Data labeling
Data Cleaning Checklist: How to Prepare Your Machine Learning Data
10 min read
—
Sep 16, 2021

What is data cleaning and how to do it properly? Learn what steps you need to take to prepare your machine learning data and start building reliable machine learning models today.

Guest Author
Garbage in, garbage out.
This saying should become your mantra if you are serious about building accurate machine learning models that find real-world applications.
And here's some food for thought—
Quality data beats even the most sophisticated algorithms.
Without clean data, your models will deliver misleading results and seriously harm your decision-making processes. You'll end up frustrated (been there, done that!), and it's simply not worth it.
Instead, let us walk you step-by-step through the data cleaning process.
Here’s what we’ll cover:
What is data cleaning?
The importance of data cleaning
Data cleaning vs. data transformation
5 characteristics of quality data
How to clean data for Machine Learning
What is data cleaning?
Data cleaning is the process of preparing data for analysis by weeding out information that is irrelevant or incorrect.
This is generally data that can have a negative impact on the model or algorithm it is fed into by reinforcing a wrong notion.
Data cleaning not only refers to removing chunks of unnecessary data, but it’s also often associated with fixing incorrect information within the train-validation-test dataset and reducing duplicates.
The importance of data cleaning
Data cleaning is a key step before any form of analysis can be made on it.
Datasets in pipelines are often collected in small groups and merged before being fed into a model. Merging multiple datasets means that redundancies and duplicates are formed in the data, which then need to be removed.
Also, incorrect and poorly collected datasets can often lead to models learning incorrect representations of the data, thereby reducing their decision-making powers.
It's far from ideal.
The reduction in model accuracy, however, is actually the least of the problems that can occur when unclean data is used directly.
Models trained on raw datasets are forced to take in noise as information and this can lead to accurate predictions when the noise is uniform within the training and testing set—only to fail when new, cleaner data is shown to it.
Data cleaning is therefore an important part of any machine learning pipeline, and you should not ignore it.
Data cleaning vs. data transformation
As we’ve seen, data cleaning refers to the removal of unwanted data in the dataset before it’s fed into the model.
Data transformation, on the other hand, refers to the conversion or transformation of data into a format that makes processing easier.
In data processing pipelines, the incoming data goes through a data cleansing phase before any form of transformation can occur. The data is then transformed, often going through stages like normalization and standardization before further processing takes place.
Check out A Simple Guide to Data Preprocessing in Machine Learning to learn more.
5 characteristics of quality data
Data typically has five characteristics that can be used to determine its quality.
These five characteristics are referred to within the data as:
Validity
Accuracy
Completeness
Consistency
Uniformity
Besides checking up on these generic characteristics, there are still other specialized methods that data scientists and data engineers use to check the quality of their data.
Validity
Data collection often involves a large group of people presenting their details in various forms (including phone numbers, addresses, and birthdays) in a document that is stored digitally.
Modern methods of data collection find validity an easy-to-maintain characteristic as they can control the data that is being entered into digital documents and forms.
Typical constraints applied on forms and documents to ensure data validity are:
Data-type constraints: Data-type constraints help prevent inconsistencies arising due to incorrect data types in the wrong fields. Typically, these are found in fields like age, phone number, and name where the original data is constrained to contain only alphabetical or numerical values.
Range constraints: Range constraints are applied in fields where prior information about the possible data is already present. These fields include—but are not limited to—date, age, height, etc.
Unique constraints: Unique constraints are ones that update themselves each time a participant enters data into the document or form. This type of constraint prevents multiple participants from entering the same details for parameters that are supposed to be unique. Generally, these constraints are activated at fields like social security number, passport number, and username.
Foreign key constraints: Foreign Key constraints are applicable to fields where the data can be limited to a set of previously decided keys. These fields are typically country and state fields where the range of information that can be provided is easily known beforehand.
Cross-field validation: Cross-field validation is more of a check than a constraint to make sure that multiple fields in the document correspond to each other. For example, if the participant enters a group of values that should come to a particular number or amount, that amount serves as a validator that stops the participant from entering the wrong values.
Accuracy
Accuracy refers to how much the collected data is both feasible and accurate. It’s almost impossible to guarantee perfectly accurate data, thanks to the fact that it contains personal information that’s only available to the participant. However, we can make near-accurate assumptions by observing the feasibility of that data.
Data in the form of locations, for example, can easily be cross-checked to confirm whether the location exists or not, or if the postal code matches the location or not. Similarly, feasibility can be a solid criterion for judging. A person cannot be 100 feet tall, nor can they weigh a thousand pounds, so data going along these lines can be easily rejected.
See 20+ Open Source Computer Vision Datasets to find quality data for your Computer Vision project ideas.
Completeness
Completeness refers to the degree to which the entered data is present in its entirety.
Missing fields and missing values are often impossible to fix, resulting in the entire data row being dropped. The presence of incomplete data, however, can be appropriately fixed with the help of proper constraints that prevent participants from filling up incomplete information or leaving out certain fields.
Consistency
Consistency refers to how the data responds to cross-checks with other fields. Studies are often held where the same participant fills out multiple surveys which are cross-checked for consistency. Cross checks are also included for the same participant in more than a single field.
Check out our Data Annotation Guide to learn more.
How to clean data for Machine Learning?
As research suggests—
Data cleaning is often the least enjoyable part of data science—and also the longest.
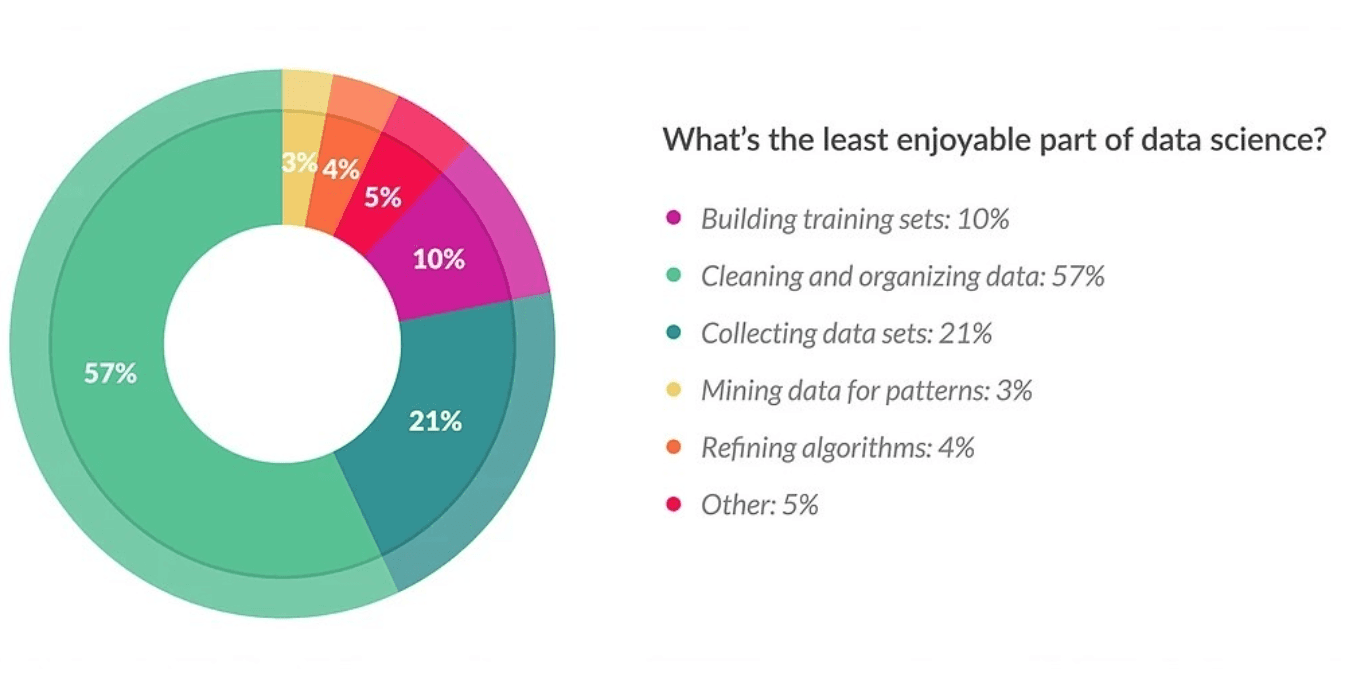
Indeed, cleaning data is an arduous task that requires manually combing a large amount of data in order to:
a) reject irrelevant information.
b) analyze whether a column needs to be dropped or not.
Automation of the cleaning process usually requires a an extensive experience in dealing with dirty data. It’s kinda tricky to implement in a manner that doesn’t bring about data loss.
Remove duplicate or irrelevant data
Data that’s processed in the form of data frames often has duplicates across columns and rows that need to be filtered out.
Duplicates can come about either from the same person participating in a survey more than once or the survey itself having multiple fields on a similar topic, thereby eliciting a similar response in a large number of participants.
While the latter is easy to remove, the former requires investigation and algorithms to be employed. Columns in a data frame can also contain data highly irrelevant to the task at hand, resulting in these columns being dropped before the data is processed further.
Fix syntax errors
Data collected over a survey often contains syntactic and grammatical issues, due mainly to the fact that a huge demographic is represented through it. Common syntax issues like date, birthday and age are simple enough to fix, but syntax issues involving spelling mistakes require more effort.
Algorithms and methods which find and fix these errors have to be employed and iterated through the data for the removal of typos and grammatical and spelling mistakes.
Syntax errors, meanwhile, can be prevented altogether by structuring the format in which data is collected, before running checks to ensure that the participants have not wrongly filled in known fields. Setting strict boundaries for fields like State, Country, and School goes a long way to ensuring quality data.
Filter out unwanted outliers
Unwanted data in the form of outliers has to be removed before it can be processed further. Outliers are the hardest to detect amongst all other inaccuracies within the data.
Thorough analysis is generally conducted before a data point or a set of data points can be rejected as an outlier. Specific models that have a very low outlier tolerance can be easily manipulated by a good number of outliers, therefore bringing down the prediction quality.
Handle missing data
Unfortunately, missing data is unavoidable in poorly designed data collection procedures. It needs to be identified and dealt with as soon as possible. While these artifacts are easy to identify, filling up missing regions often requires careful consideration, as random fills can have unexpected outcomes on the model quality.
Often, rows containing missing data are dropped as it’s not worth the hassle to fill up a single data point accurately. When multiple data points have missing data for the same attributes, the entire column is dropped. Under completely unavoidable circumstances and in the face of low data, data scientists have to fill in missing data with calculated guesses.
These calculations often require observation of two or more data points similar to the one under scrutiny and filling in an average value from these points in the missing regions.
Validate data accuracy
Data accuracy needs to be validated via cross-checks within data frame columns to ensure that the data which is being processed is as accurate as possible. Ensuring the accuracy of data is, however, hard to gauge and is possible only in specific areas where a predefined idea of the data is known.
Fields like countries, continents, and addresses can only have a set of predefined values that can be easily validated against. In data frames constructed from more than a single source/survey, cross-checks across sources can be another procedure to validate data accuracy.
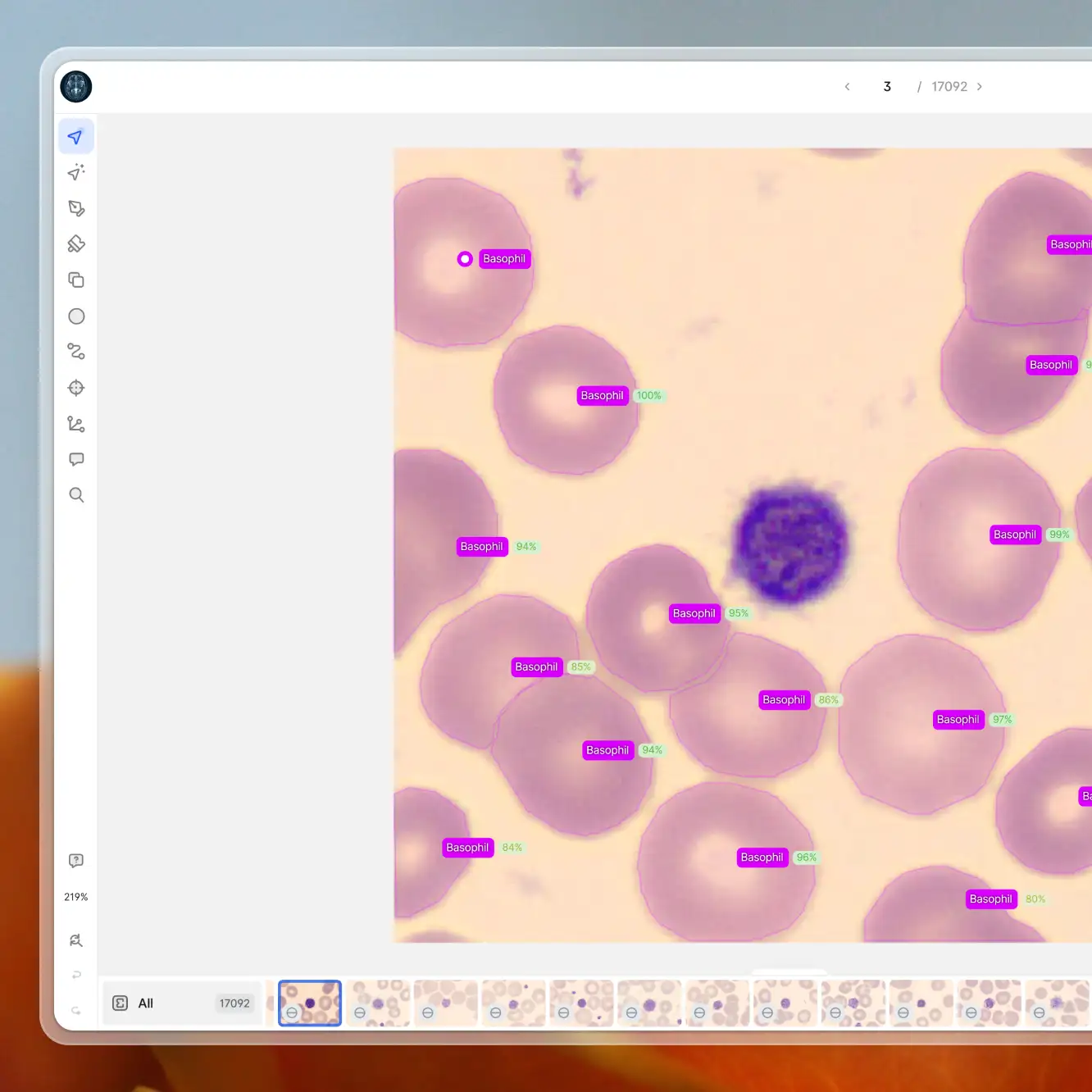
V7 allows you to clean and manage data easily with a super-intuitive user interface. Have a look at how you can annotate your data with V7.
Have a look at our list of the 13 Best Image Annotation Tools to find a labeling tool that suits your needs.
Data Cleaning best practices: Key Takeaways
Data Cleaning is an arduous task that takes a huge amount of time in any machine learning project. It is also the most important part of the project, as the success of the algorithm hinges largely on the quality of the data.
Here are some key takeaways on the best practices you can employ for data cleaning:
Identify and drop duplicates and redundant data
Detect and remove inconsistencies in data by validating with known factors
Maintain a strict data quality measure while importing new data.
Fix typos and fill in missing regions with efficient and accurate algorithms
Read more:
Optical Character Recognition: What is It and How Does it Work [Guide]
Computer Vision: Everything You Need to Know
A Gentle Introduction to Image Segmentation for Machine Learning and AI
Data Annotation Tutorial: Definition, Tools, Datasets
The Ultimate Guide to Semi-Supervised Learning
The Beginner’s Guide to Contrastive Learning
9 Reinforcement Learning Real-Life Applications
Mean Average Precision (mAP) Explained: Everything You Need to Know
Hmrishav Bandyopadhyay studies Electronics and Telecommunication Engineering at Jadavpur University. He previously worked as a researcher at the University of California, Irvine, and Carnegie Mellon Univeristy. His deep learning research revolves around unsupervised image de-warping and segmentation.