Playbooks
How to Use V7 Masks for Semantic Segmentation
6 min read
—
Aug 16, 2023
Unlock the potential of masks in V7 to achieve precise pixel-level labeling and semantic segmentation. Find out to increase annotation accuracy and simplify the editing process.

Content Creator
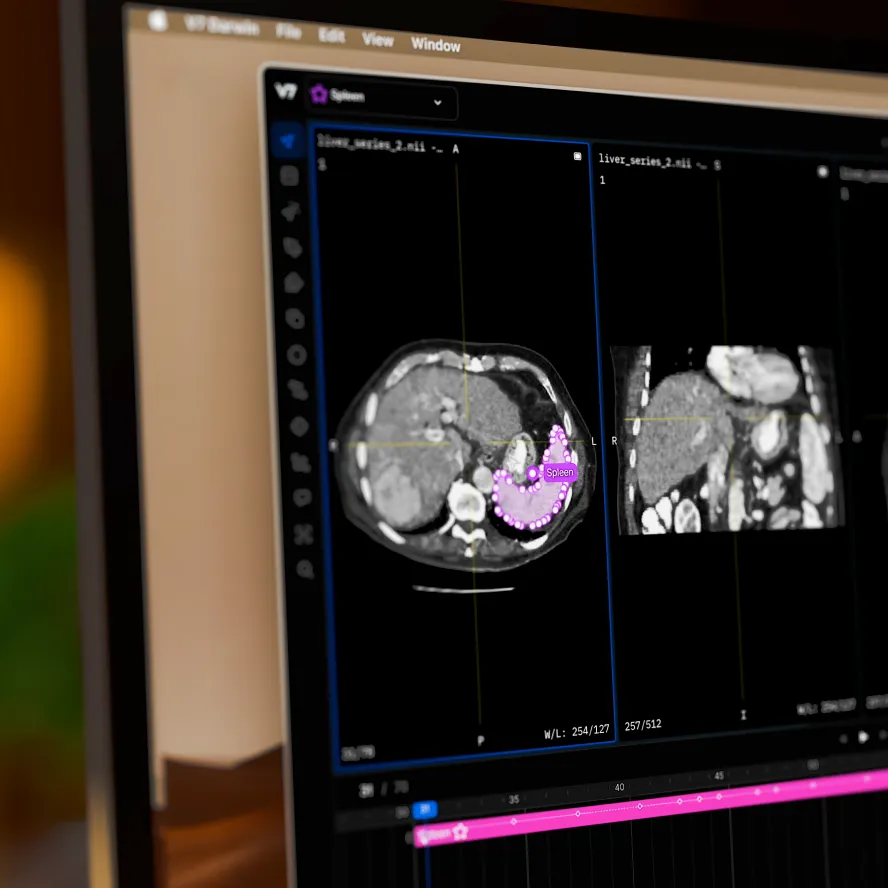
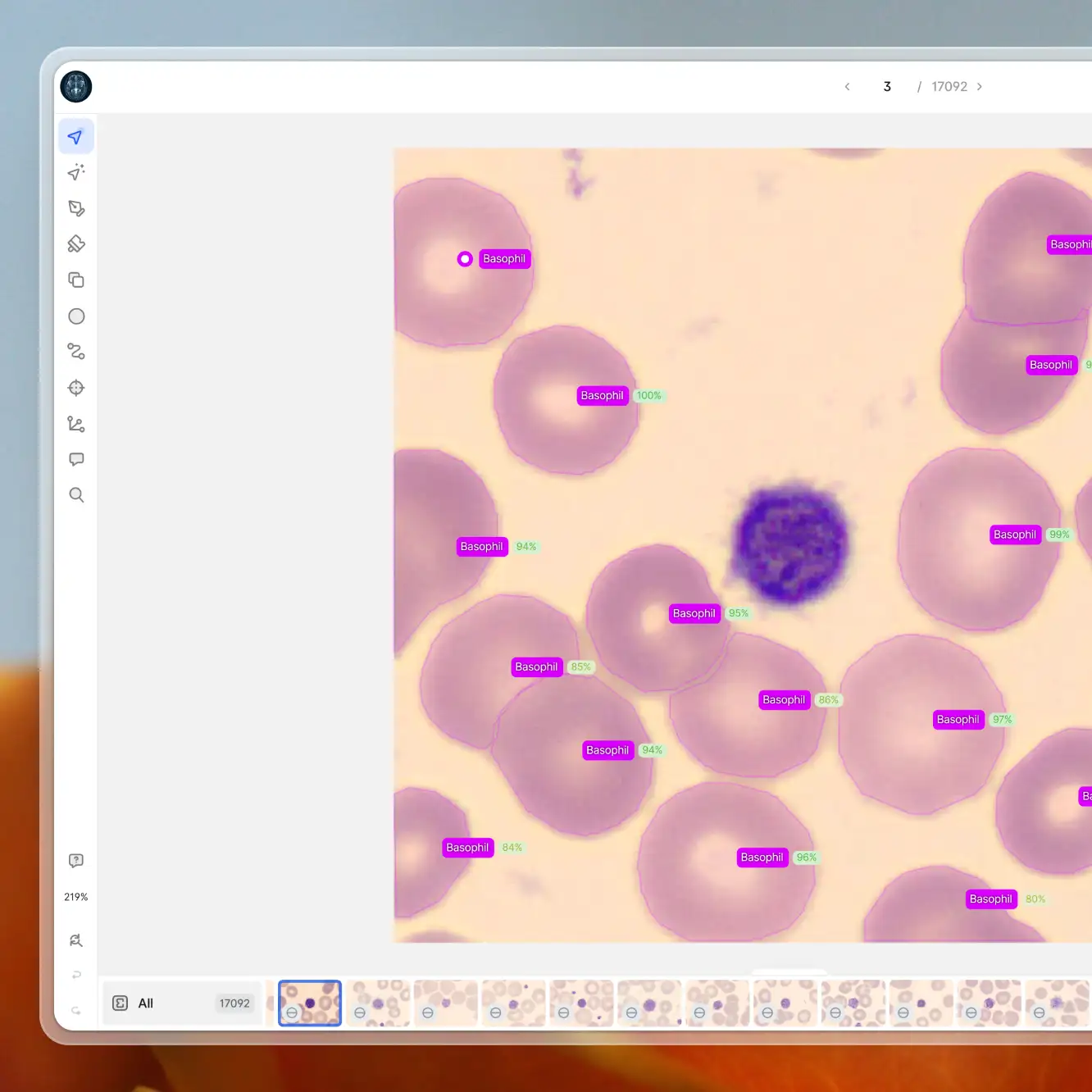
You can now use V7 to create semantic masks. This new class type allows you to create pixel-perfect labels and determine the identity of individual pixels, which is essential for semantic segmentation tasks.
Your masks will appear as a separate layer. You can also add other types of annotations, such as polygons, on top of your semantic masks. Combining different classes and attributes with your masks may be useful if your use case requires panoptic segmentation.
Benefits of using masks for image and video annotation
The choice between polygon and mask annotations will depend on the specific requirements of your project. However, semantic masks offer some substantial benefits:
Increase the accuracy of annotations. Annotations made using masks are less likely to be ambiguous or inaccurate. You can adjust them on a pixel level and each pixel can have only one identity.
Enable semantic and panoptic segmentation. Semantic raster masks are great for categorizing different areas of images, providing more context for your models.
Greater ease of editing annotations. V7 offers many tools, like the Brush Tool, that allow for quick and easy editing of mask annotations. You can paint over objects or erase unwanted areas with no need to outline them. This not only saves you time, but also makes the editing process more intuitive.
What is the difference between polygons and masks?
Polygon annotations outline shapes of objects using vector coordinates at essential points. Masks, on the other hand, are more like a digital paint-by-numbers. They operate on a pixel level, determining the identity of each individual pixel in the image.
Polygon annotation
Polygon annotations are ideal for instance segmentation tasks in which multiple items or people need to be identified. They enable the outlining of complex shapes that can be analyzed as separate objects.

Mask annotation
Masks are ideal for semantic segmentation tasks that require the categorization of different areas within an image (e.g., sky vs. water vs. land vs. forest). They provide precise and unambiguous data.

Semantic masks are based on rasters and they focus on pixel identity. Therefore, in typical semantic segmentation, all cars would be labeled as 'car' without differentiating between individual vehicles. In the above example, there are separate polygon instances of the 'pallet' class, but the mask represents one 'load' area.
It also means each pixel can only belong to one mask at a time, and different semantic masks can't overlap. You cannot create separate instance IDs with attributes for objects annotated as a mask in one image. Another point worth noting is that these annotations can be a bit heavier in terms of annotation JSON weight.
⚠️ Mask annotations do not allow for overlapping classes. Each pixel can only belong to one class at a time.
How to use masks
As previously mentioned, masks focus on the identity of specific pixels. For example, training a model for an autonomous vehicle may require much more than merely detecting or counting tree instances. It's about teaching the model to read the environment: are we surrounded by buildings in a city or foliage in a forest?
This level of understanding requires semantic segmentation, which involves counting pixels for specific classes recorded by the car's camera.
Semantic segmentation with V7 masks is a little bit like coloring each pixel in an image according to what object it belongs to. These annotations provide a comprehensive, pixel-level understanding of an image.
Here's a simple step-by-step guide on how to add and use masks in V7:
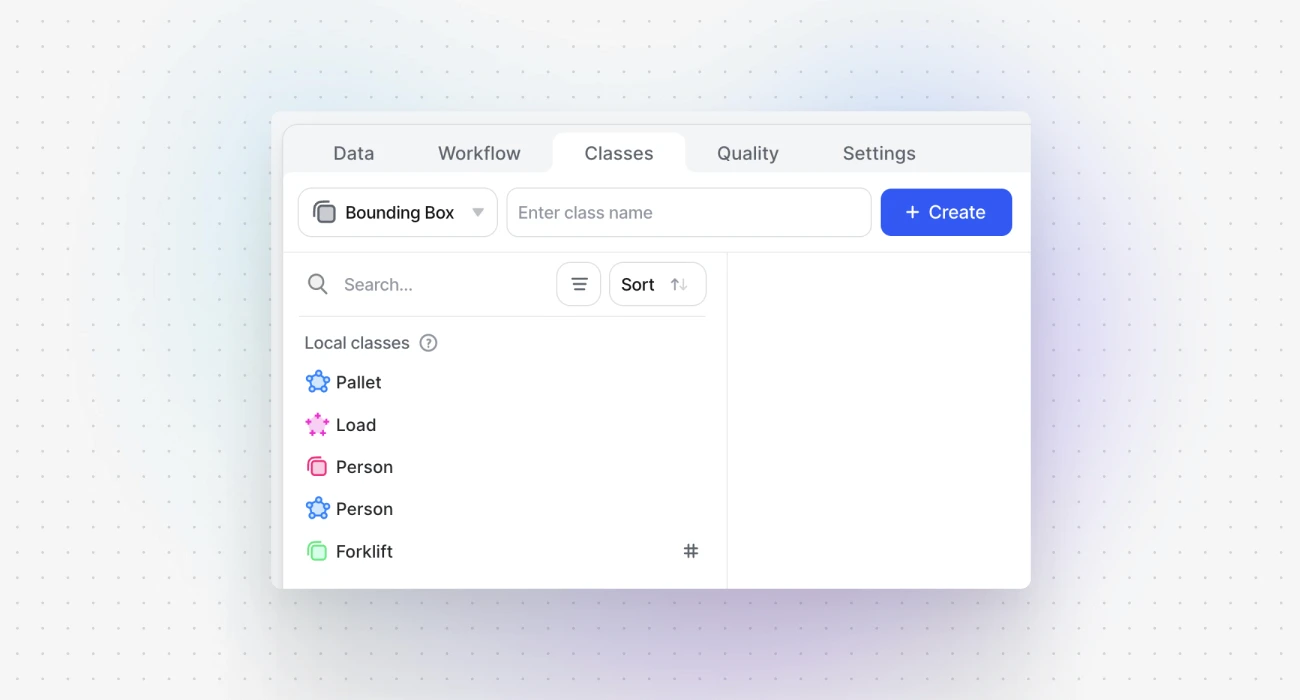
Step 1: Create a new mask annotation class
You can manage your classes in multiple places. In the updated version of the class management tab, you can create new classes and include them in or exclude them from your datasets. Make sure that the class is available when using tools like the Polygon Tool or the Brush Tool.
Step 2: Draw an area that should be included in the mask
Mask annotations use the same tools as polygons. For example, you can use the Polygon Tool to draw your shape, and as soon as you're done, the pixels become part of the semantic mask.
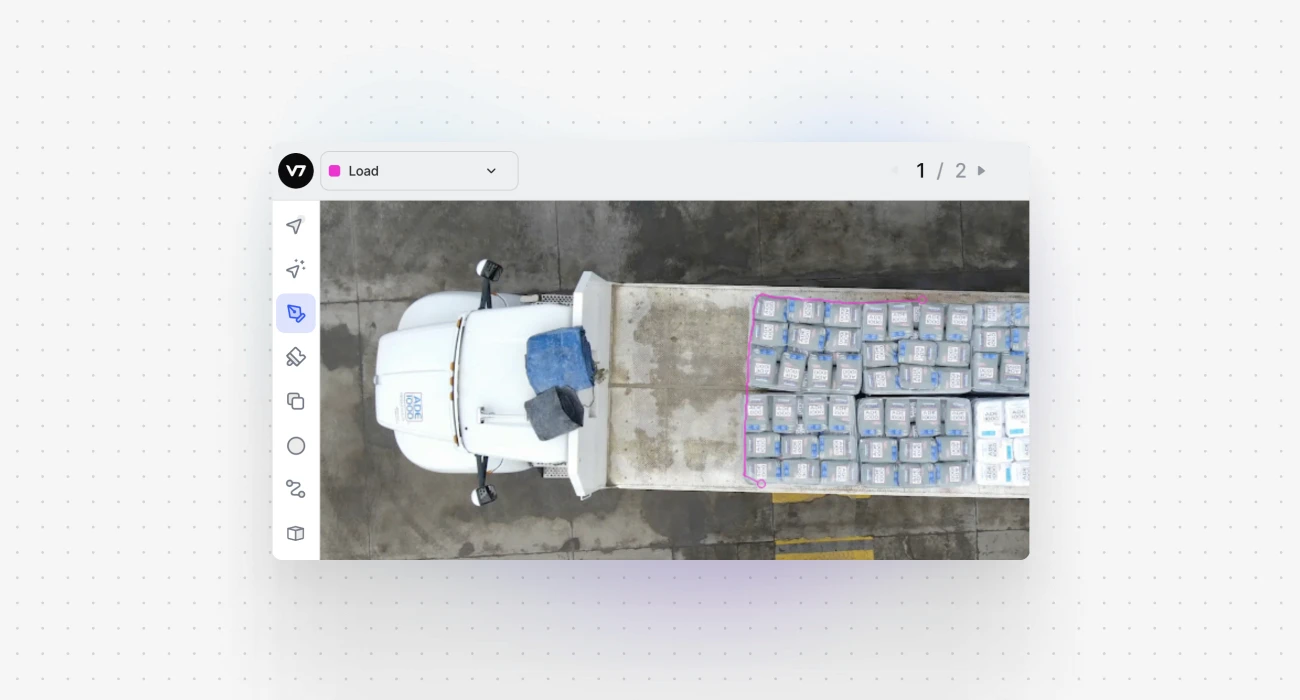

Note that they're added as a separate layer—your image’s objects and masks are available as independent, overlaying elements.
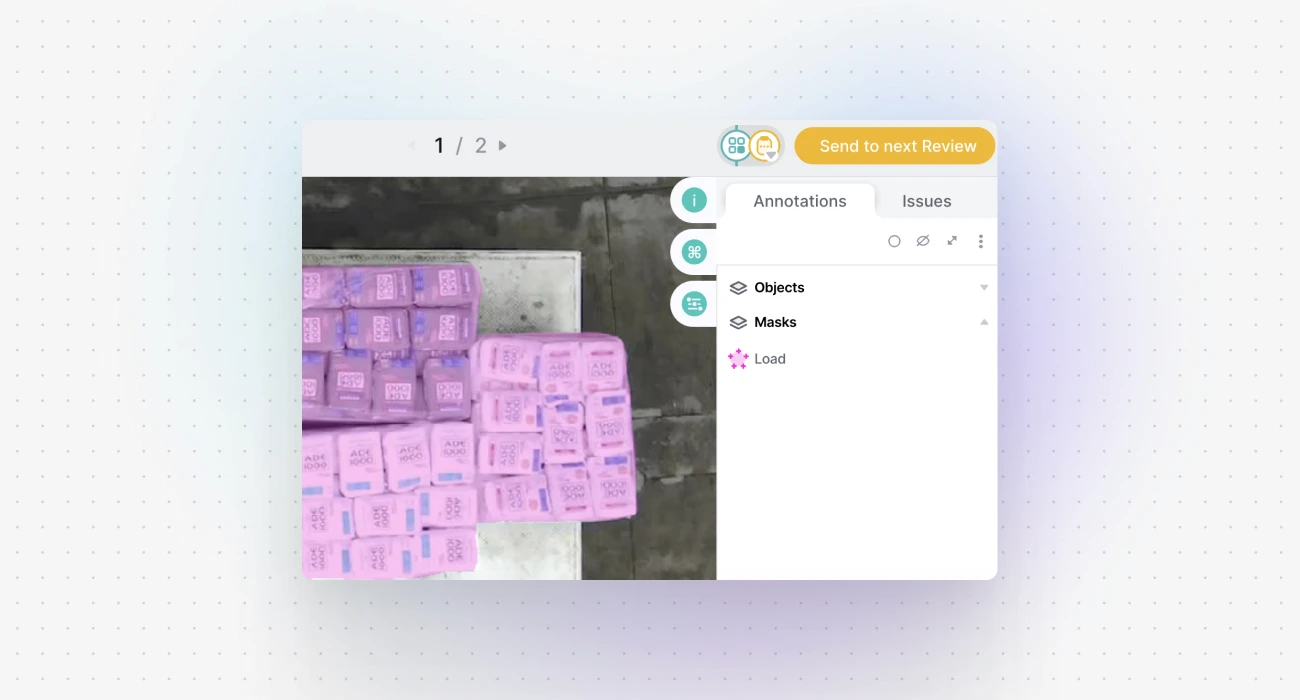
Step 3: Add or erase parts of your annotation
Once a mask is created, its outlines are not editable the way polygons are. However, you can easily refine them with a brush tool to add or remove pixels from your mask.
Semantic annotations available in V7 are binary masks, which means that a pixel can either be a part of a given class or not. It cannot be partially one thing and partially something else. If we paint over a mask with a different mask class, the pixels will be assigned a new "identity" and will no longer belong to the previous annotation.
⚠️ Masks can be used with videos and image series. However, automatic interpolation between frames is not supported for this class type. Also, please note that there is a new field on the video timeline called masks.
Step 4: Export annotations
You can export your annotations by saving them as Darwin JSON files or by sending the payload through a Webhook Stage.
Now, if we exported mask and polygon annotations as JSON files, the difference between them becomes clear. With polygons we get x, y coordinates for the points outlining the shape of an object.
Polygon annotations
Mask annotations
With masks, the information is encoded with RLE (Run-Length Encoding) as an array of values for all pixels of the image. Essentially, it looks like this: 1165581 consecutive pixels that don’t belong to the mask, followed by 78 pixels that belong to the mask, followed by 2319 that don’t belong to the mask, followed by 89 pixels that belong to the mask, and so on.
With one mask we only get 0 and 1, but if our 'Masks' layer included three mask classes, we would get values like 0 = no mask, 1 = the first mask, 2 = the second mask, 3 = the third mask. We can add multiple classes but observe that with this JSON schema a series of pixels will be always assigned just one of the values.
⚠️ Masks only support Darwin JSON V2 exports. Please ensure that you have selected the correct export format when working with semantic masks.
Use cases for semantic masks
Raster-based masks are widely used in various fields where detailed image segmentation is required. Here are a few examples:
Agriculture. Masks combined with aerial imagery provide granular crop monitoring. This assists in disease detection, crop health assessment, yield prediction, and efficient irrigation system planning.
Remote Sensing and Geospatial Analytics. Masks can help differentiate various types of landscapes and terrains, such as forests, mountains, bodies of water, and more. This level of detail is critical in remote sensing and geospatial analytics for better understanding the Earth's surface.
Autonomous Vehicles. Autonomous driving relies heavily on accurately recognizing and understanding the vehicle's environment. Semantic masks can provide detailed information about the road, sidewalks, pedestrians, and other elements, helping to train more sophisticated self-driving models.
Medical Imaging. In medical imaging, doctors and scientists use raster masks to differentiate between tissues, cells, and other biological structures. This can aid in the diagnosis and treatment of various medical conditions.
The addition of mask annotations in V7 introduces another powerful feature to your computer vision toolkit. With their high precision and detail, they are set to enhance the quality and accuracy of semantic segmentation tasks across various industries and use cases.
Read more: V7 documentation