AI implementation
Intro to MLOps: What Is Machine Learning Operations and How to Implement It
14 min read
—
Jan 30, 2023
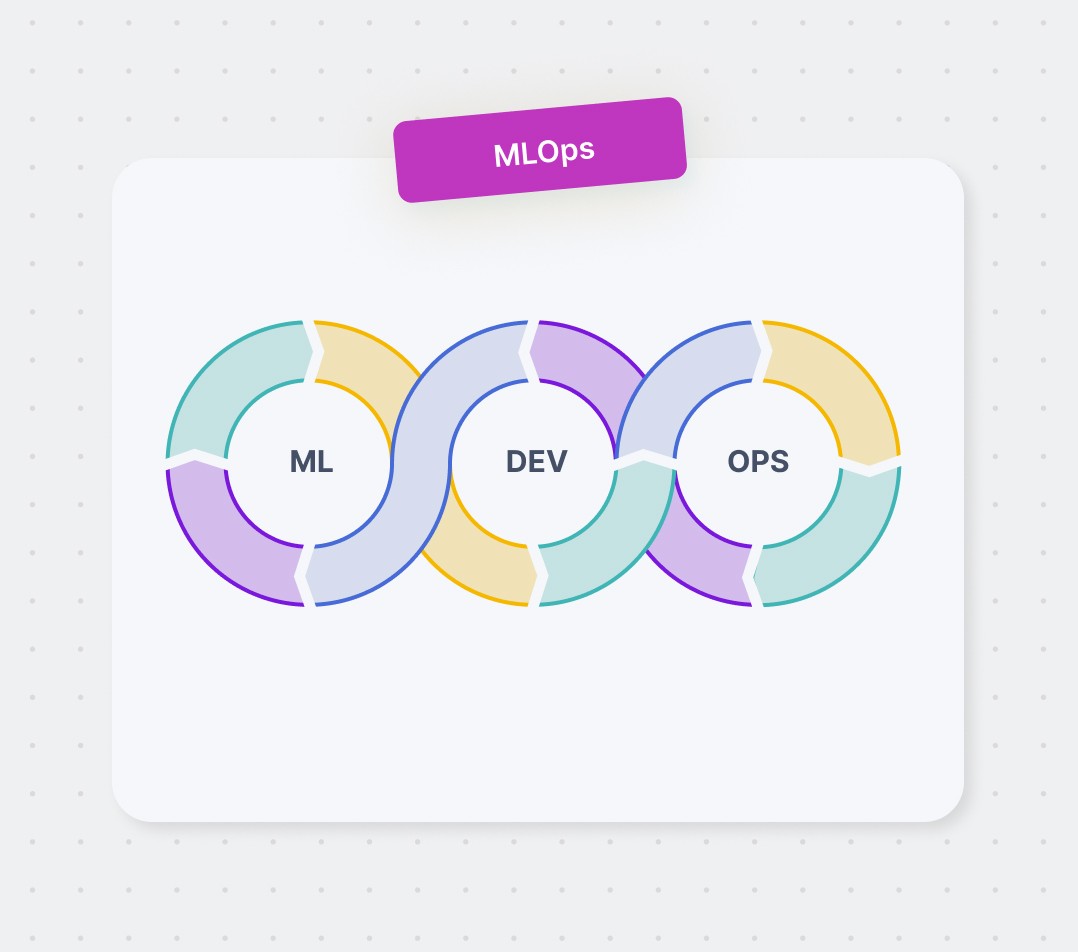
What is machine learning operations? Let's go through the principles of MLOps and its importance for machine learning teams.

Guest Author
MLOps has become a buzzword in the machine learning community. However, it’s often thrown around without a full grasp of its meaning.
Real-world machine learning systems have multiple components, most of which don’t include the code itself. To effectively develop and maintain such complex systems, crucial DevOps principles were adopted. This has led to the creation of Machine Learning Operations or MLOps for short.
This article will provide a thorough explanation of MLOps and its importance for machine learning teams, based on extensive research and analysis of multiple sources.
Here’s what we’ll cover:
What is machine learning operations (MLOPs)?
Why do we need machine learning ops?
What are the MLOps best practices?
How to implement MLOps?
And if you're ready to start automating your machine learning pipeline right away, check out:
What is machine learning operations (MLOPs)?
Machine learning operations (MLOps) is a new paradigm and set of practices that help organize, maintain and build machine learning systems. It aims to move machine learning models from design to production with agility and minimal cost, while also monitoring that models meet the expected goals.
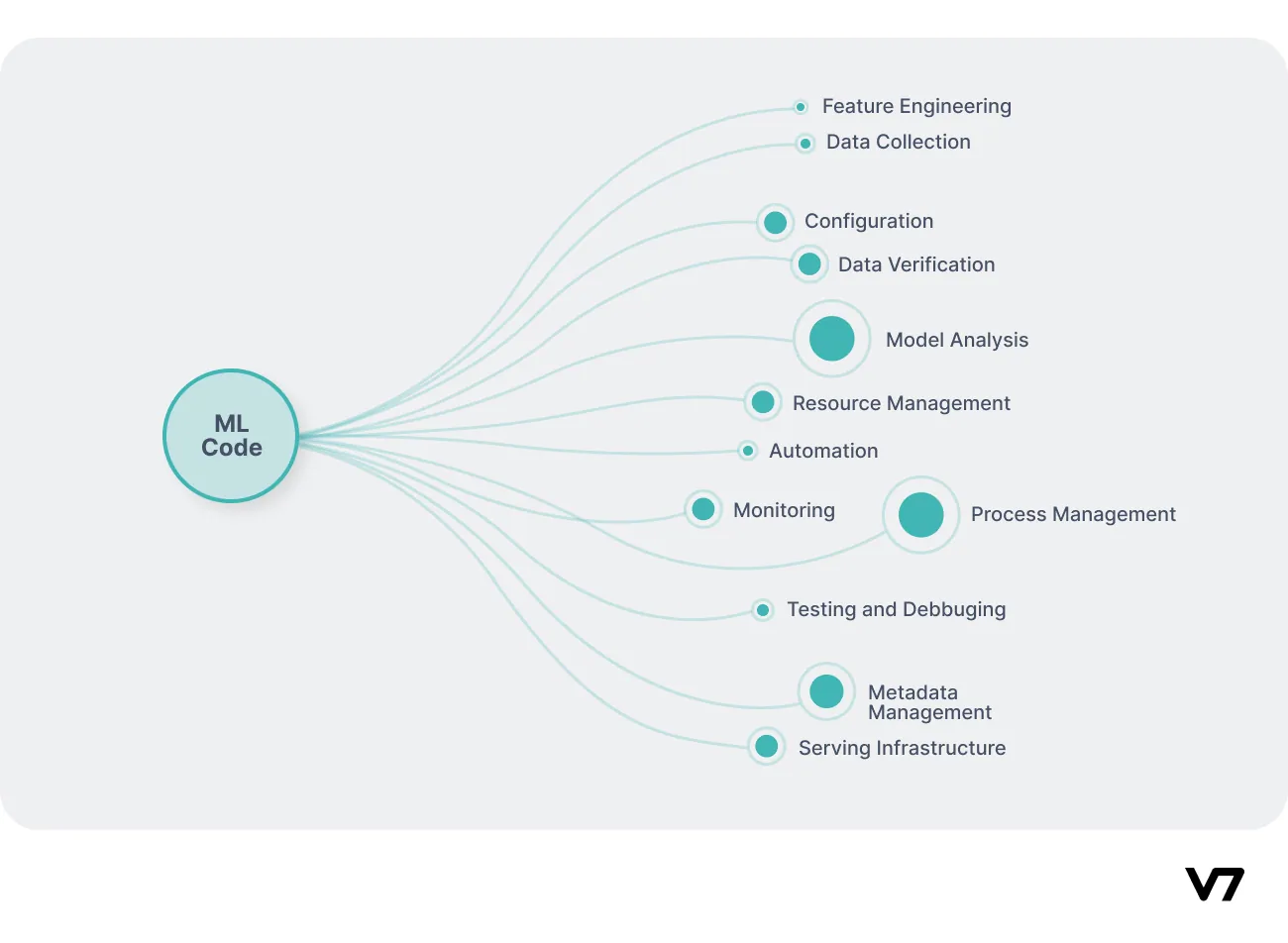
CDFoundtation states that it’s “the extension of the DevOps methodology to include machine learning and sata science assets as first-class citizens within the DevOps ecology.”
Machine learning operations emphasize automation, reproducibility, traceability, and quality assurance of machine learning pipelines and models.
MLOps pipelines cover several stages of the machine learning lifecycles. However, you may choose to implement MLOPs methodologies on only certain parts of the machine learning lifecycle:
Data extraction and storage
Data validation and data cleaning
Data & code versioning (a recurrent step)
Exploratory Data Analysis (EDA)
Data preprocessing and feature engineering
Model training and experiment tracking
Model evaluation
Model serving
Model monitoring
Automated model retraining
Testing
Documentation
DevOps vs MLOps
Since machine learning operations was inspired by DevOps, they share many similarities.
While DevOps focuses on software systems as a whole, MLOps places particular emphasis on machine learning models. It requires specialized treatment and high expertise due to the significance of data and models in the systems.
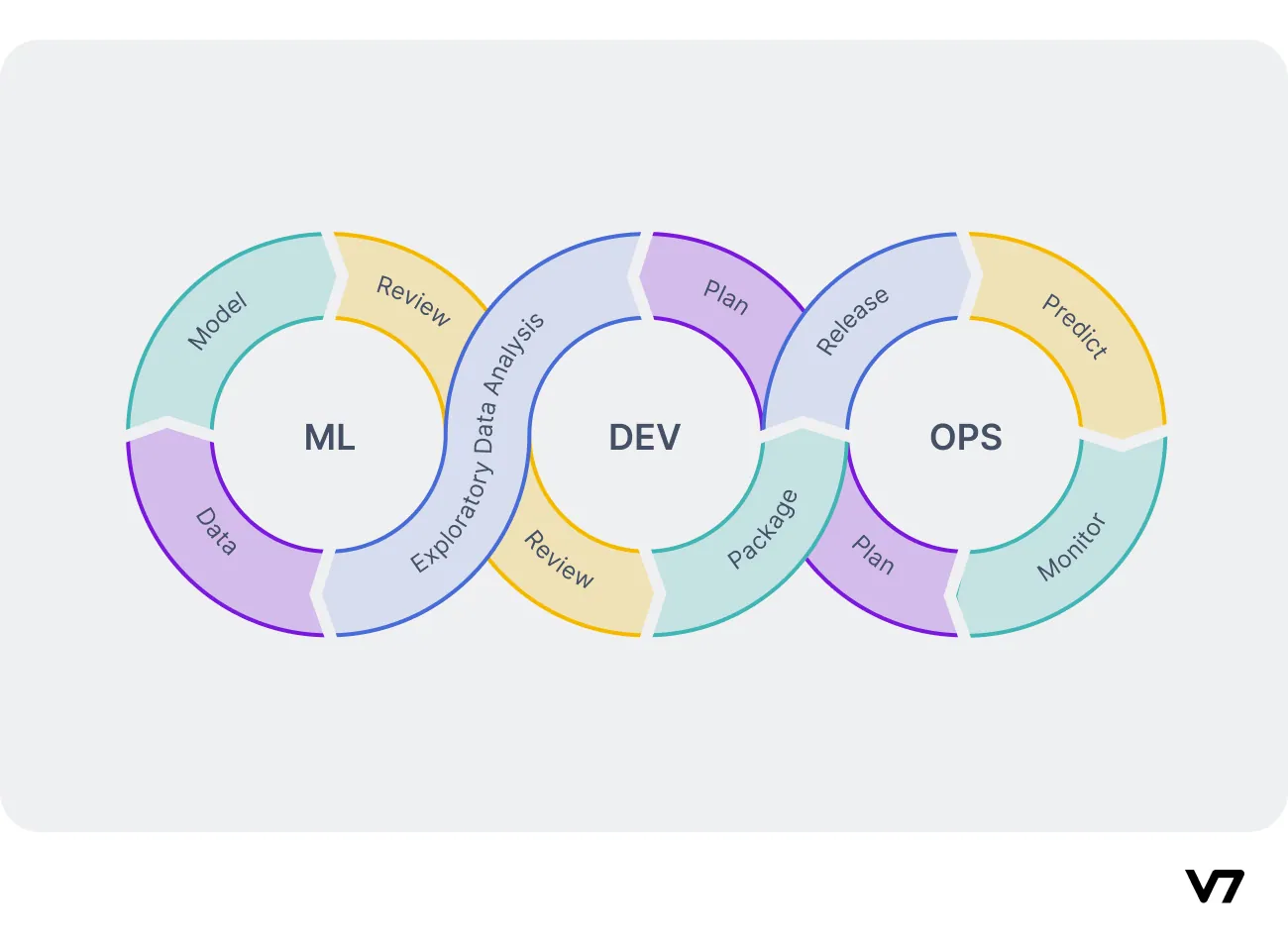
To understand MLOPs better, it helps to emphasize the core differences between MLOps and DevOps.
Team composition
DevOps teams are populated mainly by software engineers and system administrators. In contrast, MLOPs teams are more diverse—they must include:
Data scientists and ML researchers in charge of developing machine learning models
Data and software engineer teams providing production-ready solutions
Team members dedicated to communication with stakeholders and business developers. They make sure machine learning products meet business expectations and provide value to their customers.
Data annotators or annotation workforce managers who label training datasets and review their quality
Scoping
Scoping entails the preparation for the project. Before starting, you must decide if a given problem requires a machine learning solution—and if it does, what kind of machine learning models are suitable. Are datasets available or need to be gathered? Are they representative of reality or biased? What tradeoffs need to be respected (e.g., precision vs. inference speed)? Which deployment method fits the best? A machine learning operations team needs to address these issues and plan a project’s roadmap accordingly.
Versioning and Reproducibility
Being able to reproduce models, results, and even bugs is essential in any software development project. Using code versioning tools is a must.
However, in machine learning and data science, versioning of datasets and models is also essential. You must ensure your datasets and models are tied to specific code versions.
Open source data versioning tools such as DVC or MLOPs platforms are crucial to any machine learning operations pipeline. In contrast, DevOps pipelines rarely need to deal with data or models.
Testing
The MLOps community adopted all the basic principles of the unit and integration testing from DevOps.
However, the MLOPs pipeline must also include tests for both model and data validation. Ensuring the training and serving data are in the correct state to be processed is essential. Moreover, model tests guarantee that deployed models meet the expected criteria for success.
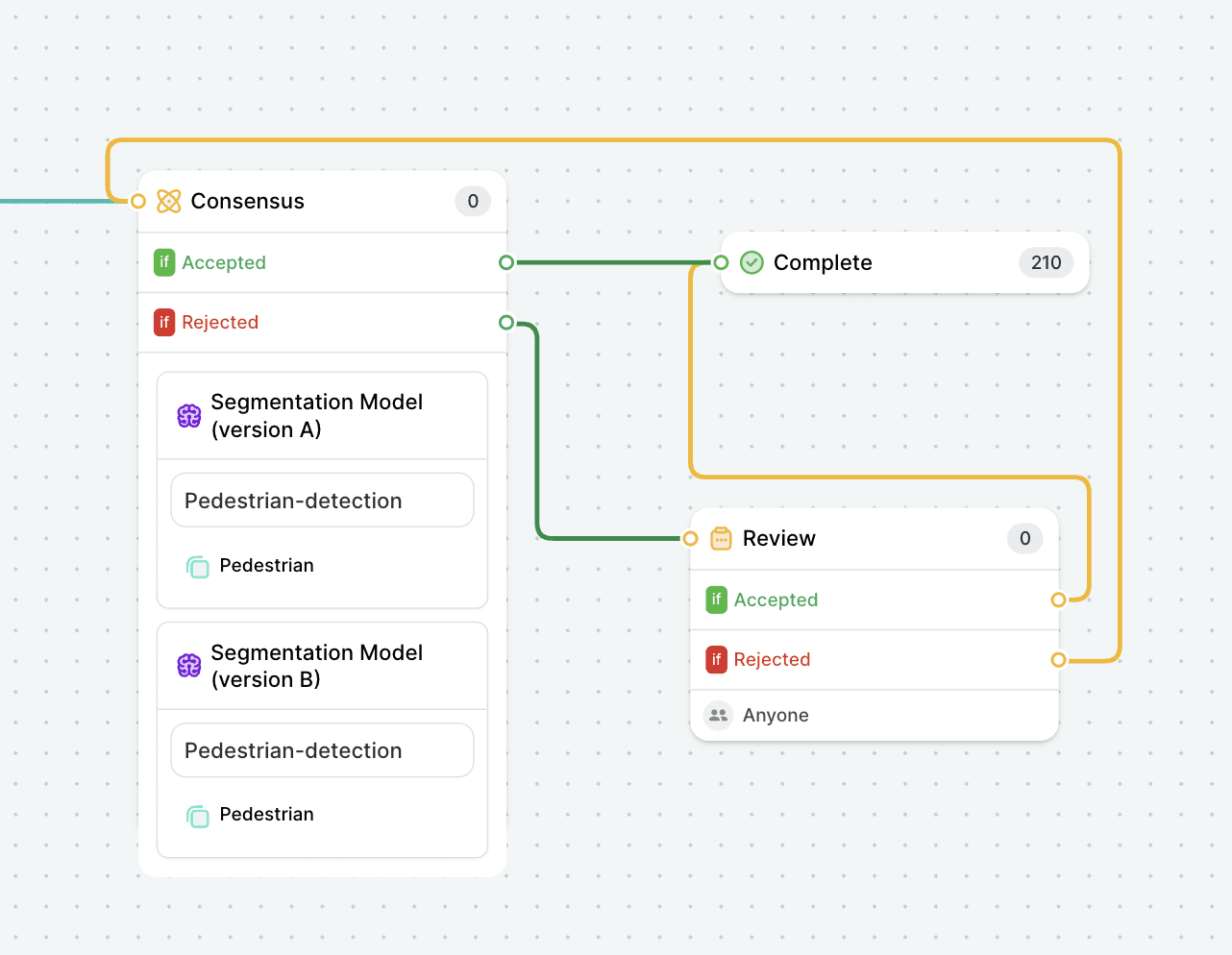
The example above shows an automated ML workflow that compares the performance of two versions of an object detection model. If the results are not overlapping, a data scientist can review them to gather insights.
Pro tip: Learn more about handling ML data in our guide to data preprocessing
Deployment
Deploying offline-trained models as a prediction service is rarely suitable for most ML products. Multi-step ml pipelines responsible for retraining and deployment must be deployed instead. This complexity requires automation of previously manual tasks performed by data scientists.
Monitoring
Model evaluation needs to be a continuous process. Not unlike food and other products, machine learning models have expiration dates. Seasonality and data drifts can degrade the performance of a live model. Ensuring production models are up-to-date and on par with the anticipated performance is crucial.

MLOps pipelines must include automated processes that frequently evaluate models and trigger retraining processes when necessary. This is an essential step to implementing machine learning feedback loops. For example, in computer vision tasks Mean Average Precision can be used as one of the key metrics.
Why do we need machine learning ops?
Implementing MLOPs benefits your organization's machine learning system in the following ways:
Reproducibility: You can accurately reproduce results and bugs.
Debugging: ML pipelines are notoriously challenging to debug. Many components may fail, and bugs are often extremely subtle. MLOPs makes debugging more straightforward.
Efficiency: ML needs plenty of iterations. With MLOPs present, iterations are swifter due to the lack of manual processes.
Deployment: Automated, rapid, fault-tolerant model and pipeline deployment.
Model quality: In addition to swifter training cycles, data drift monitoring and model retraining aid the improvement of machine learning models while in production.
Scalability: With most processes automated and well documented, it’s easier to train more models and serve more requests.
Fault tolerance: CI/CD pipelines as well as unit and model testing decrease the probability of a failing product/service reaching production.
Research: With most menial tasks taken care of by software, data scientists and machine learning researchers have more time to model R&D. Moreover, CI/CD pipelines foster innovation due to quicker experimentation.
Pro tip: Check out how you can manage all your data with V7.
What are some of the MLOps challenges?
Since the field is relatively young and best practices are still being developed, organizations face many challenges in implementing MLOPs. Let’s go through three main challenge verticals.
Organizational challenges
The current state of ML culture is model-driven. Research revolves around devising intricate models and topping benchmark datasets, while education focuses on mathematics and model training. However, the ML community should devote some of its attention to training on up-to-date open-source production technologies.
Adopting a product-oriented culture in industrial ML is still an ongoing process that meets resistance, which might make it more difficult to adopt it into an organization seamlessly.
Moreover, the multi-disciplinary nature of MLOPs teams creates friction. Highly specialized terminology across different IT fields and differing levels of knowledge make communication inside hybrid teams difficult. Additionally, forming hybrid teams consisting of data scientists, MLEs, DevOps, and SWEs is very costly and time-consuming.
Architectural and system design challenges
Most machine learning models are served on the cloud with requests by users. Demand may be high during certain periods and fall back drastically during others.
Dealing with a fluctuating demand in the most cost-efficient way is an ongoing challenge. Architecture and system designers also have to deal with developing infrastructure solutions that offer flexibility and the potential for fast scaling.
Operational challenges
Machine learning operations lifecycles generate many artifacts, metadata, and logs. Managing all these artifacts with efficiency and structure is a difficult task.
The reproducibility of operations is still an ongoing challenge. Better practices and tools are being continuously invented.
Best practices for machine learning ops
Let’s go through a few of the MLOPs best practices, sorted by the stages of the pipeline.
Reproducibility
Version code, data, models, and environment dependencies jointly. You should be able to reroll all of them simultaneously if needed. Otherwise, you may not be able to reproduce results.
Version datasets after every manipulation (transformation, feature engineering).
Use environment and dependency managers such as conda, poetry, docker containers, or prebuilt VMs. It will help with package version consistency.
Scoping
Define and track multiple performance measuring metrics. However, the optimization objective should always be simple and easily trackable, at least at the onset. Direct effects, such as the number of user clicks, should be preferred over indirect ones, such as recurrent daily visits.
Data gathering and validation
Arriving data must meet a pre-defined schema.
Data engineers should set up automated processes that transform your data into the required schema and drop or fix corrupted data (ETL tools), especially if data arrives through streaming or other error-prone sources.
Exploratory data analysis (EDA)
Most operations during EDA are shared across datasets. Automate and reuse them whenever possible.
Automate the creation of standard plots.
Store and version control EDA results together with the dataset’s version.
Data prep and feature engineering
Setting up a feature store shared across data teams in the organization can preserve time, and effort and improve the quality of models.
Model training and tuning
Start with a simple explainable model (e.g., logistic regression, random forest) to aid the debugging process. You can then gradually increase complexity.
Use an experiment tracking tool such as MLFlow or another platform that supports tracking, such as V7 to easily explore results.
Make experiments visible to all team members.
Utilize AutoML software to discover optimal models quickly and speed up the fine-tuning process. Try to avoid any manual interference during the MLOPs pipeline.
Model review and governance
Track a model’s lineage and metadata. Log the dataset version it was trained on, the framework used for training, and the environments package versions.
Explore different model storage formats and locate the most suitable depending on your pipeline.
Model deployment and monitoring
Automate the deployment process with CI/CD pipelines. Coordinate deployment tasks according to a directed acyclic graph (DAG) and employ an orchestrator such as AirFlow to execute them.
Launch your first model as quickly as possible and perform numerous iterations. As you develop more features, gather more training data, and learn from past failures, the performance of the deployed models will increase in quality.
Set up processes that detect drifts between the training and serving data. Drifts can severely disrupt model performance.
Model inference and serving
Before fully committing to a new model, use it on a smaller percentage of input serving data (1-10%, depending on traffic) along with the previous prediction method. This is called shadow deployment; it’s the ultimate testing for an ML model, which allows you to switch models safely without severely affecting your service.
Logging a model’s prediction along the model’s version during serving may aid debugging and quality enhancement. Log input data along with predictions (if user data privacy permits it).
Measure the model’s inference time and throughput during testing and QA. Stress test the infrastructure and adjust serving frequency accordingly.
Automated model retraining
Set up monitoring routines that evaluate live models. Sometimes, models perform well during training and testing but underperform in production. All models must be continuously evaluated.
Monitoring routines should trigger retraining scripts if under-performance is detected. Retraining based on the latest, more representative data may improve production performance.
Machine learning ops in practice: How to implement MLOps?
According to Google, there are three levels of MLOPs, depending on the automation scale for each step of the pipeline. Let’s go through each of them.
MLOps level 0 (Manual process)
Level 0 includes setting up a basic machine learning pipeline.
This is the starting point for most practitioners. The workflow is fully manual. If scripts are used, they are often executed and require ad-hoc changes for different experiments. It’s the basic level of maturity and the bare minimum to start building an ML product.
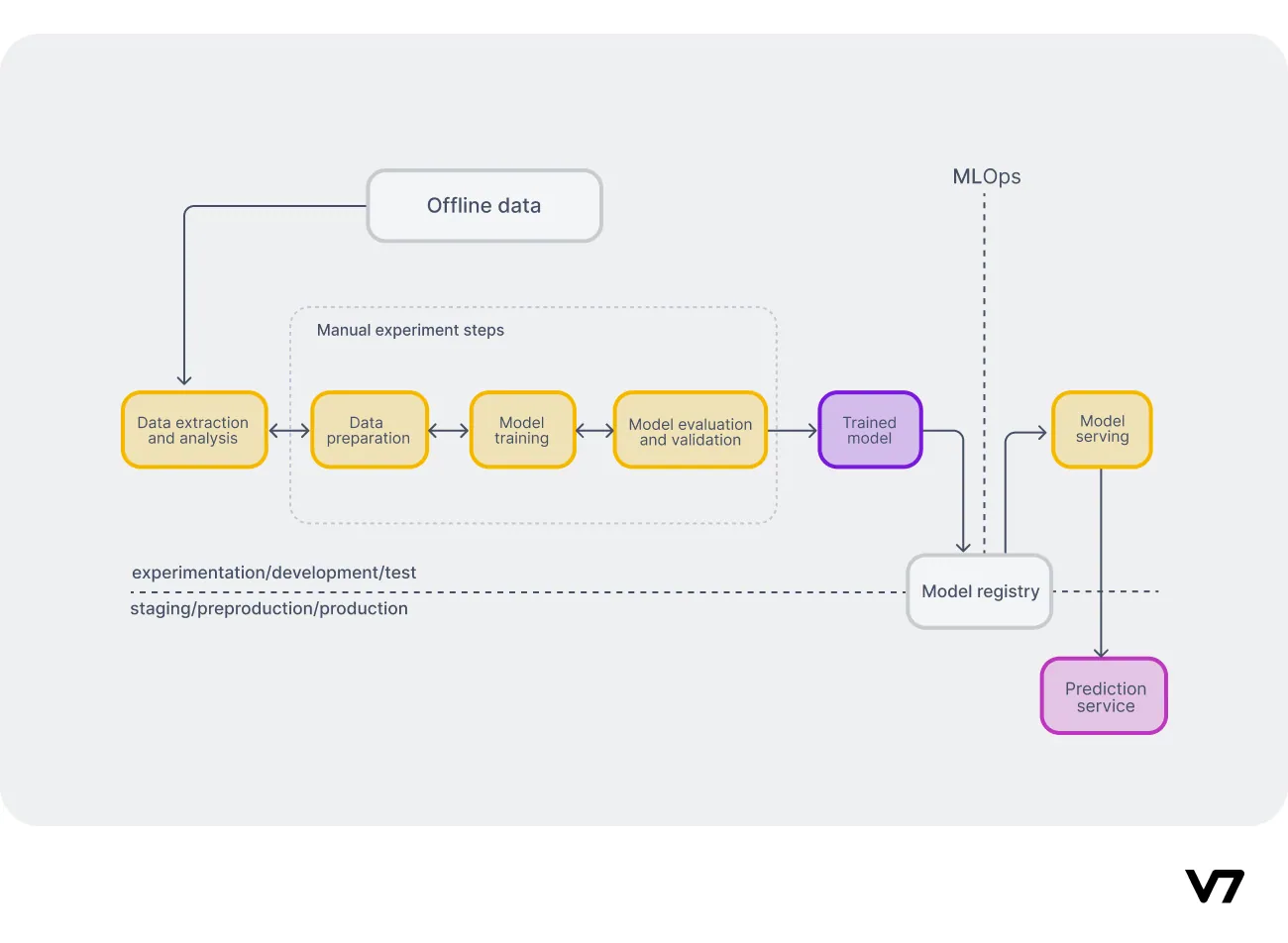
Fig 3: Manual ML pipeline (source)
This manual pipeline takes care of EDA, data preparation, model training, evaluation, fine-tuning, and deployment. Deployment is usually in the form of a simple prediction service API. Logging, model and experiment tracking are either absent or implemented in inefficient ways, such as storage in .csv files.
Suitable for
Researchers and organizations who are just starting with ML use machine learning as a very small part of their product/service. This pipeline may work if models rarely need to be updated.
Traits:
Slow and unpredictable iteration cycles.
Fully manual. This type of pipelines are usually created by data scientists and ML researchers. They are experimental and act as a playground to develop new models. All steps are executed manually, usually in interactive environments such as notebooks. They are slow and error-prone.
Disconnection between data scientists, data engineers, and software engineers causes miscommunication between teams.
Absence of CI/CD pipelines. Due to the infrequent updates, continuous deployment is ignored, while continuous integration tasks, such as testing, are assimilated inside notebooks.
Basic deployment. Only the model is deployed as a prediction service (such as REST API).
Poor logging and debugging capabilities.
Complete absence of model monitoring in production to detect data skew. Feedback loops cannot be implemented.
Few model updates and model improvements.
Failed models can reach and remain in production.
MLOps level 1 (ML pipeline automation)
Any organization that wishes to scale up its machine learning services or requires frequent model updates must implement MLOPs at level 1.
This level solves and automates the process of training ML models through continuous training (CT) pipelines. Orchestrated experiments take care of the training. Feedback loops assure high model quality.
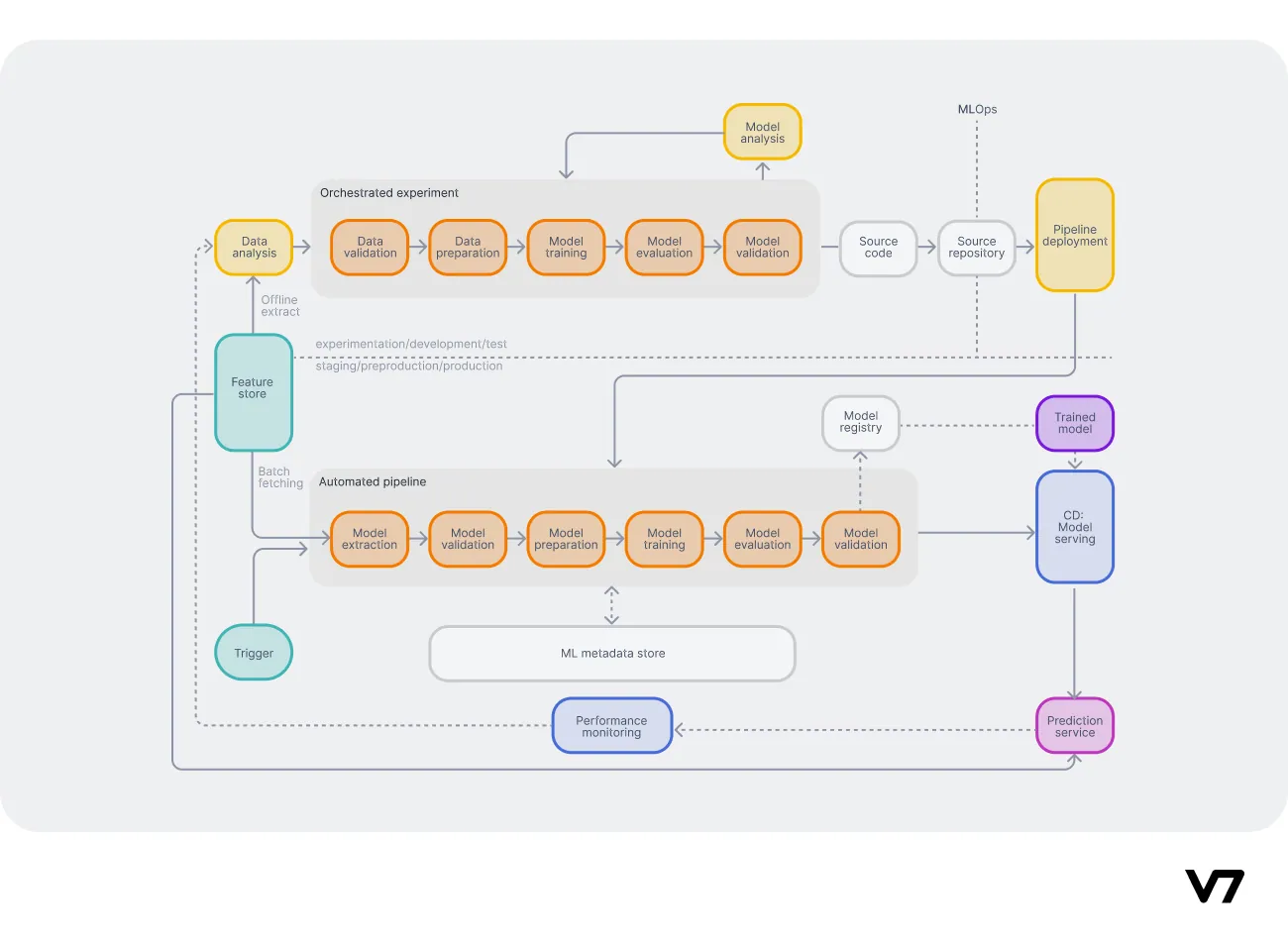
New data is automatically processed and prepared for training. Production models are monitored, and retraining pipelines are triggered upon detecting performance drops are detected. Manual interventions are minimal inside the orchestrated experiments.
Suitable for
Organizations that operate in fast-changing environments, such as trading or media, that must update their models constantly (on a daily or even hourly basis). Moreover, data is often characterized by seasonality, so all trends must be taken into account to ensure high-quality production models.
Traits
Rapid model training. All steps are automated, which allows for faster iterations and more useful models.
Live-model updates. Models in production can be automatically retrained when performance or data drift triggers demand it.
Pipeline deployment. The whole training pipeline is deployed instead of just the model as a prediction service.
Continuous delivery of models. The model deployment step, which serves the trained and validated model as a prediction service for online predictions, is automated.
Data scientists work together with data engineers.
Both training code and models are version controlled.
Basic integration and unit testing are performed.
Model releases are managed by the software engineering team.
To achieve level 1 of MLOPs, you need to set up:
Triggers on performance degradation, schedule, demand, data drift detection and availability of new data.
Solid model validation. Since models are constantly retrained in production, you need to decide which models to reject and which to deploy based on a few solid metrics. Some of the important tests include model evaluation on a test dataset, comparison with the production model, and infrastructure compatibility. Shadow deployment is also another option if the environment permits it.
MLOps level 2 (CI/CD pipeline automation)
Complementing continuous training with CI/CD allows data scientists to rapidly experiment with feature engineering, new model architectures, and hyperparameters. The CI/CD pipeline will automatically build, test, and deploy the new pipeline components.
The whole system is very robust, version controlled, reproducible, and easier to scale up.
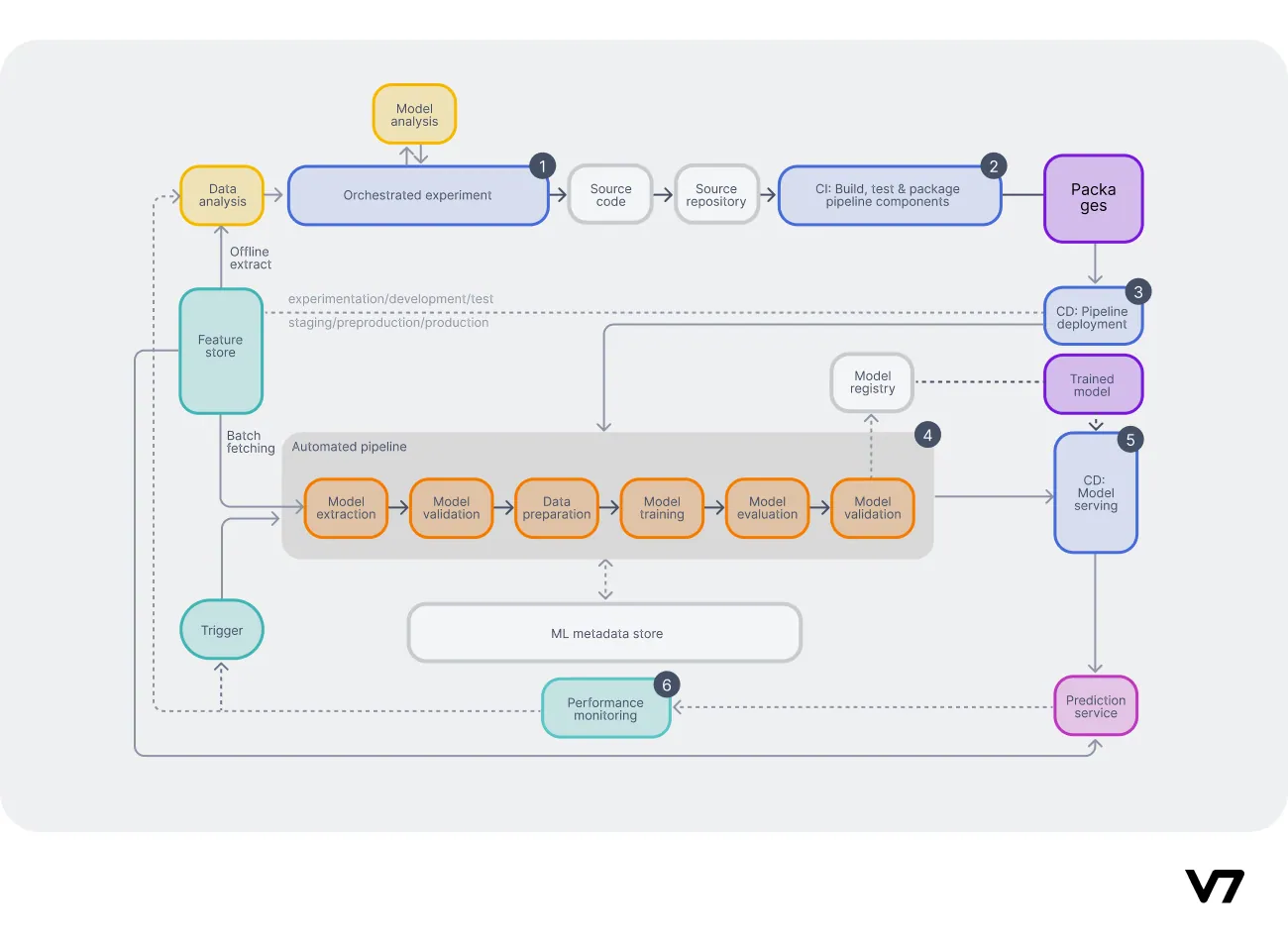
MLOps pipeline with CI/CD/CT implemented (source)
Suitable for
Any organization that bears ML as its core product and requires constant innovation. It allows for rapid experimentation on every part of the ML pipeline while being robust and reproducible.
Traits
MLOPS level 2 builds upon the components introduced in level 2, with the following new core components added:
CI. Continuous integration is responsible for automatically building source code, running tests, and packaging after new code is committed. The result is ML pipeline components ready for deployment. Additionally, it can include tests such as:
Unit testing for feature engineering
Unit testing for different model methods
Testing for NaN values due to division by zero or very small/large values.
Testing if every step creates the expected artifacts (model files, logging files, metadata, etc.).
CD. The role of continuous deployment is two-fold. It consists of Pipeline continuous delivery (fig. 5 #3) and Model continuous delivery (fig. 5 #5). The former deploys the whole pipeline with the new model implemented. The latter serves the model as a prediction service.
Final thoughts
Implementing MLOPs pipelines in your organization allows you to cope with rapid changes in your data and business environment. It fosters innovation and ensures a high-quality ML product. Both small-scale and large-scale organizations should be motivated to set up MLOps pipelines.
Implementing MLOPs pipelines and reaching high MLOPs maturity levels is a gradual process. MLOps pipelines can be built using open-source tools, but since the cost and time investment are high, exploring platform MLOPs solutions is usually a good idea.
Ready to start? Build robust ML pipelines and deploy reliable AI faster with V7.
Konstantinos Poulinakis is a machine learning researcher and technical blogger. He has an M.Eng. in Electrical & Computer Engineering and an M.Sc.Eng in Data Science and Machine Learning from NTUA. His research interests include self-supervised and multimodal learning.