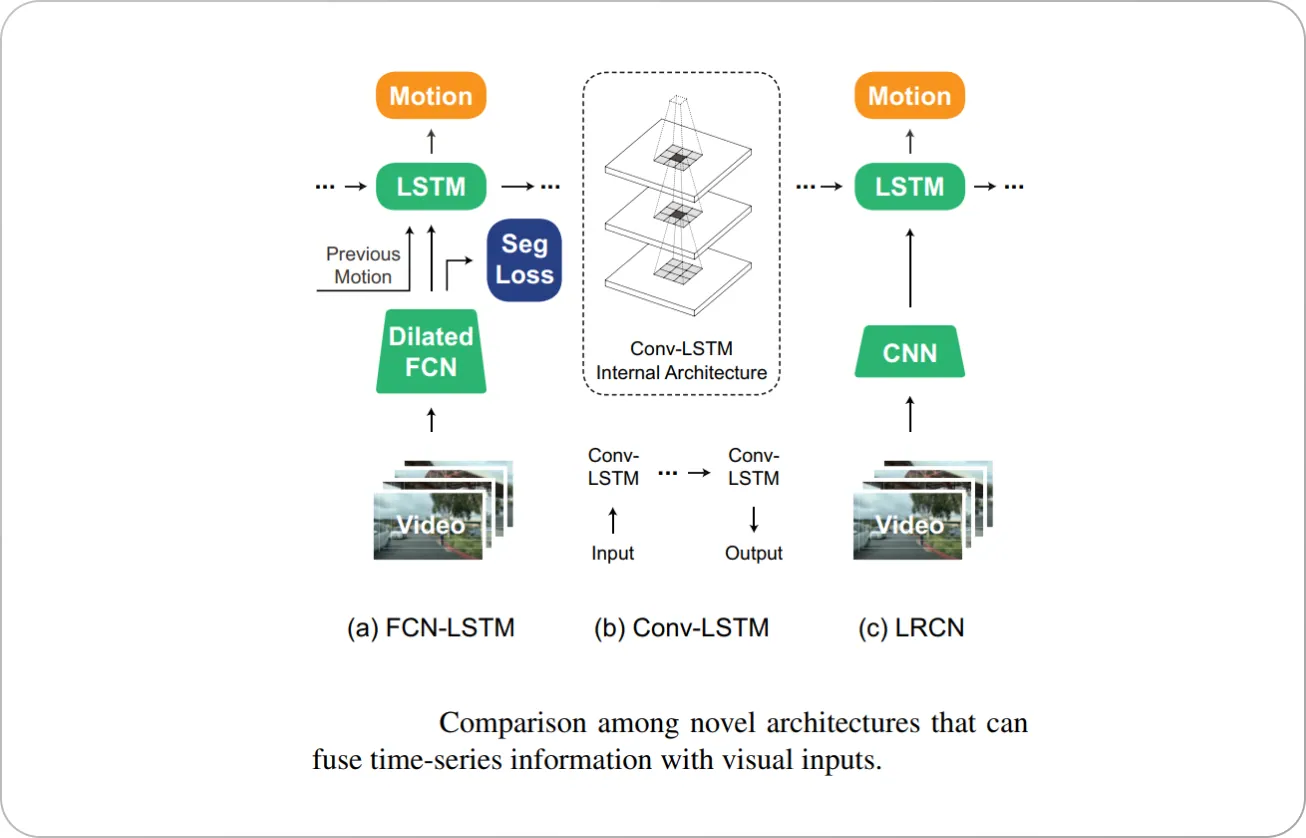
The FCN-LSTM model is an example of a system that uses a combination of a Fully Convolutional Network (FCN) for visual feature encoding and a Long Short Term Memory (LSTM) network for temporal feature encoding.
The FCN-LSTM model is able to jointly train motion prediction and pixel-level supervised tasks. Semantic segmentation is used as a side task following a "privileged" information learning paradigm for an additional performance boost in motion planning. A schematic overview of the model is shown below.
Here are some examples of the predictions made by the FCN-LSTM network.

Embodied AI (robotics)
Video classification can be used to classify objects, scenes, and actions in real-time in the robot's environment and give instructions accordingly for navigation.
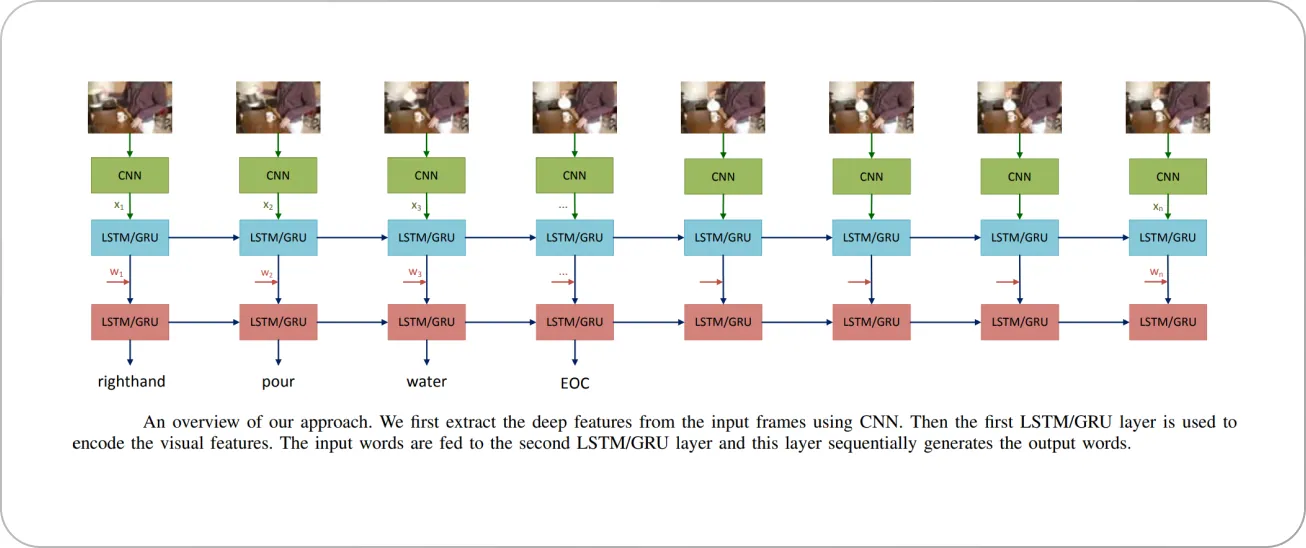
For example, this paper uses a Recurrent Neural Network (RNN) architecture and a CNN for feature extraction from video frames for classifying videos and generating natural text commands for robotic manipulation.
The framework splits the video into frames and extracts CNN features from each of them. Next, two RNN layers are used to learn the relationship between the visual features and the output command. However, unlike typical video captioning problems, which describe the output sentence in a natural language form, the authors used a grammar-free form to describe the output command. The schematic workflow of the model is shown below.
Here are some examples of output commands obtained by the model given an input video sequence.
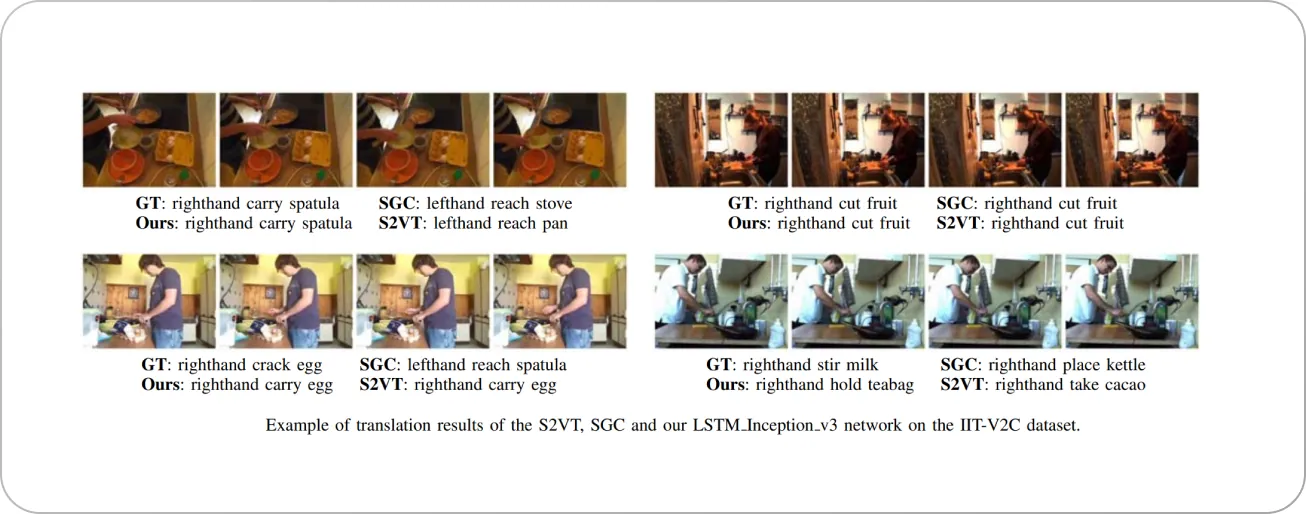
GT= Ground Truth. Source
Next, the authors built a robotic framework that allows their robot, “WALK-MAN,” to perform various manipulation tasks by just “watching” the input video since the previous RNN architecture is embedded within the robot system.
The translation module generates an output command sentence for each task presented by an input video. Based on this command, the robot uses its vision system to find relevant objects and plan actions. Two examples of this are shown below.

Video recommendation
Video classification is used to classify the contents of the video and target the appropriate audience based on their interests, demographics, and browsing history—an application that we all recognize from YouTube.
An example of such a video recommendation system is the framework proposed in this paper by Google Research. The authors introduced a content-based video recommendation system that utilizes raw (untrimmed) video and audio data (multimodal learning). They model the problem as a video similarity learning problem and learn a compact representation of a video preserving its semantics from its visual and audio signals using deep neural networks.
The authors encode all videos into an embedding space, where similar (recommendable) videos are located close to each other, and show that the learned embeddings generalize beyond simple visual and audial similarity and are able to capture complex semantic relationships.
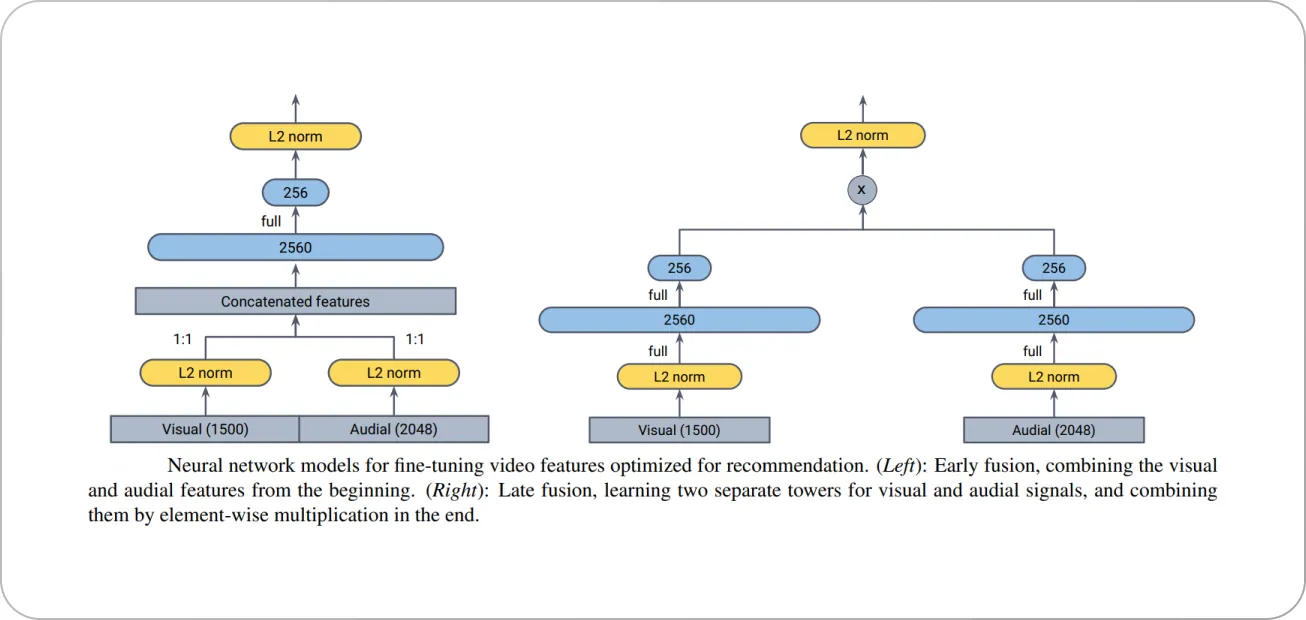
The authors used two types of architectures, early fusion and late fusion, for the recommendation system to extensively evaluate the best performance, and obtained their best performance using the late fusion technique.
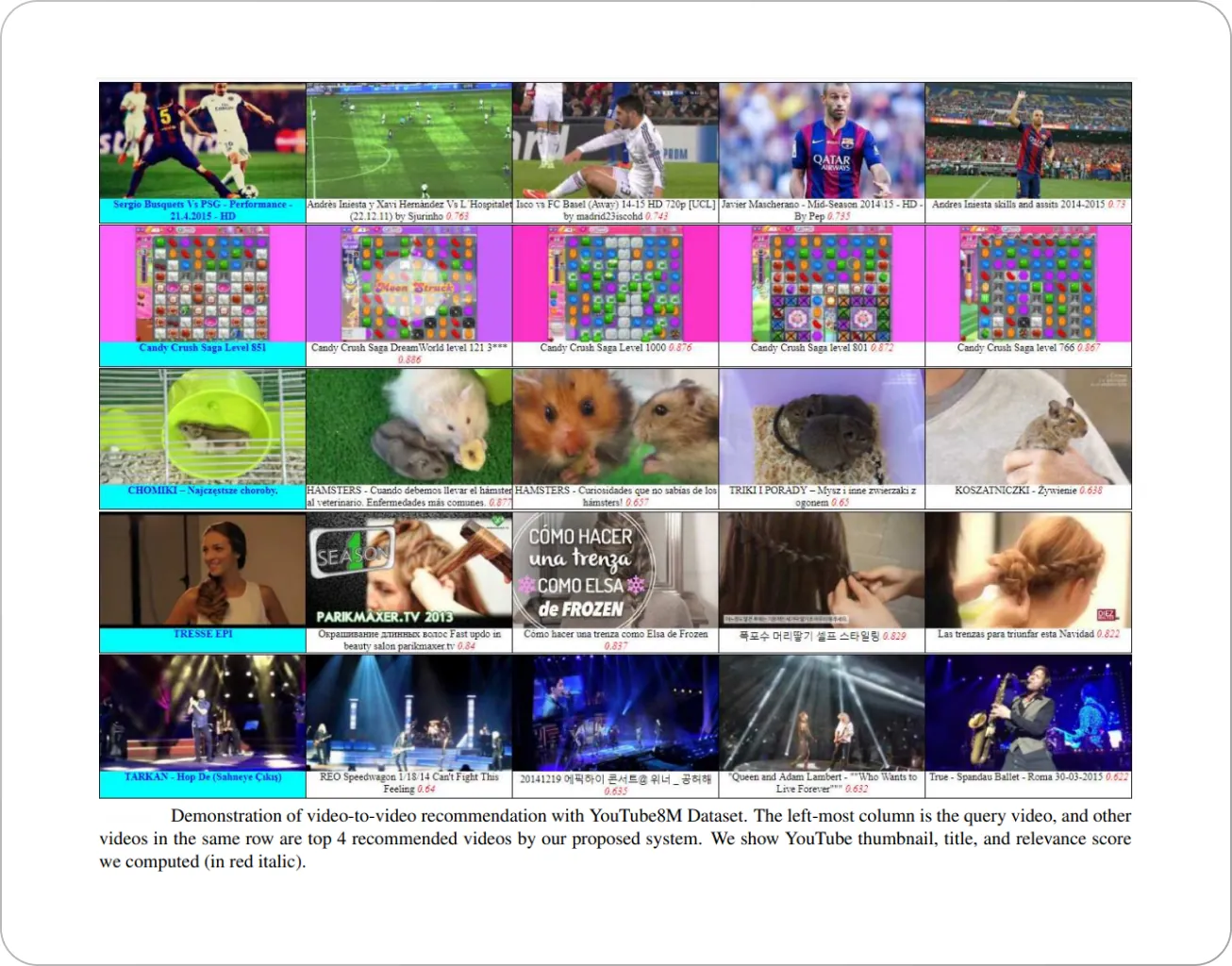
Here are a few exemplary results:
Other applications
Video classification has other far-reaching applications. They are used on an everyday basis for entertainment—for movies or music recommendation in streaming services, automated video editing, or in sports for player performance analysis.
Video classification can also be used to analyze educational videos, such as lectures or tutorials, to detect key concepts, or generate content summaries, or to automatically detect and classify suspicious or abnormal activities in surveillance footage, such as fighting, loitering, or theft. It can help security personnel quickly identify potential threats and respond accordingly.






How to Build a Video Classifier with V7
V7 allows you to train custom video classifiers and other computer vision models with ease. You can streamline your processes by managing your data annotation and machine learning pipeline in one place. The platform comes with a web-based interface and you can test and train your models in the cloud.
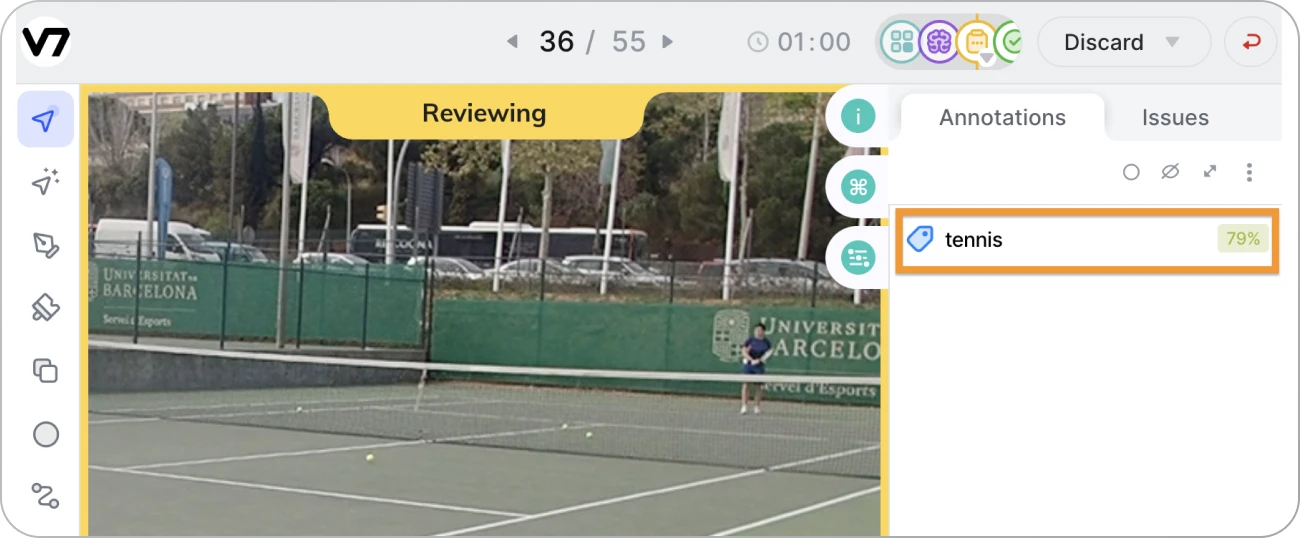
Let’s create a classifier that can recognize tennis, soccer, football, and basketball footage.
To build your video classification model alongside the tutorial, sign up for a free V7 account for students and researchers. Verify your academia and get started today.
Step 1: Collect and Upload Video Clips to the V7 Platform
The first step is to upload your video clips to the V7 platform.
Go to the Datasets tab and add a new dataset with a button. After naming your new dataset, drag and drop the files.

While uploading your videos, you can determine the FPS (frames per second) rate.
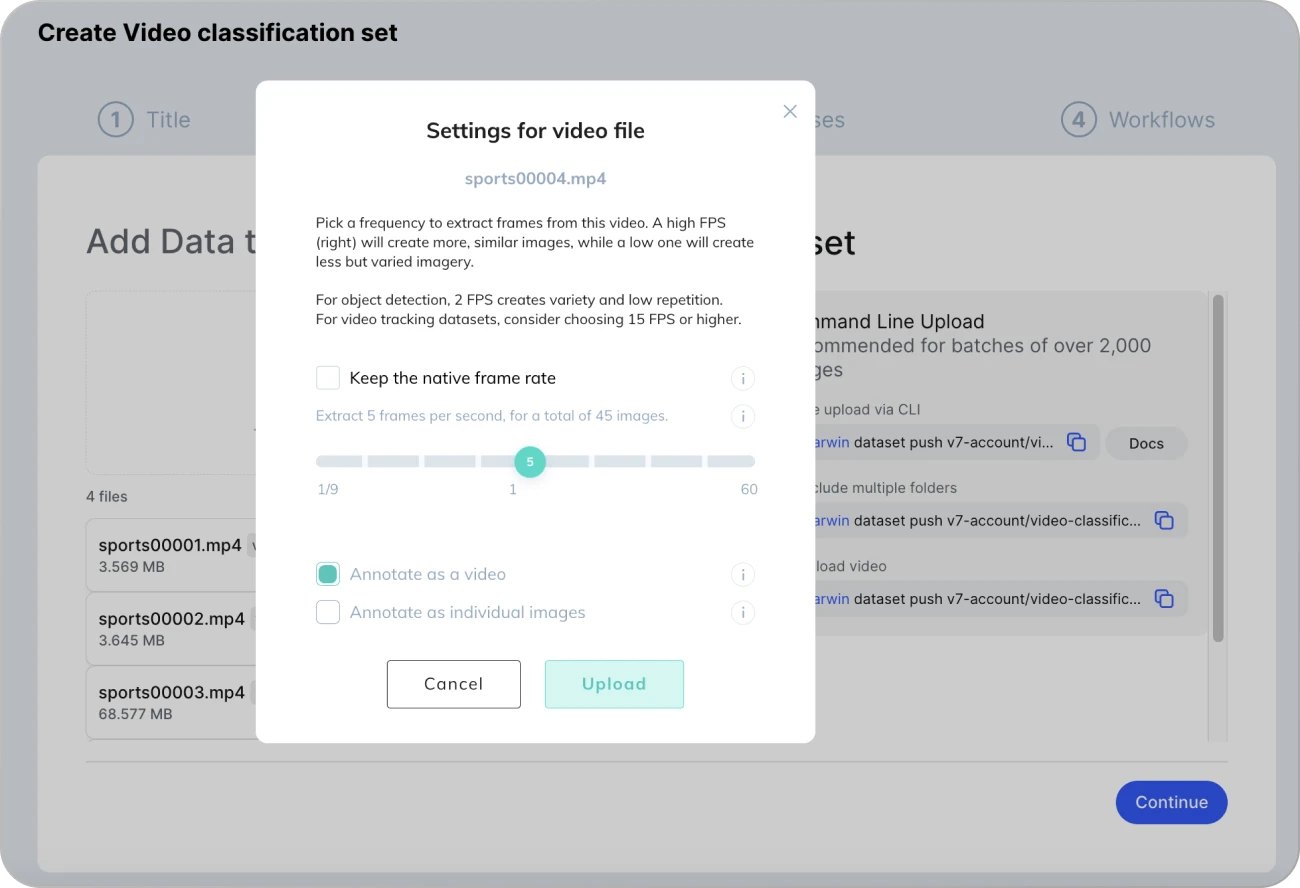
One of the unique features of V7 is that it allows you to use the original frame rate of your videos for data annotation. However, to keep the data manageable consider extracting only several frames per second instead. It is also a great method to improve the variability of your dataset without increasing its size. It is better to use 10 different clips with 3 FPS than to extract 30 FPS from only one video.
Click Continue to proceed.
Step 2: Define a Set of Unique Classes You Want to Recognize
In the next step, we can add our own classes. Make sure to select Tag as your class type.
It is important to use class names that will be easy to remember and understand. In our example, the classes are soccer, football, tennis, and basketball.
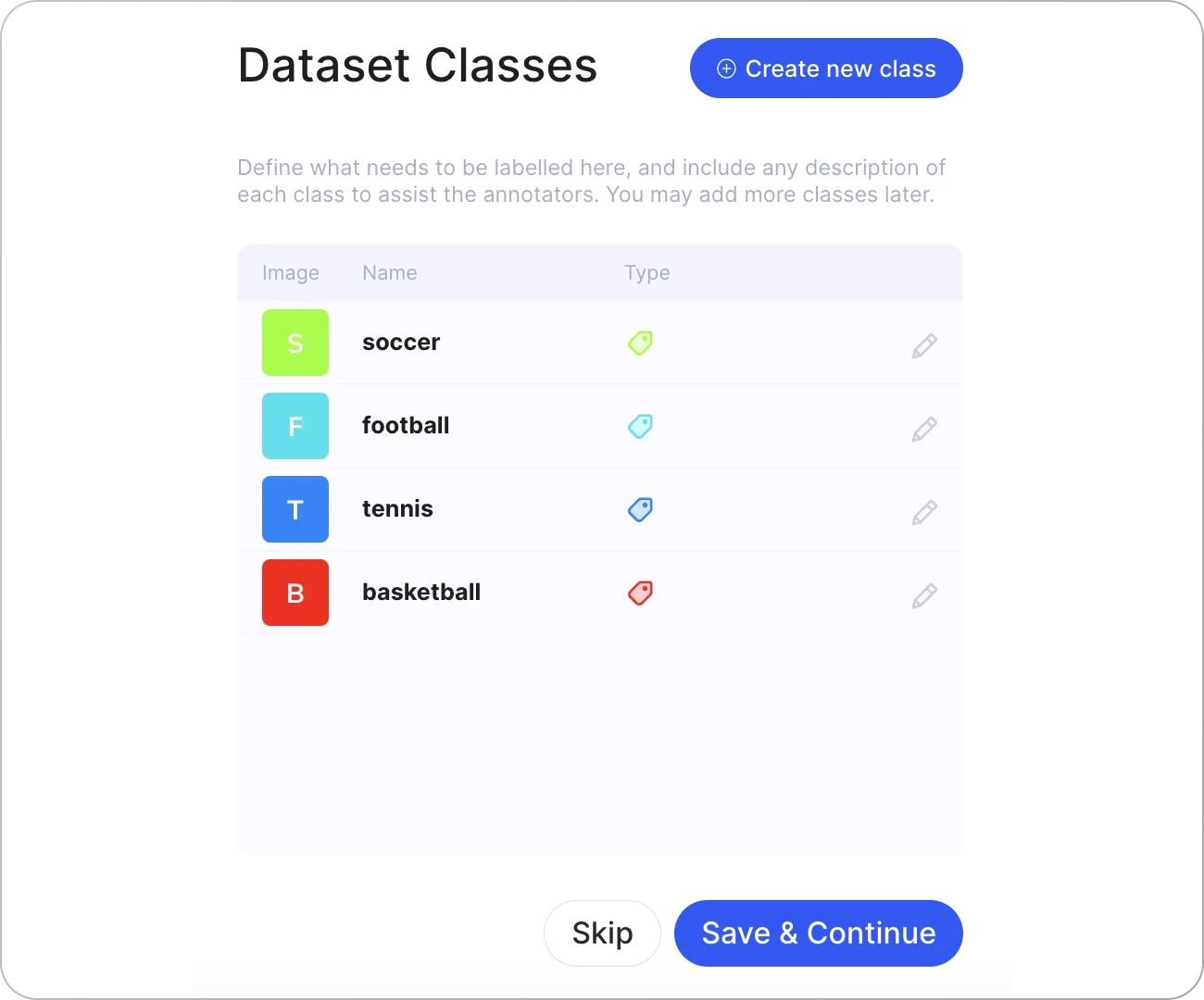
Tags are image-level annotations, which means that our model will use whole frames as its training data. This is a standard practice for training basic classification models. If we wanted a more advanced model (for object detection or activity recognition), segmentation masks or bounding boxes would be a better choice.
Continue with the default workflow settings to complete the dataset setup.
Step 3: Assign the Right Tags to Your Video Clips
Now, you can browse your videos and apply tags created in the previous step. Pick a video and the right tag for it.
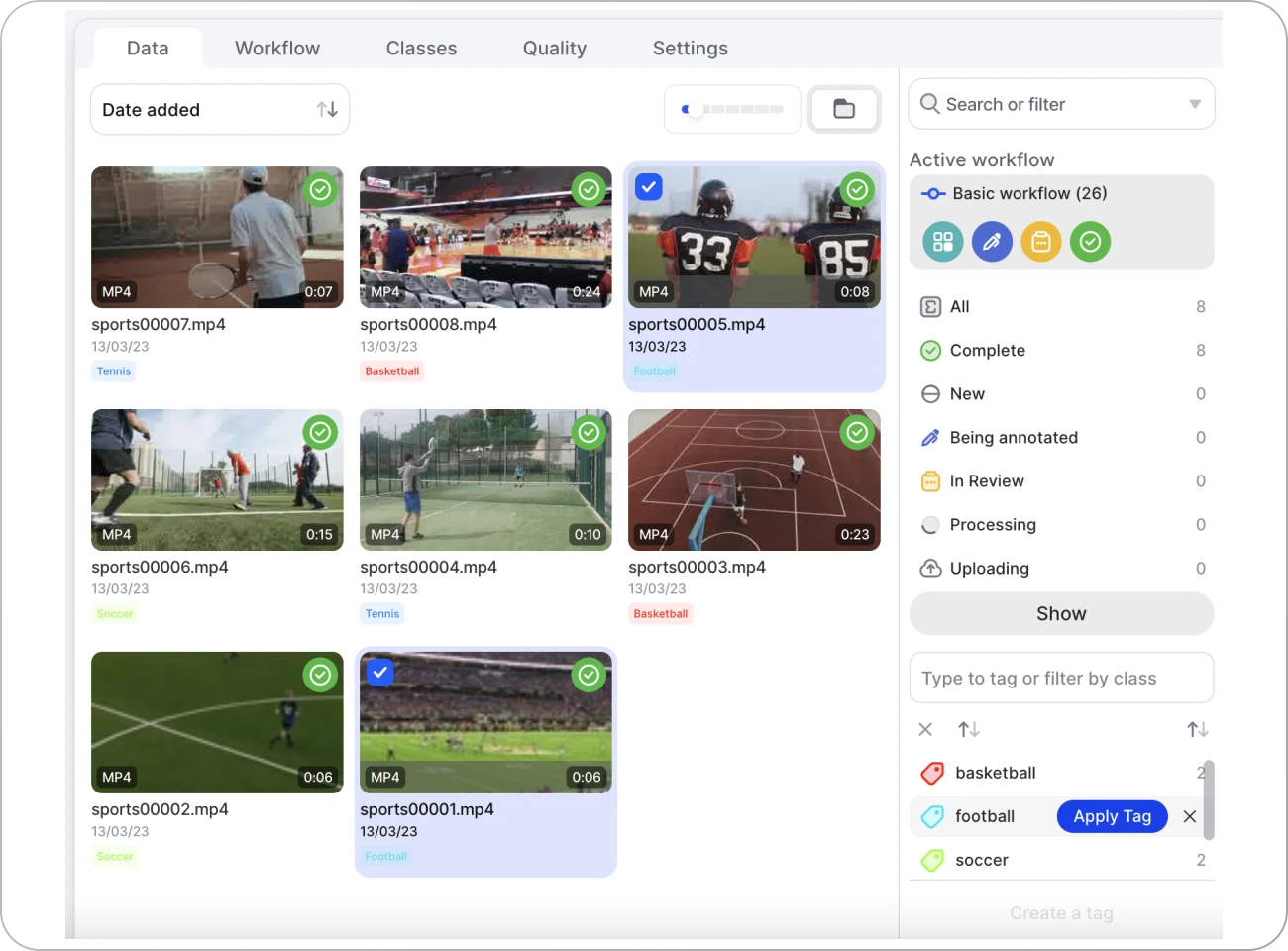
It is important to note that assigning tags this way will apply them to the whole clip. But, if you want to, you can also use the tag only for a specific portion of the video. To do this open your clip and use the timeline to adjust the span of your tag label.
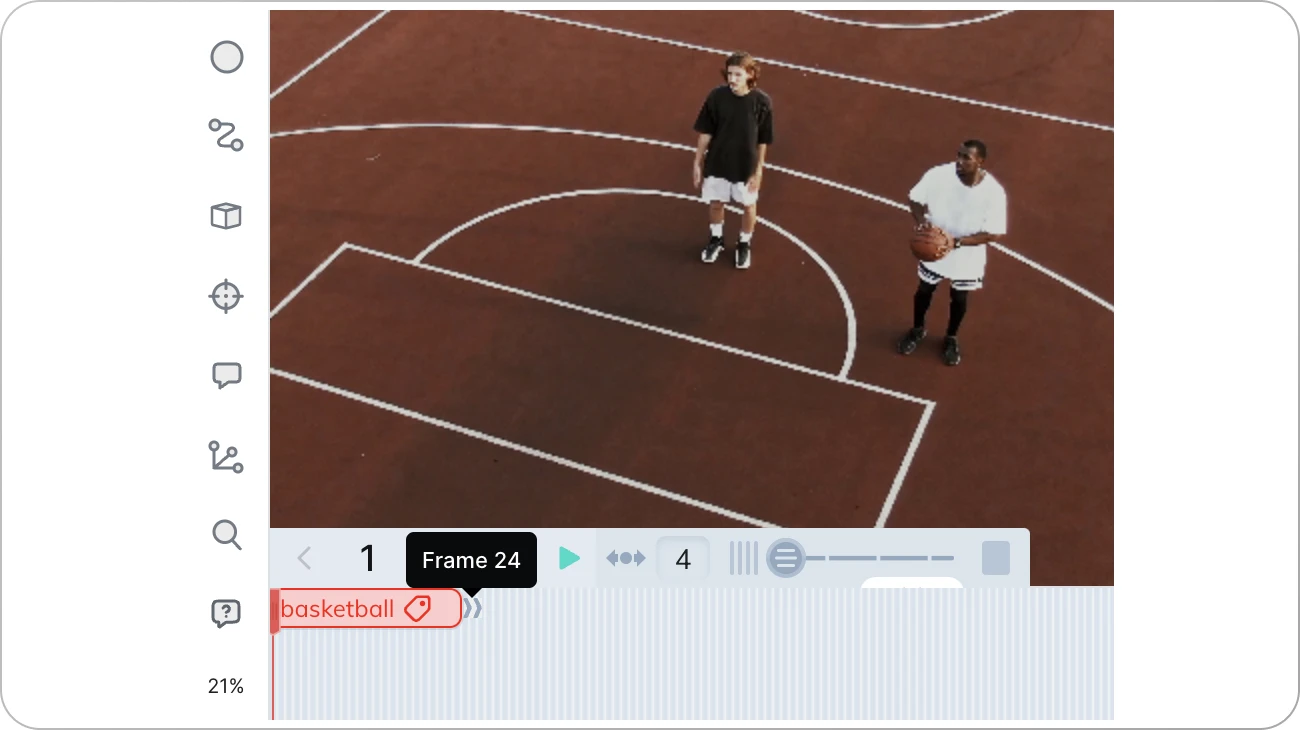
Choosing what frames should be tagged is particularly useful if you work with longer footage. For example, if you are using a recording of a whole soccer match, you probably don’t want to use a commercial break as your training data.
After you are done, select all your files and change their status (Stage) to Complete.
Step 4: Train the Video Classification Model Using V7
Once all your videos are tagged, you can go to the Models panel.

Click the Train a Model button, choose Classification as your model type, and select tags that you want to use for training.
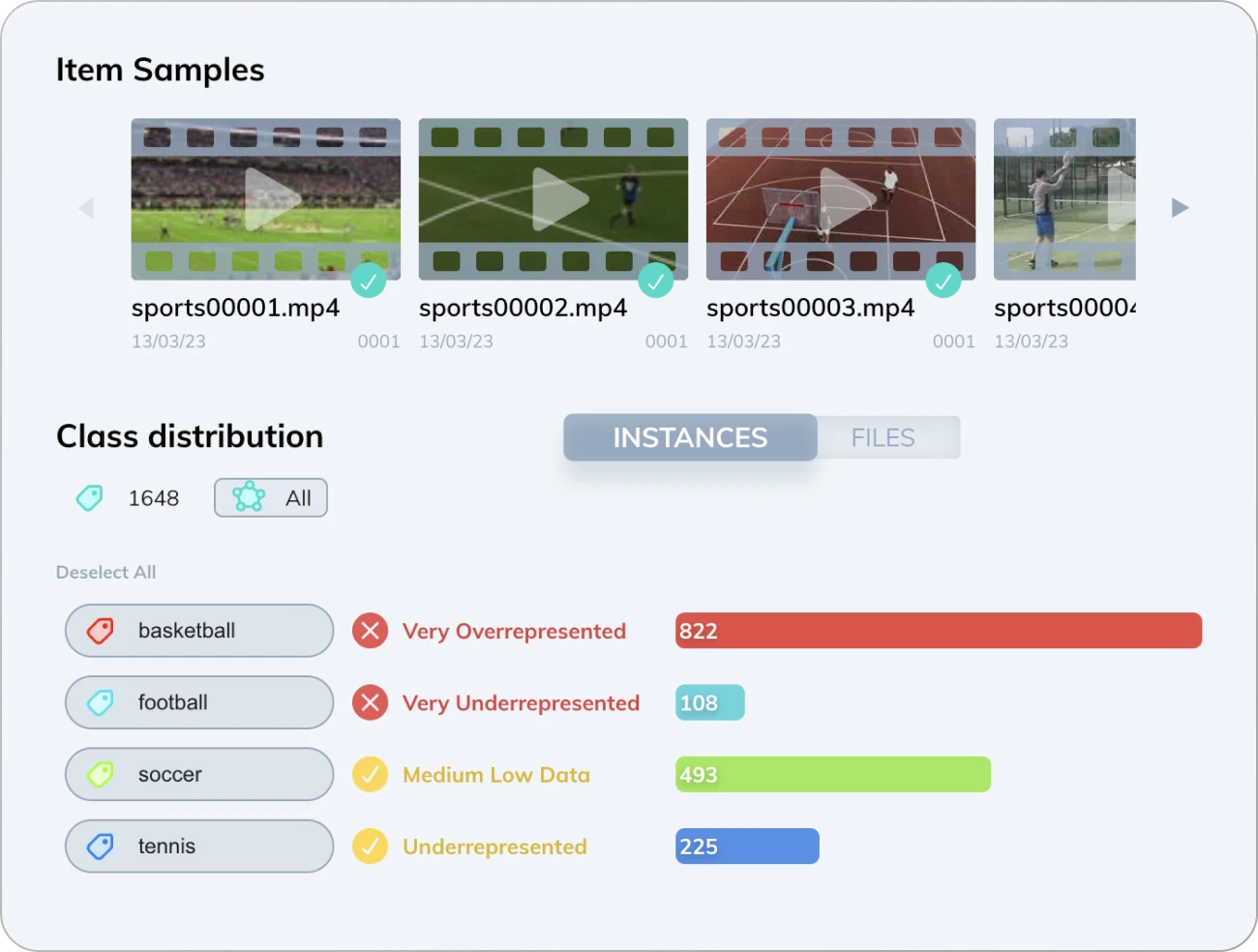
Configure your model and schedule it for training. It should take several minutes to an hour, depending on your dataset's complexity.
Step 5: Upload a new clip and test your model
Open the Models tab again and make sure that your new model is running.

The last step is to test if the model works correctly.
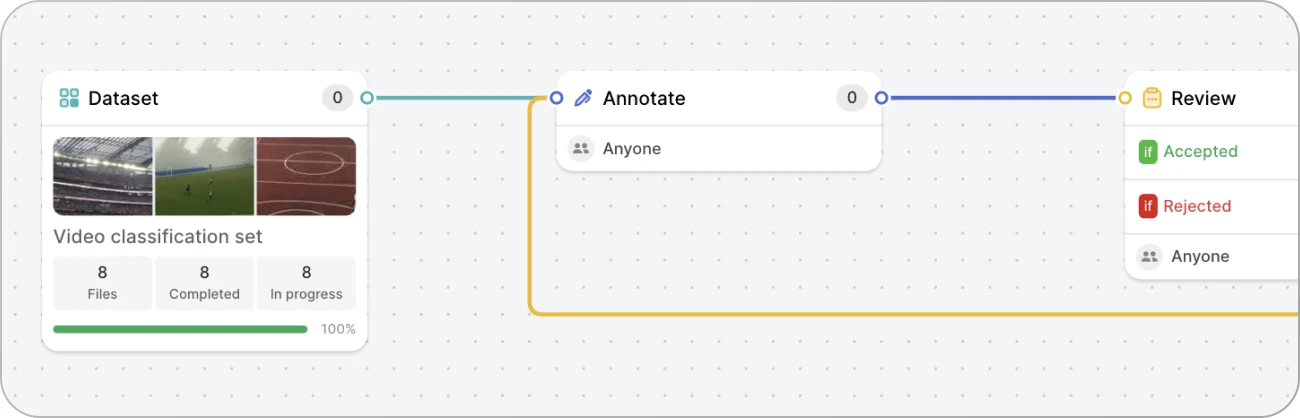
To do that, go to Workflows and replace the Annotate stage with a new Model stage. Then, connect your model.
You should go from something like this:
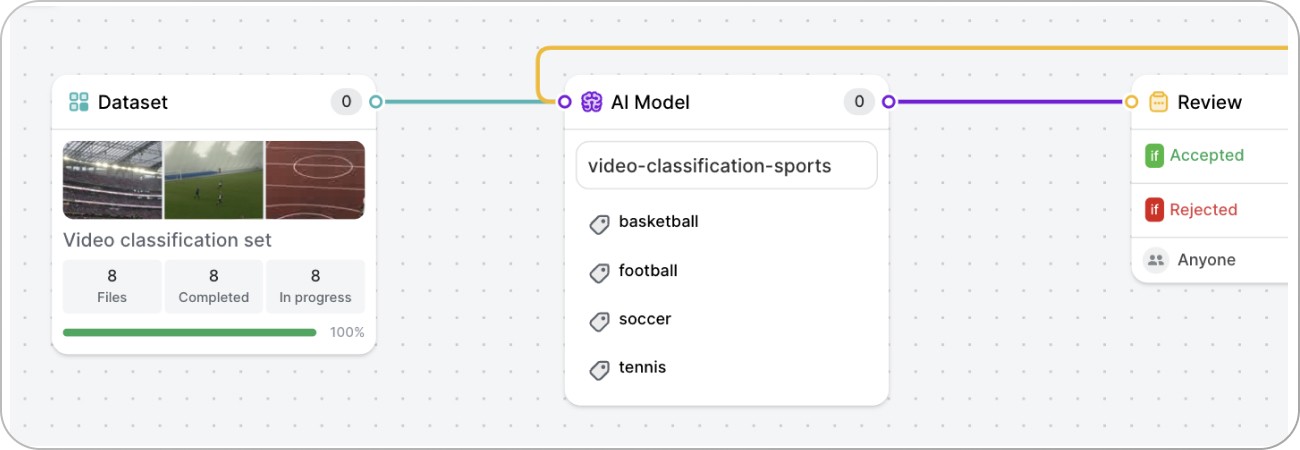
To a workflow design that looks like this:
Now, you can add new items to your dataset.
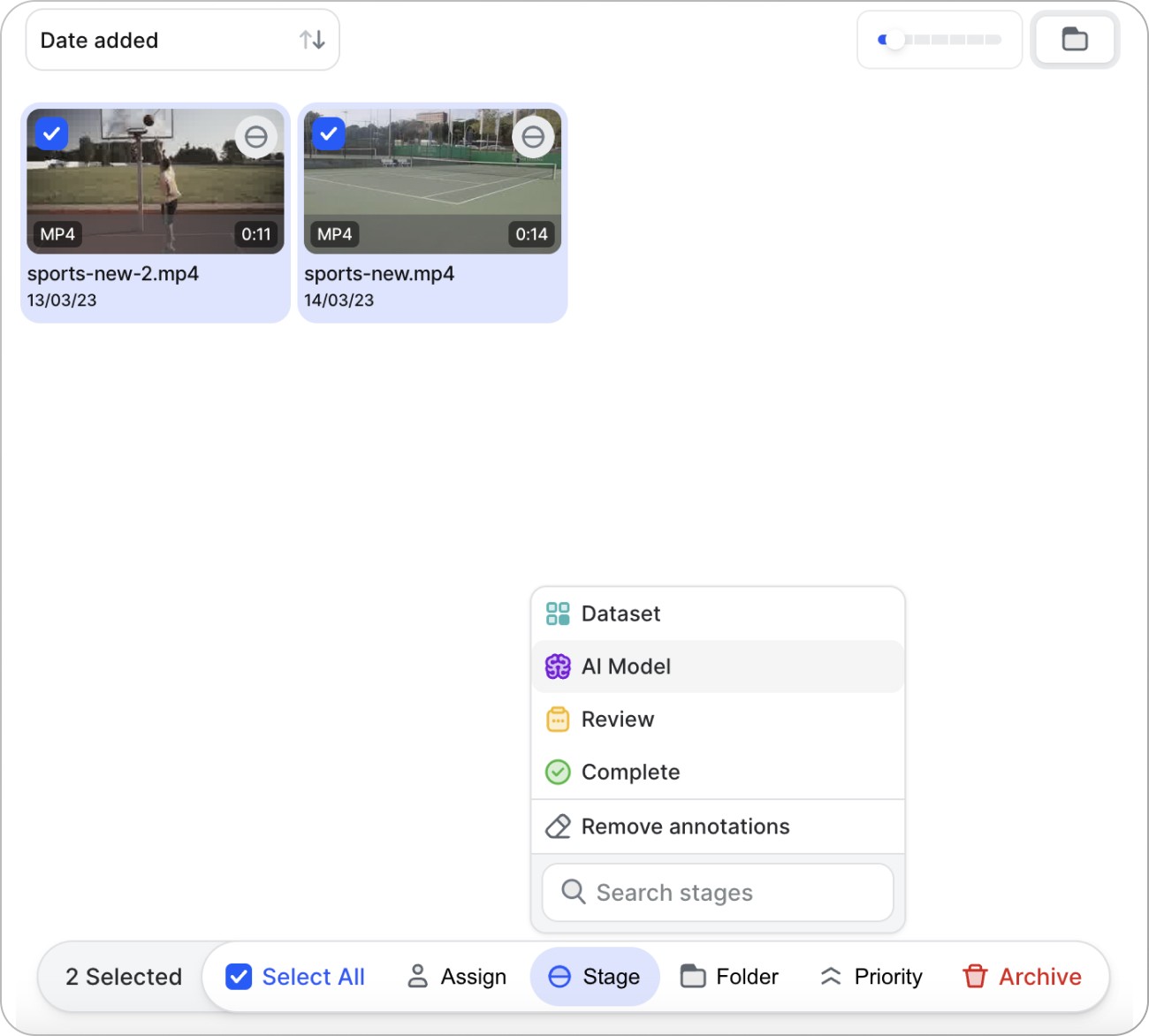
Select the new files and send them to the model stage. The model will classify the videos and assign the correct tags along with confidence scores.
Final Words
Video classification is a rapidly growing field in computer vision, with a wide range of applications in various industries, from healthcare to entertainment. The use of deep learning techniques has greatly improved the performance of video classification models, allowing them to achieve high accuracy and robustness.
However, the field is still facing several challenges, such as the need for large amounts of labeled data and the difficulty of dealing with temporal information in videos, which is where the low supervision methods we discussed come into play. The field is expected to grow continually with new innovations that require less data to train (to save computational burden) and results more accurate than humans themselves can provide.